ceph中最常用的命令就是ceph -s。
我们通过ceph -s中显示的结果如下:
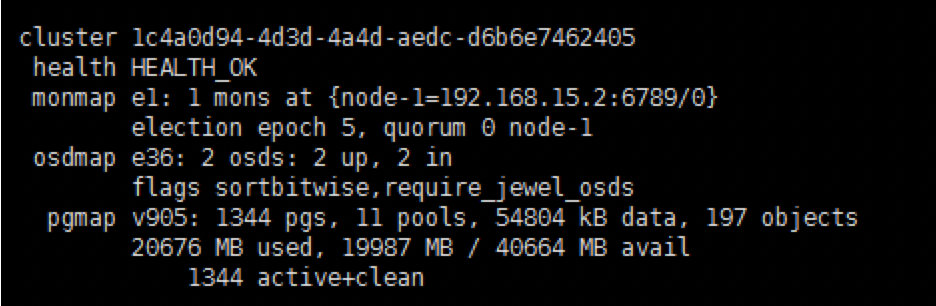
但是有时侯也会有这种情况:
那么下面这些PG的状态都是什么意思呢?
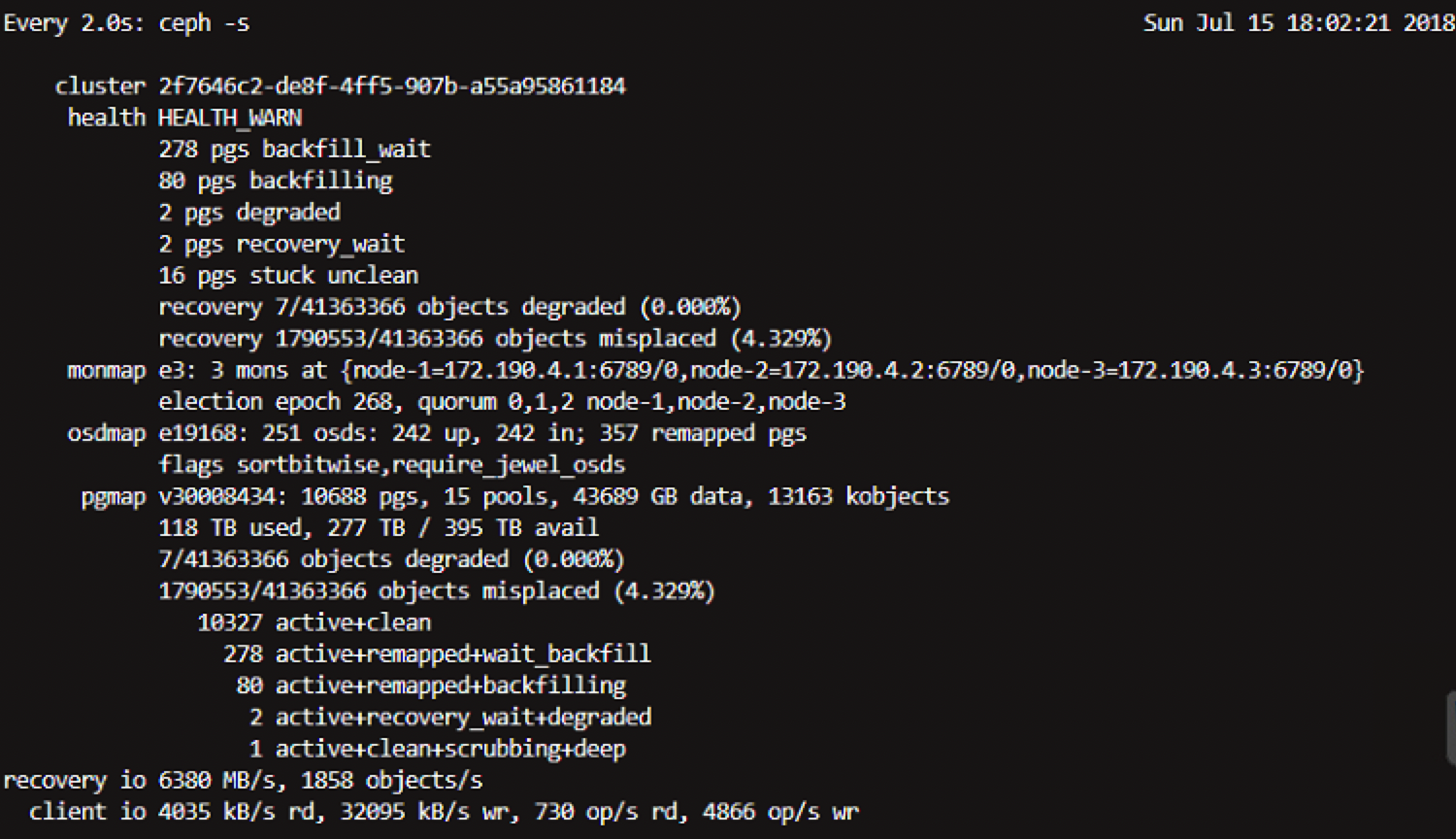
ceph -s 能够非常直观看到pg的状态,pg是数据存储的重要单位,在使用ceph的时候,pg会经常发生状态的变化,参考下面例子。 1. 当创建 pool 的时候,将会创建相应的 pg,那么可以看到pg creating状态。 2. 当部分 pg 创建成功后,将会发现 pg 会进入到 peering 状态。 3. 当所有 pg peering 完成后,将可见到状态变成 active+clean。
常见的PG状态:
常见的pg状态: creating :创建中 down :PG处于失效状态,PG处于离线状态 repair (修复):PG正在被检查,被发现的任何不一致都将尽可能的被修复。 peering(等待互联): 1. 当ceph peering pg, ceph 将会把 pg 副本协定导入 osd, 当 ceph 完成 peering, 意味着 osd 同意当前 PG 状态, 并允许写入 2. PG处于 peering 过程中, peering 由主 osd 发起的使存放 PG 副本的所有 OSD 就 PG 的所有对象和元素数据的状态达成一致的过程, peering 过程完成后, 主 OSD 就可以接受客户端写请求. active: 1. 当 ceph 完成 peering 过程, pg 将会变成 active, active 状态意味着 pg 中的数据变得可用, 主 pg 将可执行读写操作 2. PG 是活动的, 意味着 PG 中的数据可以被读写, 对该 PG 的操作请求都讲会被处理. clean: 干净态。PG当前不存在待修复的对象, Acting Set和Up Set内容一致,并且大小等于存储池的副本数 replay(重做):某OSD崩溃后,PG正在等待客户端重新发起操作。 degraded(降级): 1. 当客户端写对象到主 osd, 主 OSD 会把数据写复制到对应复制 OSD, 在主 OSD 把对象写入存储后, PG 会显示为 degraded 状态, 直到主 osd 从复制 OSD 中接收到创建副本对象完成信息 2. PG 处于 active+degraded 原因是因为 OSD 是处于活跃, 但并没有完成所有的对象副本写入, 假如 OSD DOWN, CEPH 标记每个 PG 分配到这个相关 OSD 的 状态为 degraded, 当 OSD 重新上线, OSD 将会重新恢复, 3. 假如 OSD DOWN 并且 degraded 状态持续, CEPH 会标记 DOWN OSD, 并会对集群迁移相关 OSD 的数据, 对应时间由 mon osd down out interval 参数决定 4. PG 可以被北极为 degraded, 因为 ceph 在对应 PG 中无法找到一个或者多个相关的对象, 你不可以读写 unfound 对象, 你仍然可以访问标记为 degraded PG 的其他数据 5. PG 中部分对象的副本数量未达到规定的数量 inconsistent(不一致):PG副本出现不一致, 对象大小不正确或者恢复借宿后某个副本出现对象丢失现象 recoverying(恢复中): ceph 设备故障容忍在一定范围的软件与硬件问题, 当 OSD 变 DOWN, 那么包含该 OSD 的 PG 副本都会有问题, 当 OSD 恢复, OSD 对应的 PG 将会更新 并反映出当前状态, 在一段时间周期后, OSD 将会恢复 recoverying 状态 recovery 并非永远都有效, 因为硬件故障可能会导致多个 OSD 故障, 例如, 网络交换机故障, 可以导致集群中的多个主机及主机包含的 OSD 故障 当网络恢复之后, 每个 OSD 都必须执行恢复 back filling(回填): 当新 OSD 加入集群, CRUSH 将会为集群新添加的 OSD 重新分配 PG, 强制新的 OSD 接受重新分配的 PG 并把一定数量的负载转移到新 OSD 中,back filling OSD 会在后台处理, 当 backfilling 完成, 新的 OSD 完成后, 将开始对请求进行服务 在 backfill 操作期间, 你可以看到多种状态, backfill_wait 表示 backfill 操作挂起, 但 backfill 操作还没有开始 ( PG 正在等待开始回填操作 ) backfill 表示 backfill 操作正在执行 backfill_too_full 表示在请求 backfill 操作, 由于存储能力问题, 但不可以完成, ceph 提供设定管理装载重新分配 PG 关联到新的 OSD osd_max_backfills 设定最大数量并发 backfills 到一个 OSD, 默认 10 osd backfill full ratio 当 osd 达到负载, 允许 OSD 拒绝 backfill 请求, 默认 85%, 假如 OSD 拒绝 backfill 请求, osd backfill retry interval 将会生效, 默认 10 秒后重试 osd backfill scan min , osd backfill scan max 管理检测时间间隔 一个新 OSD 加入集群后, CRUSH 会把集群先有的一部分 PG 分配给他, 该过程称为回填, 回填进程完成后, 新 OSD 准备好了就可以对外提供服务。 remapped(重映射): 当 pg 改变, 数据从旧的 osd 迁移到新的 osd, 新的主 osd 应该请求将会花费一段时间, 在这段时间内, 将会继续向旧主 osd 请求服务, 直到 PG 迁移完成, 当数据迁移完成, mapping 将会使用新的 OSD 响应主 OSD 服务 当 PG 的 action set 变化后, 数据将会从旧 acting set 迁移到新 action set, 新主 OSD 需要过一段时间后才能提供服务, 因此它会让老的主 OSD 继续提供服务, 知道 PG 迁移完成, 数据迁移完成后, PG map 将会使用新 acting set 中的主 OSD 例如: [root@ ~]# ceph osd map volumes rbd_id.volume-1421625f-a9a2-41d0-8023-4cec54b33a57 osdmap e5276 pool 'volumes' (1) object 'rbd_id.volume-1421625f-a9a2-41d0-8023-4cec54b33a57' -> pg 1.2cdd8028 (1.28) -> up ([32,26,41], p32) acting ([32,26,41], p32) stale(旧): 当 ceph 使用 heartbeat 确认主机与进程是否运行, ceph osd daemon 可能由于网络临时故障, 获得一个卡住状态 (stuck state) 没有得到心跳回应 默认, osd daemon 会每 0.5 秒报告 PG, up 状态, 启动与故障分析, 假如 PG 中主 OSD 因为故障没有回应 monitor 或者其他 OSD 报告 主 osd down, 那么 monitor 将会标记 PG stale, 当你重启集群, 通常会看到 stale 状态, 直到 peering 处理完成, 在集群运行一段时候, 看到 stale 状态, 表示主 osd PG DOWN 或者没有主 osd 没有报告 PG 信息到 monitor 中 PG 处于未知状态, monitors 在 PG map 改变后还没有收到过 PG 的更新, 启用一个集群后, 常常会看到主 peering 过程结束前 PG 处于该状态。 scrubbing(清理中): PG 在做不一至性校验
有问题的PG: inactive :PG 很长时间没有显示为 acitve 状态, (不可执行读写请求), PG 不可以执行读写, 因为等待 OSD 更新数据到最新的备份状态 unclean:PG 很长时间都不是 clean 状态 (不可以完成之前恢复的操作), PG 包含对象没有完成相应的复制副本数量, 通常都要执行恢复操作。 stale:PG 状态很长时间没有被 ceph-osd 更新过, 标识存储在该 GP 中的节点显示为 DOWN, PG 处于 unknown 状态, 因为 OSD 没有报告 monitor 由 mon osd report timeout 定义超时时间
ceph pg 常见问题处理:
案例1:
1. 检查集群状态发现有pg inconsistent
通过ceph health detail查看具体的PG id。
$ ceph health detail
HEALTH_ERR 1 scrub errors; Possible data damage: 1 pg inconsistent
OSD_SCRUB_ERRORS 1 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent
pg 3.0 is active+clean+inconsistent, acting [34,23,1]
通过上面输出可以看到当前PG3.0处于inconsistent,并且它的三副本分别在osd.34,osd.23,osd.1。
2. 修复PG 3.0
$ ceph pg repair 3.0
instructing pg 3.0 on osd.34 to repair
#查看集群监控状态
$ ceph health detail
HEALTH_ERR 1 scrub errors; Possible data damage: 1 pg inconsistent, 1 pg repair
OSD_SCRUB_ERRORS 1 scrub errors
PG_DAMAGED Possible data damage: 1 pg inconsistent, 1 pg repair
pg 3.0 is active+clean+scrubbing+deep+inconsistent+repair, acting [34,23,1]
#集群监控状态已恢复正常
$ ceph health detail
HEALTH_OK
3. 根据以往经验,pg出现inconsistent很有可能是对应的osd磁盘上有逻辑坏道,可以去查看osd [34,23,1]的磁盘,查看对应节点上的dmesg日志。
dimes -T |grep -I err
案例2: osd挂了
当osd短暂挂掉的时候,因为集群内还存在着两个副本,是可以正常写入的,但是 osd.34 内的数据并没有得到更新,过了一会osd.34上线了,这个时候osd.34的数据是陈旧的,就通过其他的OSD 向 osd.34 进行数据的恢复,使其数据为最新的,而这个恢复的过程中,PG的状态会从inconsistent ->recover -> clean,最终恢复正常。 这是集群故障自愈一种场景。