案例1-WordCount
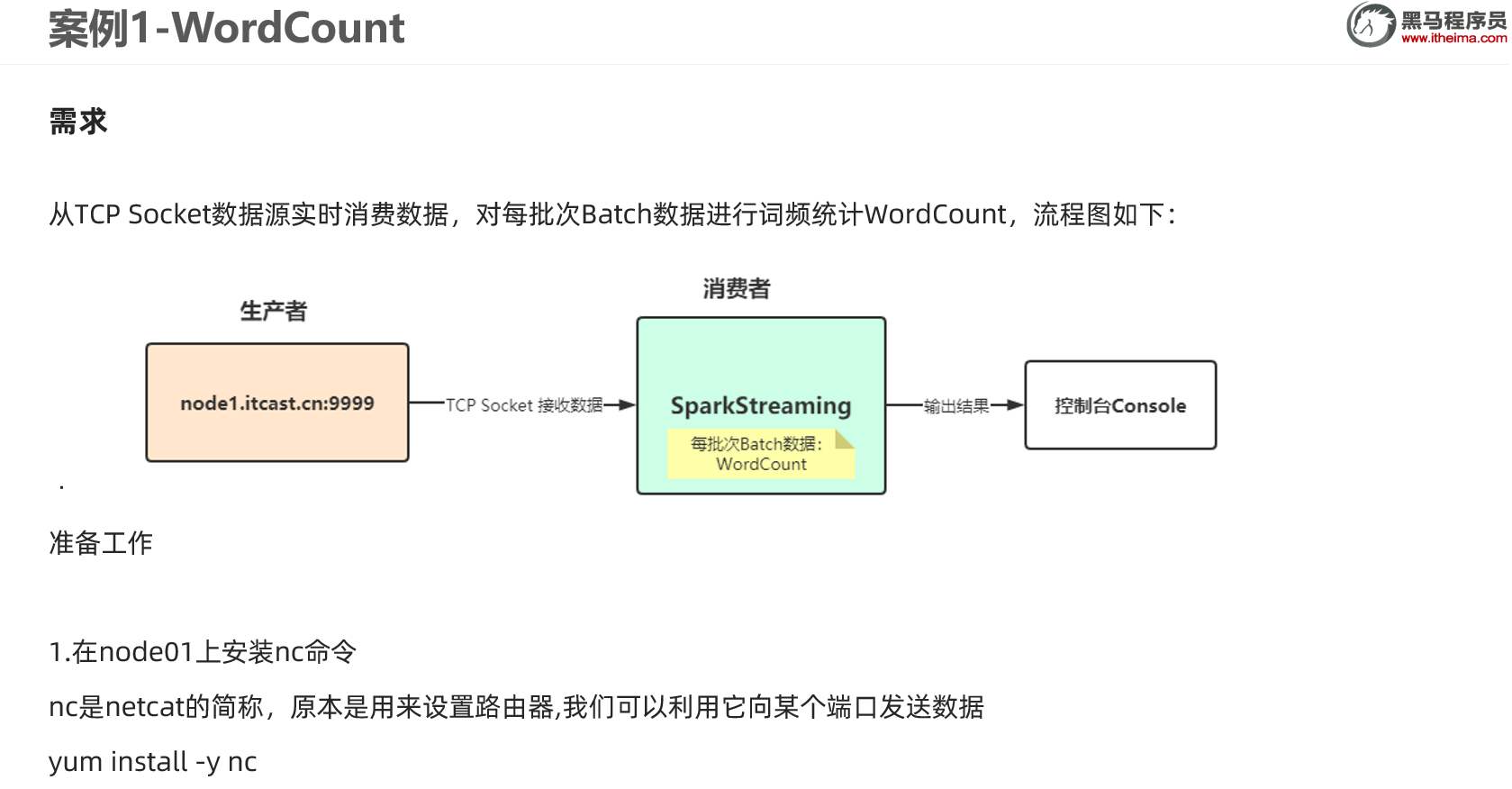
yum install -y nc
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext, streaming}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Author itcast
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount
*/
object WordCount01 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)//优雅关闭
}
}
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author itcast
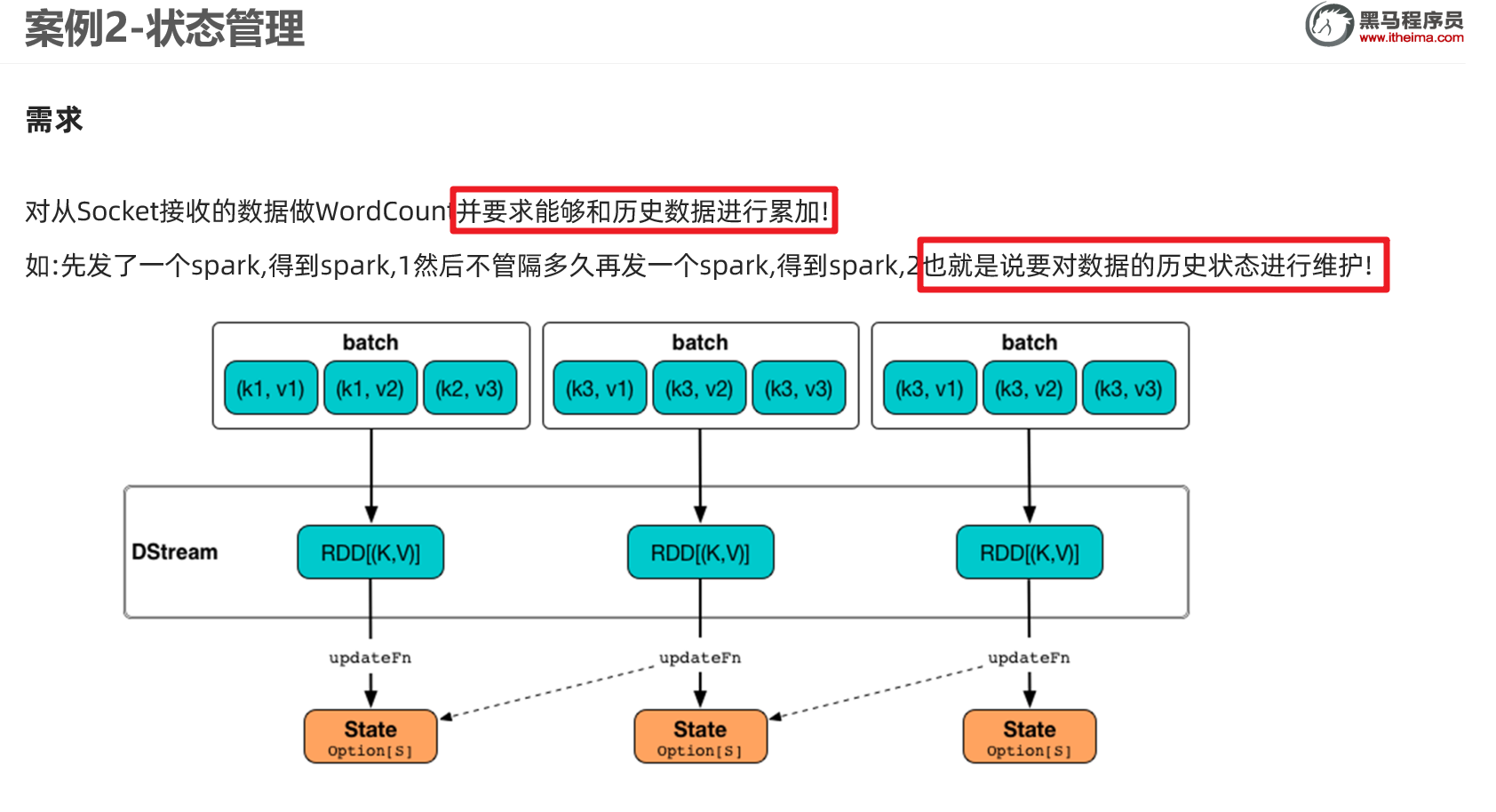
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount+实现状态管理:
* 如输入spark hadoop 得到(spark,1),(hadoop,1)
* 再下一个批次在输入 spark spark,得到(spark,3)
*/
object WordCount02 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5)) //每隔5s划分一个批次
//The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
//注意:state存在checkpoint中
ssc.checkpoint("./ckp")
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1", 9999)
//TODO 2.处理数据
//定义一个函数用来处理状态:把当前数据和历史状态进行累加
//currentValues:表示该key(如:spark)的当前批次的值,如:[1,1]
//historyValue:表示该key(如:spark)的历史值,第一次是0,后面就是之前的累加值如1
val updateFunc = (currentValues: Seq[Int], historyValue: Option[Int]) => {
if (currentValues.size > 0) {
val currentResult: Int = currentValues.sum + historyValue.getOrElse(0)
Some(currentResult)
} else {
historyValue
}
}
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
//.reduceByKey(_ + _)
// updateFunc: (Seq[V], Option[S]) => Option[S]
.updateStateByKey(updateFunc)
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination() //注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true) //优雅关闭
}
}
案例3-状态恢复-扩展
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author itcast
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount+实现状态管理+状态恢复
* 如输入spark hadoop 得到(spark,1),(hadoop,1)
* 再下一个批次在输入 spark spark,得到(spark,3)
*/
object WordCount03 {
def creatingFunc():StreamingContext ={
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5)) //每隔5s划分一个批次
//The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
//注意:state存在checkpoint中
ssc.checkpoint("./ckp")
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1", 9999)
//TODO 2.处理数据
//定义一个函数用来处理状态:把当前数据和历史状态进行累加
//currentValues:表示该key(如:spark)的当前批次的值,如:[1,1]
//historyValue:表示该key(如:spark)的历史值,第一次是0,后面就是之前的累加值如1
val updateFunc = (currentValues: Seq[Int], historyValue: Option[Int]) => {
if (currentValues.size > 0) {
val currentResult: Int = currentValues.sum + historyValue.getOrElse(0)
Some(currentResult)
} else {
historyValue
}
}
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
//.reduceByKey(_ + _)
// updateFunc: (Seq[V], Option[S]) => Option[S]
.updateStateByKey(updateFunc)
//TODO 3.输出结果
resultDS.print()
ssc
}
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val ssc: StreamingContext = StreamingContext.getOrCreate("./ckp", creatingFunc _)
ssc.sparkContext.setLogLevel("WARN")
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination() //注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true) //优雅关闭
}
}
案例4-窗口计算

如实际开发中:
每隔1min计算最近24小时的热搜排行榜
每隔10s计算最近10分钟的广告点击量
每隔1h计算最近7天的热搜

package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author itcast
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount+窗口计算
* 每隔5s计算最近10s的数据
*/
object WordCount04 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
//.reduceByKey(_ + _)
// windowDuration :窗口长度/窗口大小,表示要计算最近多长时间的数据
// slideDuration : 滑动间隔,表示每隔多长时间计算一次
// 注意:windowDuration和slideDuration必须是batchDuration的倍数
// 每隔5s(滑动间隔)计算最近10s(窗口长度/窗口大小)的数据
//reduceByKeyAndWindow(聚合函数,windowDuration,slideDuration)
//.reduceByKeyAndWindow(_+_,Seconds(10),Seconds(5))
.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
//实际开发中需要我们掌握的是如何根据需求设置windowDuration和slideDuration
//如:
//每隔10分钟(滑动间隔slideDuration)更新最近24小时(窗口长度windowDuration)的广告点击数量
// .reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Minutes(60*24),Minutes(10))
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)//优雅关闭
}
}
案例5-topN

package cn.itcast.streaming
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author itcast
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount+窗口计算
* 模拟百度热搜排行榜每隔10s计算最近20s的热搜词
*/
object WordCount05 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
//模拟百度热搜排行榜每隔10s计算最近20s的热搜词Top3
//windowDuration: Duration,
//slideDuration: Duration
.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(10))
//注意DStream没有提供直接排序的方法,所以需要直接对底层的RDD操作
//DStream的transform方法表示对DStream底层的RDD进行操作并返回结果
val sortedResultDS: DStream[(String, Int)] = resultDS.transform(rdd => {
val sortRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false)
val top3: Array[(String, Int)] = sortRDD.take(3)
println("=======top3=====")
top3.foreach(println)
println("=======top3=====")
sortRDD
})
//TODO 3.输出结果
sortedResultDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)//优雅关闭
}
}
/*
31省新增本土确诊23例:河北20例 31省新增本土确诊23例:河北20例 31省新增本土确诊23例:河北20例 31省新增本土确诊23例:河北20例
特朗普签令禁止与8款中国应用交易 特朗普签令禁止与8款中国应用交易
纸张价格上涨直逼猪肉 纸张价格上涨直逼猪肉 纸张价格上涨直逼猪肉 纸张价格上涨直逼猪肉 纸张价格上涨直逼猪肉 纸张价格上涨直逼猪肉
多家航空公司发布进出京退改票方案 多家航空公司发布进出京退改票方案 多家航空公司发布进出京退改票方案
石家庄中小学幼儿园暂停线下教学
*/
案例6-自定义输出
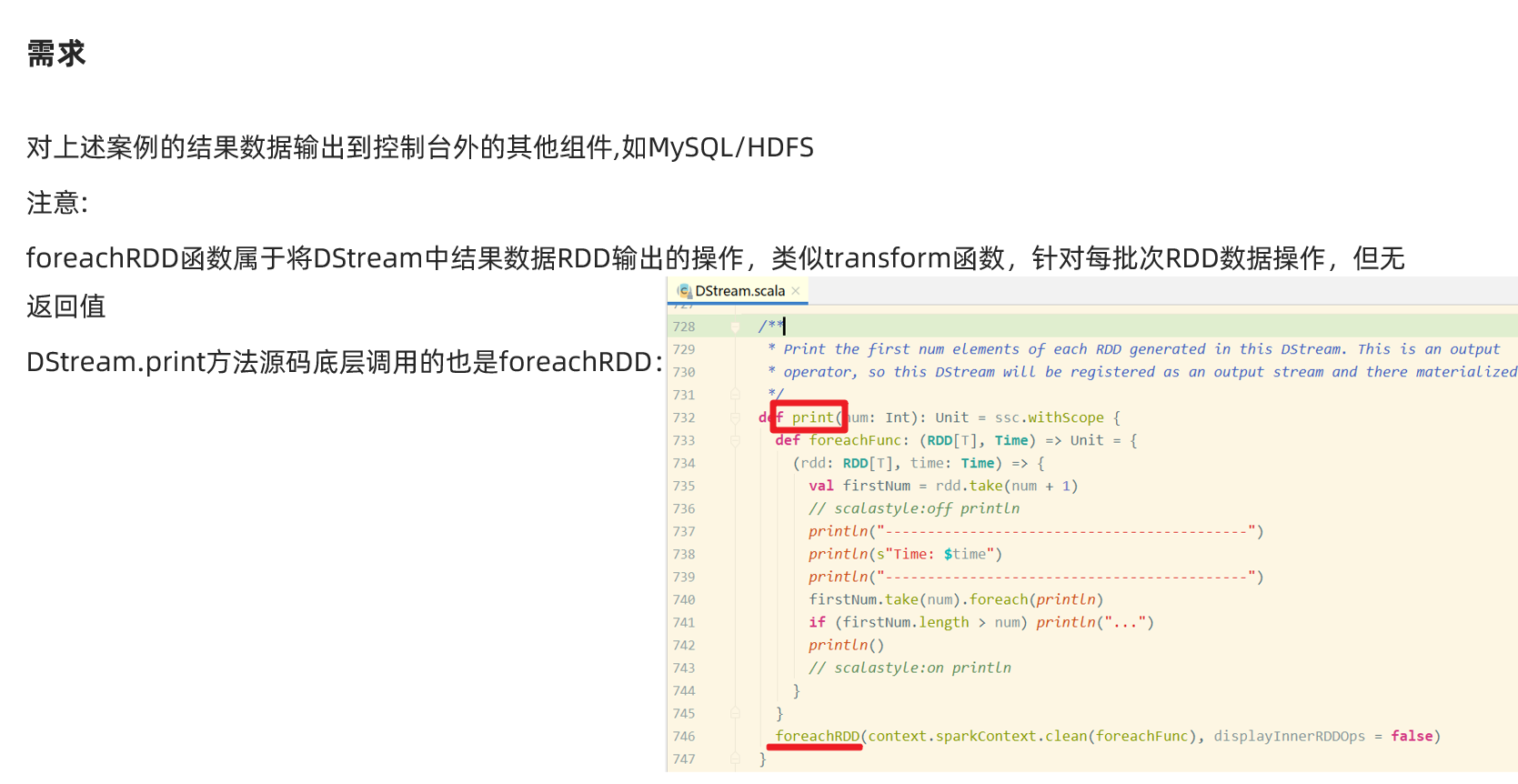
package cn.itcast.streaming
import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp}
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author itcast
* Desc 使用SparkStreaming接收node1:9999的数据并做WordCount+窗口计算
* 模拟百度热搜排行榜每隔10s计算最近20s的热搜词
* 最后使用自定义输出将结果输出到控制台/HDFS/MySQL
*/
object WordCount06 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node1",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
//模拟百度热搜排行榜每隔10s计算最近20s的热搜词Top3
//windowDuration: Duration,
//slideDuration: Duration
.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(10))
//注意DStream没有提供直接排序的方法,所以需要直接对底层的RDD操作
//DStream的transform方法表示对DStream底层的RDD进行操作并返回结果
val sortedResultDS: DStream[(String, Int)] = resultDS.transform(rdd => {
val sortRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false)
val top3: Array[(String, Int)] = sortRDD.take(3)
println("=======top3=====")
top3.foreach(println)
println("=======top3=====")
sortRDD
})
//TODO 3.输出结果
sortedResultDS.print()//默认的输出
//自定义输出
sortedResultDS.foreachRDD((rdd,time)=>{
val milliseconds: Long = time.milliseconds
println("------自定义输出---------")
println("batchtime:"+milliseconds)
println("------自定义输出---------")
//最后使用自定义输出将结果输出到控制台/HDFS/MySQL
//输出到控制台
rdd.foreach(println)
//输出到HDFS
rdd.coalesce(1).saveAsTextFile("data/output/result-"+milliseconds)
//输出到MySQL
/*
CREATE TABLE `t_hotwords` (
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`word` varchar(255) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`time`,`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
rdd.foreachPartition(iter=>{
//开启连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","root","root")
val sql:String = "INSERT INTO `t_hotwords` (`time`, `word`, `count`) VALUES (?, ?, ?);"
val ps: PreparedStatement = conn.prepareStatement(sql)
iter.foreach(t=>{
val word: String