《基于阻变存储器阵列的低功耗神经网络存算一体结构研究进展综述》
1. 摘要
忆阻器件组成的阻变存储器阵列具备存算一体能力,将神经网络的权重映射到忆阻器的电导值后,阻变存储器阵列可以用于高能效的神经网络推理和训练运算,但器件的脉冲编程非理想性和非理想的保持特性与耐擦写特性会造成计算上的精度损失。通过合理的电路设计方法可以减少非理想性带来的影响,这些方法包括了权重表示和编程的优化,输出读取结构的优化,以及系统稳定性的优化。通过与感知计算以及传统数字计算方案的结合,基于阻变存储器阵列的存算一体技术可以应用于同时有严格的算力要求和功耗要求的物联网系统中。
2. 介绍
人工神经网络算法(Artificial Neuron Networks, ANNs)的快速发展使得人工智能(Artificial Intelligence, AI)方面的研究引发了新的浪潮,并在如图像识别、自然语言处理、自动驾驶等领域中取得了大量的优秀成果。
为了加快神经网络的推理与训练速度,使得神经网络算法可以在更多的终端设备上部署,需要在硬件层面上提升算力并降低功耗。
但随着神经网络算法的参数规模和运算量急速提升,神经网络运算硬件平台面临着海量数据吞吐引发的存储器带宽与计算单元运算速度不匹配所带来的“存储墙”问题,CMOS工艺难以进一步提升所带来的提高集成度从而提高性能的方法失效问题等。
神经网络算法的基本原理是通过输入向量与抽象的“神经元”存储的权重进行进行乘加后再经过非线性激活后输出,通过多层的“神经元”相互连接去拟合复杂的函数关系。
阻变存储器阵列基于可以外部施加偏压来改变阻值的忆阻器件,将“神经元”的权重值编程至阵列中的忆阻器件中,向量以电压的形式输入阵列,便可以通过电流的形式获得乘加运算结果。
由于其存储与运算一体化的特性,基于阻变存储器阵列的神经网络运算平台可以彻底规避“存储墙”问题;同时忆阻器可以通过3D集成工艺摆脱平面工艺的发展瓶颈,进一步提升集成度,实现更高的存储密度。
但使用阻变存储器阵列实现高性能且稳定的神经网络运算也存在大量需要克服的问题,如忆阻器件在脉冲编程下的的非线性、非对称性,各个器件之间的波动性,高阻态漏电流,阻值漂移等。针对这些问题,大量的研究从器件级到电路系统和算法级,提出了各种解决方案。
本文将介绍忆阻器件的原理及其非理想性所带来的影响、阻变存储器阵列实现神经网络算法的方法以及提升运算性能的电路级优化方法,并总结该技术未来的研究方向及可能的应用场景。
3. 忆阻器件原理及其特性对神经网络运算的影响
研究基于阻变存储器阵列的存算一体(Compute In Memory,CIM)的系统实现需要首先需要了解基本的忆阻器件的工作原理以及其与运算之间的关联性,同时需要关注器件非理想性对系统工作会产生的影响。这些非理想性带来的问题,有些可以通过工艺和器件结构/材料的改进解决,有些则需要在系统和算法层面上进行优化。本章节将在简单介绍忆阻器件工作原理与计算的实现方式的基础上,对器件的非理想性及其带来的问题进行深入的讨论。
3.1 忆阻器件工作原理
忆阻器件由上下的电极以及电极间的阻变金属氧化物构成,通过在上下电极间施加不同的电压,凭借电场的调控作用,可以对应的控制阻变层中氧空位的分布。不同的氧空位的分布可以调节阻变层中导电细丝的形状、通断,最终改变阻变器件的电阻大小。忆阻器件可分为单极性和双极性,单极性器件的开关方向取决于施加电压的幅度,而不取决于施加电压的极性,双极性器件的开关方向则与施加电压的极性有关[1]。
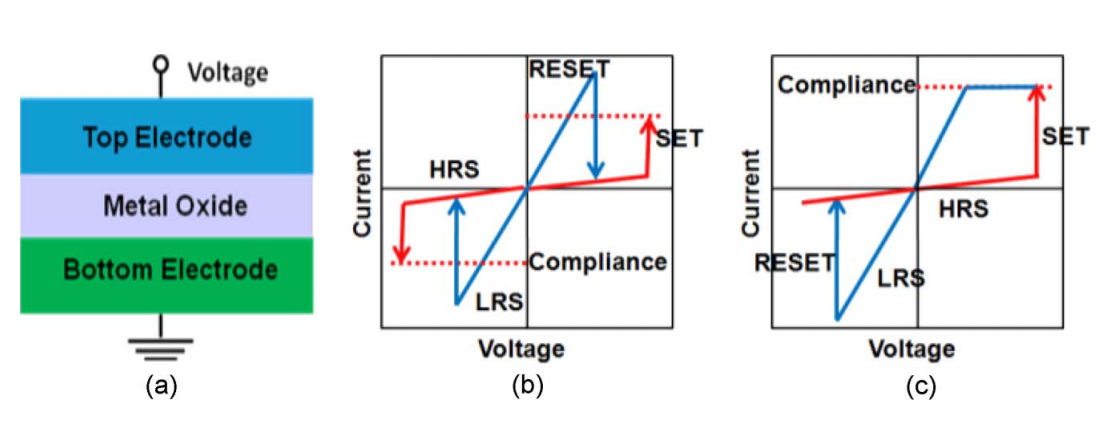
(a)阻变器件结构 (b)单极性阻变器件IV特性 (c)双极性阻变器件IV特性
忆阻器件的操作可以分为读操作和写操作,写操作包括(1)Forming:通过施加一次性的高压,在阻变层内从无到有的形成导电细丝,器件由初始的超高阻绝缘状态变为低阻状态(Low Resistance State,LRS)(2)SET:该电压可以使促进导电细丝的生长,形
成更强的导电通路,使器件从高阻状态(High Resistance State, HRS)转变为 LRS(3)RESET:打断形成的导电通路,使得器件再次由LRS转变为HRS。在上述三个操作中,一般Forming电压最高,RESET次之,SET最小。Forming和SET极性相同,与RESET极性相反。
读操作(Read):为了从单元读取数据,施加不影响存储单元状态的微小读取电压以检测单元是处于HRS还是LRS。
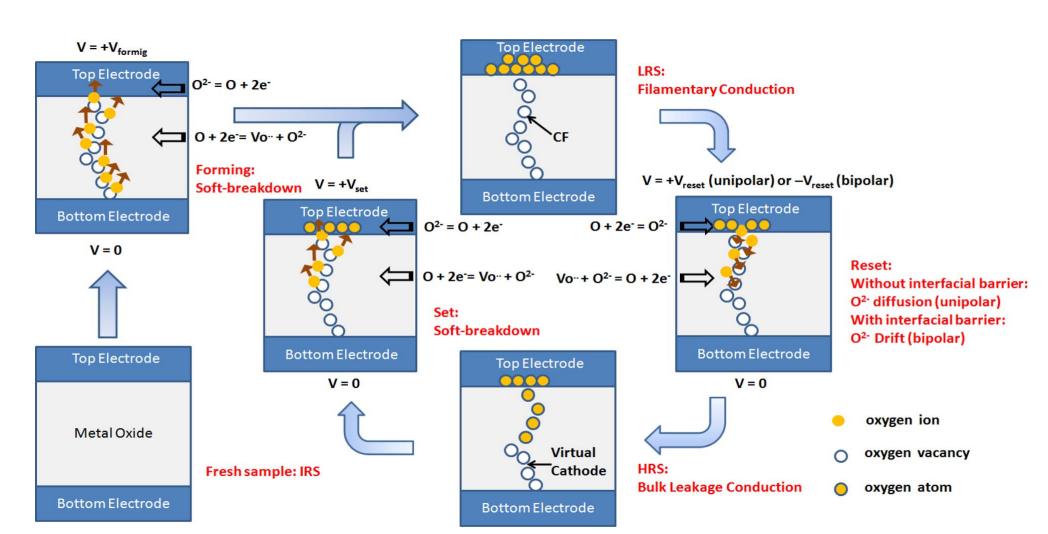
忆阻器件的操作
忆阻器件可以与材料与 CMOS 工艺兼容,可以实现与晶体管异质集成;结构简单,最小单元尺寸是 4F^2,同时尺寸缩小能力(Scalability)强(< 2nm),能够三维制备 ,实现高密度集成。目前工艺方面的先进成果包括:中国科学院微电子研究所研发的8层的三维集成阻变存储器阵列[2],以及与14nm的FinFET工艺兼容的阻变存储器阵列[3]。
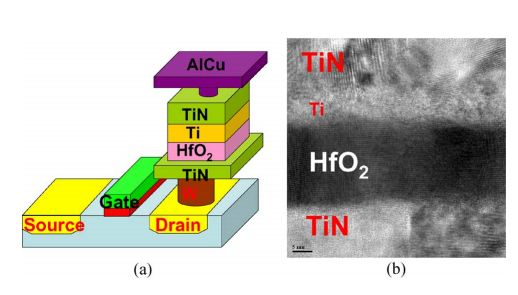
(a)忆阻器件与晶体管集成结构图 (b) TiN/Ti/HfOx /TiN叠层的HR-TEM照片
忆阻器件和MOS管组成1T1R基本单元,由于忆阻器上流过电流时会导致其阻值改变,故经常需要对每个忆阻器搭配一个MOS开关管,MOS关断时,RRAM上没有电流,因此可以长时间保持数据,MOS打开后可以进行读或写操作,1T1R单元是三端口结构,分别连接字线(Word Line,WL),源线(Source Line,SL)和位线(Bit Line,BL)。也可以将每个忆阻器件连接一个选择器构成1S1R单元,选择器类似两个背向串联的稳压二极管,在正负电压很小的时候几乎没有电流,在电压大于选择器的导通电压之后,选择器导通。本文将主要讨论1T1R单元构成的阵列。
对于1T1R单元构成的阵列,WL连接各行晶体管的栅极,SL连接每行晶体管的源极,BL连接各列忆阻器的上电极。大型阵列的外围电路一般包括WL、SL和BL的驱动,选择器,编码和解码器以及读出电路,对于特大容量的阵列,采用BL 和 SL 驱动分别位于阵列的顶部和底部的结构,有助于平衡远单元和近单元的 IR 压降变化[4]。
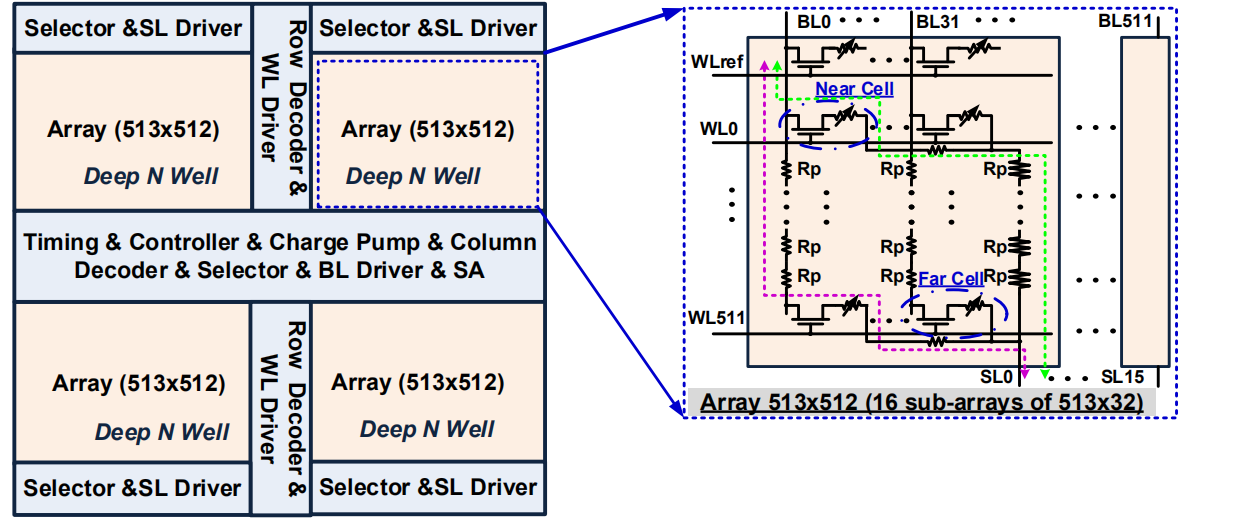
1T1R构成的阻变阵列结构
将向量编码成不同的读电压或者不同的读脉冲个数并施加在不同列上,将矩阵中的元素值对应编码为忆阻器器件电导值,则根据欧姆定律,当电压作用在电导上时,输出的电流值就表征了乘法计算的结果;根据基尔霍夫电流定律,各行的输出电流值就天然的汇总了流过各个器件的电流,完成了累加的计算。最终,各行输出的电流值就表示了矩阵向量乘的结果向量[5]。
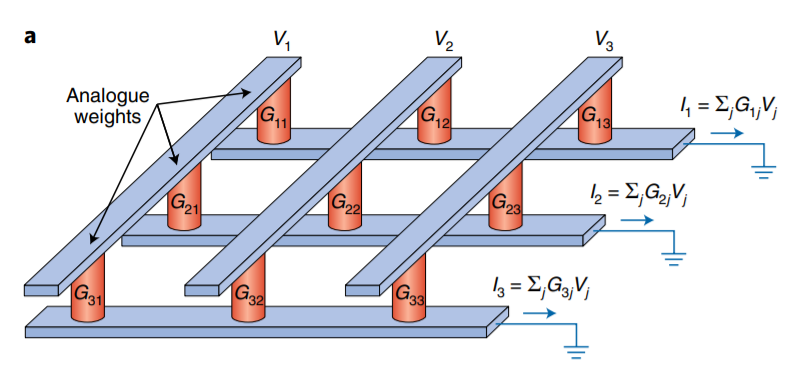
阻变阵列进行矩阵乘加运算原理示意图
3.2 忆阻器件的非理想性及其影响
理想的忆阻器件应该在等幅脉冲操作下具有线性、对称的“电导-脉冲”调制曲线,有 ≥ 6bit (64) 的中间状态,有足够大的窗口 (> 10)和尽可能小的器件操作功耗,同时,不同器件之间、不同操作循环之间有良好的一致性,没有波动、噪声等。
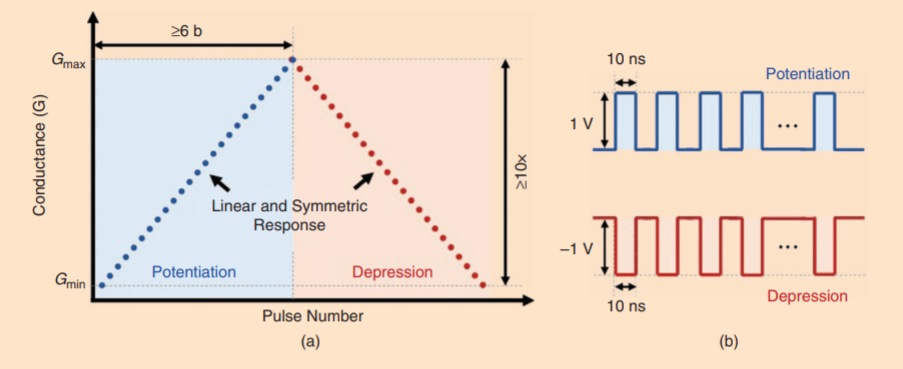
理想器件的"电导-脉冲"调制曲线
但实际的忆阻器件在有限的阻变窗口内,SET 和 RESET方向的连续电导调制通常是非线性、非对称的,并且存在严重的器件间、操作循环间的波动等,这些将严重影响CIM的计算性能[6]。
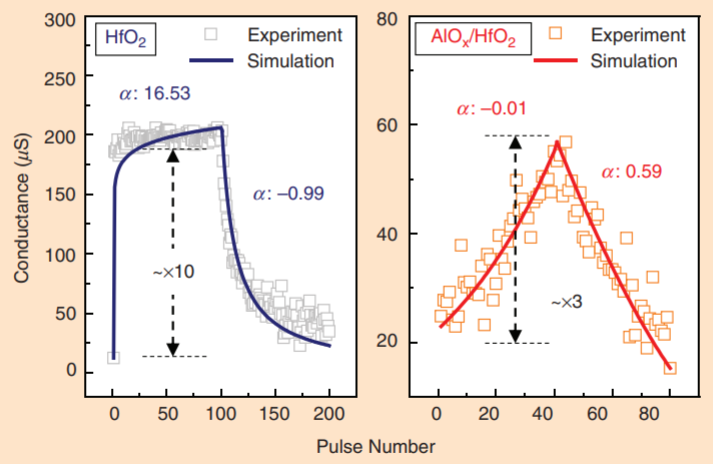
实际器件的"电导-脉冲"调制曲线
此外,理想的忆阻器件的阻值不会随着外界环境条件和时间产生变化,并有无限的擦写次数。但实际的器件的保持能力和擦写次数都是有限的。
现将器件非理想性概括为以下两类:
(1)脉冲编程下的连续阻变的非理想性。这类特性将严重影响系统表现,决定了系统的表现,主要有:电导-脉冲特性的非线性度,SET和 RESET 过程的非对称性、器件和循环的不一致性、电导调制过程中的抖动等。
(2)模拟型阻变器件的可靠的非理想性,主要反应连续阻变过程的器件可靠性和系统功能的可靠性,包括:保持特性和耐擦写特性等。
第一类问题导致的主要问题是阻变阵列的电导值编程困难,由于脉冲编程下的连续阻变的非理想性,通过简单的控制外加脉冲数量的方式难以准确的将电导控制到需要的值,进而导致计算时的矩阵中的元素值存在大量的误差,影响到最终计算结果。
第二类问题则会使得阻变阵列的计算结果准确度随着整个阵列的状态发生变化,如果电导发生了漂移,则矩阵中的元素值也随之漂移,进而影响最终的计算结果。而有限的擦写次数则会导致多次重编程后,部分电导值无法被写入阵列,造成计算时矩阵中的元素缺失。
此外,由于系统的运算结果依赖于模拟量,电压在导线上的损失(IR压降)也会导致计算精度的降低。
4. 神经网络算法在阻变存储器阵列上的实现
神经网络的计算任务可以大致分为前向运算的推理过程和反向运算的训练过程,在阻变阵列上实现前向推理运算的方法已经较为成熟,而对于训练运算则尚有许多可研究的空间,本章节首先将介绍前向推理的实现方式,不同输入和权重的编码方式及其带来的影响,以及算法对应的电路拓扑,接着将对有监督情形下的训练算法进行讨论。
4.1 前向推理在阻变存储器阵列上的实现
神经网络的前向推理过程的运算主要包括矩阵乘加运算和激活运算,矩阵乘加的运算量远大于激活。因此在部署神经网络时,将乘加运算在阻变阵列上实现,激活运算则通过外围电路进行实现。
为了进行矩阵乘加运算,需要对输入、矩阵元素(权重)进行数字到模拟的编码,在阻变阵列上完成全模拟的运算后,将结果再量化为数字量,送入后续系统。
输入编码时,可以用不同的读电压来编码不同的输入值,也可以用读脉冲个数(宽度)编码不同输入,还可以按输入不同比特位的值来编码,还可以采用采用组合编码实现。不同编码有各自的特点,电压编码计算速度更快,然而实现复杂度高,一个 8 bit 的输入值需要编码为 256 个不同的读电压值,同时引入器件读电压的非线性影响,对电路信噪比要求高;脉冲个数编码实现最简单,幅值固定,但是延时最大,一个 8 bit 的输入值可能要编码为 255 个脉冲。按比特位编码是对脉冲个数编码方案的优化,一个 8 bit 的输入值只需编码为 8 个脉冲,速度更快,但是每个脉冲计算的权重系数不同。组合编码中,可以将比特位编码和幅值编码相结合,如每两比特编码为四种不同的读电压值,这样一个 8 bit 的输入值只需编码为 4 个读脉冲,同时注意每次读的权重系数不同,需要对应的在输入或输出进行处理。
矩阵元素编码时可以利用忆阻器件电导连续的特点,将权重直接映射到器件的电导值上,但是由于器件的连续阻变的非理想性,这种直接映射的方法很难将电导值准确的控制到与权重一致,降低了运算精度,并且非常容易收到电导漂移的影响。也可以将二进制表示的权重映射到与位数相同个数的器件上,以高阻态表示逻辑"0",以低阻态表示逻辑"1",这样的好处是编程容易,也不容易收到器件不稳定性的影响,但会大大降低阵列的存储密度。还可以采用折中的方法,在单个器件上实现有限的阻态数量,用来表示多位的二进制数,如16个阻态可以实现 4 bit的编码,这样只需要两个器件就可以表示 8 bit 的权重,相对而言提升了存储密度,同时受到非理想性的影响相比模拟编码方式较小,稳定性较高。如果矩阵中同时存在正值和负值,可以采用两个器件组成差分对,利用差分电导表示单个元素值。
输出结果也有不同的量化方法。可以利用模数转化器(Analog to Digital Converter,ADC)将电流或电流转化的电压值(跨导运算放大器)直接量化,也可以利用积分器将电流信号转化为电压进行处理。
全连接网络的一种映射方式如图所示,将网络输入层的每个神经元值映射为对应的阵列位线的读输入;将网络输出层的每个神经元值映射为阵列源线上对应的累积输出电流;将网络中连接输入输出的权重映射为阵列中相应交叉点的电导值,根据3.1小节的介绍,可以利用欧姆定律和基尔霍夫电流定律,以CIM的形式完成神经网络需要的计算和处理[7]。
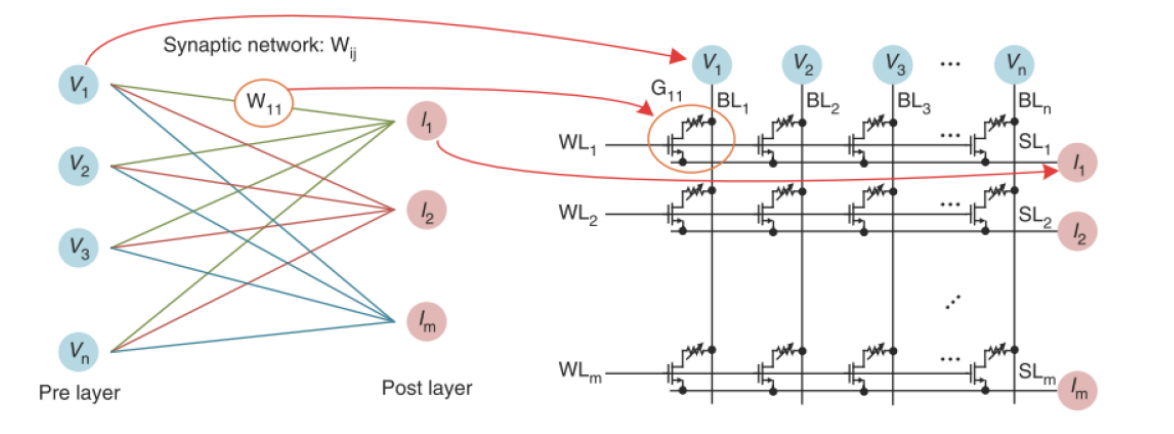
全连接神经网络的实现
卷积神经网络的映射方式与全连接神经网络相近,需要将卷积层和全连接的权重映射为阵列中相应交叉点的电导值。与全连接不同的是,卷积神经网络的输入需要将滑动窗内的3x3矩阵展开为1x9的一维向量,再进行输入,滑动窗需要滚动覆盖整张输入图片,因此需要多个周期才能完成整个卷积运算过程。
尽管阵列进行卷积运算时可以在共享输入下并行实现卷积层的不同卷积核,但由于上述的多周期的滑动输入,卷积运算仍然很耗时。 考虑到基于忆阻器的乘加计算在用作全连接层时更加高效和直接,忆阻器全连接层计算与忆阻器卷积计算之间的严重速度失配会导致相当大的效率损失。 在多个并行的忆阻器阵列中复制同一组权重是在卷积神经网络中有效加速识别输入图像的一种很有前途的方法, 忆阻器卷积的空间平行性可以极大地加速卷积滑动[8]。
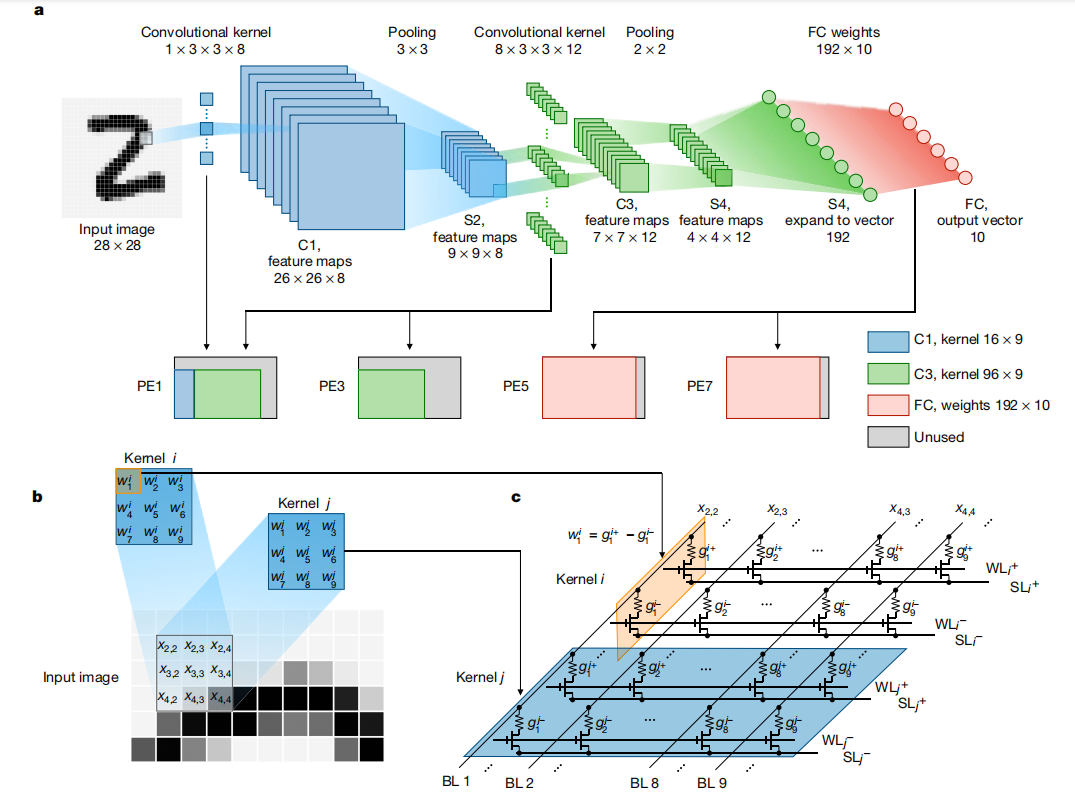
a.卷积神经网络的结构 b.卷积层在阻变阵列上的实现
4.2 有监督训练在阻变存储器阵列上的实现
由于器件脉冲编程下的连续阻变的非理想性,采用片外训练权重,再将权重编程到片上的神经网络计算实现方法必然会带来一定的精度损失,而进行片上训练是一种有效的克服这一问题的方式。
一种有监督的训练方法是首先对阵列进行前向推理,通过推理结果与标准标签的误差值,计算出每行电导权重的更新方向,分两步实现更新:(1)对该行中电导需要增加的单元并行的施加 SET 脉冲;(2)对该行中电导需要减小的单元并行的施加 RESET 脉冲。选中特定行通过在对应行的栅极施加适当的电压实现,非选中行接地或浮空。
由于在阵列中实现深层次的反向传播非常困难,可以只训练特定层的权重,如最后的全连接层权重,可以最高效的实现对整个网络所有权重的波动、漂移等非理想器件特性的兼容,以及系统其他噪声(如阵列寄生效应等)的补偿,也不会带来过大的系统开销[8]。
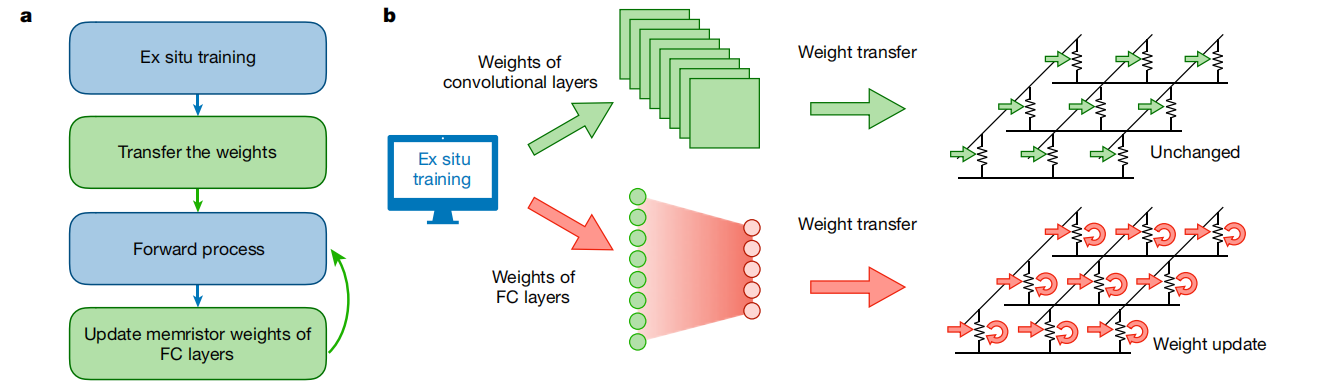
a.权重训练实现流程 b.卷积层参数直接使用外部训练得到的权重值编程,全连接层采用训练方法更新权重
5. 提升阻变存储器阵列上神经网络运算性能的电路级优化方法
本文第三章节对忆阻器件的非理想性及其带来的问题进行了讨论,本章节将详细讨论到目前为止阻变存储器研究领域中,针对器件非理想性问题的一些优秀的电路级解决方案,以及一些从系统的角度上对整体运算能效比进行提升的方法。
5.1 权重表示和编程的优化
5.1.1 2T2R单元
在 SW-2T2R 单元中,两个忆阻器件通过在推理阶段使用相反的电压极性来表示正负权重。 如果 \(V_{SL} = V_{CLP}\)、\(V_{BLP} = V_{CLP} – V_{READ}\)、\(V_{BLN} = V_{CLP} + V_{READ}\),\(G_{POS}\) 和 \(G_{NEG}\) 将分别代表正负权重。 最终,这个 2T2R 单元的等效权重是 \(W_{CELL}=G_{POS}-G_{NEG}\),它可以是正数、负数或零。 该权重对的 SL 电流分别等于流过正极和负极的差分电流。 根据 \(I_{CELL} = V_{READ} * W_{CELL}\),该电流与 \(W_{CELL}\) 成正比。 2T2R结构旨在通过从两个方面降低IR压降来提高精度:(a)如果\(G_{POS} = G_{NEG}\),\(I_{CELL}\)可以降为零; (b) 通过同一列上的正权重和负权重的电流可以局部抵消,减少了SL上的总电流[9]。
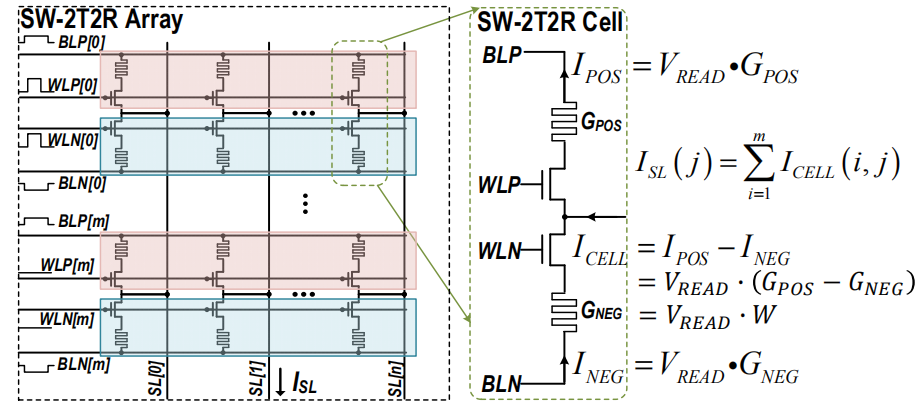
2T2R单元结构及阵列结构
5.1.2 写校验编程方法
开环单周期的写操作会产生忆阻器件的电阻值偏离目标,此外,忆阻器没有完全的高阻或低阻状态,因为导电丝不能完全断裂或形成。 因此,写操作中忆阻器件的电阻受初始电阻影响的记忆效应加剧了电阻的偏离。进而导致 计算出错。
可以采用写校验编程方法来克服这一问题,在写操作中,忆阻器件的电阻会随着写脉冲而变化。 在每个写脉冲之后,基于 ADC 的读出电路可以估计忆阻器件的电阻,即读出的电压(\(V.RBL\))可以间接表示访问的忆阻器件的电阻。 闭环写校验设置一对标准阈值(\(V_{th+},{V_{th-}}\)),该阈值与读出电路的输出进行比较。 在写操作中,对LRS 单元施加 RESET 脉冲,读出电路估计忆阻器件的电阻。 如果已编程忆阻器件的\(V.RBL\)低于下限阈值\(V_{th-}\),则编程脉冲的脉宽会增加。 如果\(V.RBL\)高于上限阈值\(V_{th+}\),则 编程脉宽会降低[10]。
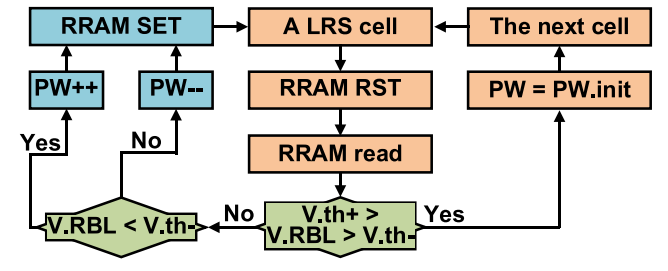
控制编程脉宽的写校验编程方法
这种写校验方式的调控对象不仅可以是脉宽,也可以是脉冲的幅度或脉冲的个数。
5.2 输出读取的优化
5.2.1 输出采样
阻变阵列的乘加计算结果可以通过电流采样,电压采样或电荷采样的方式读出,电流采样方式电路拓扑更简单和常见。
电流采样方式下的输出结果由 BL 线上的总电流与 LRS 电流的比率决定。 在 RRAM 阵列具有足够高的 ON/OFF 比(即HRS阻值与LRS阻值之比)的前提下,HRS 的电流可被忽略。 但在低ON/OFF比的情况下,来自访问忆阻器单元的HRS的总电流容易超过LRS电流的量,从而导致逻辑模糊[9]。
一种解决方案是不直接使用总电流与LRS电流之比计算结果,而是将选中的单元数量(\(N_{WL}\))馈入读取电路,从而动态的生成参考电流(\(I_{REF}\))。因为对于具有选中的单元数量相同的乘加计算,相邻结果之间的\(I_{BL}\)分布中没有重叠区域,在给定 \(N_{WL}\)的情况下,对应每种HRS和LRS单元的个数组合,只有一种 \(I_{HRS}-I_{HRS}\) 组合模式。因此通过基于 \(N_{WL}\) 的值自适应地生成适当的\(I_{REF}\) 可以扩大HRS和LRS单元的个数组合之间的 BL 电流(信号余量)的距离[11] 。
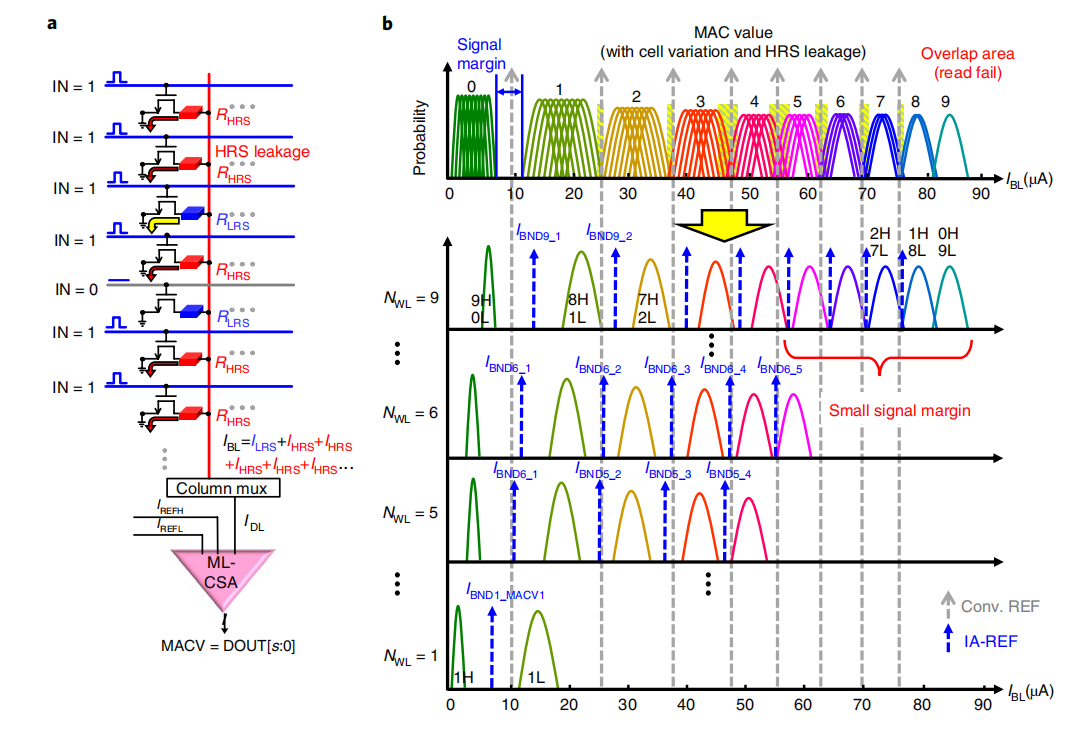
a.将选中的单元数量馈入读取电路的电流采样电路 b.固定参考与自适应参考的对比
电压采样的方式存在采样电压随着单元数量增加而非线性变化的问题。使用固定大小的电流源加在忆阻器件上产生HRS电压和LRS电压的情况下,由于并联电阻,读取单元数量增加时,读出电压会随着更多的 LRS 单元被访问而急剧下降,从而使读出电压表现出极窄的采样余量, 即使使用具有非线性参考的 ADC,最终也会限制计算结果的准确性。 可以通过使 BL 电流与读取单元个数成比例来解决这一问题。通过采用读出电压变换控制BL电流源的方式,使得采样电压在单元数量增加的情况下依然能够保持线性变化。
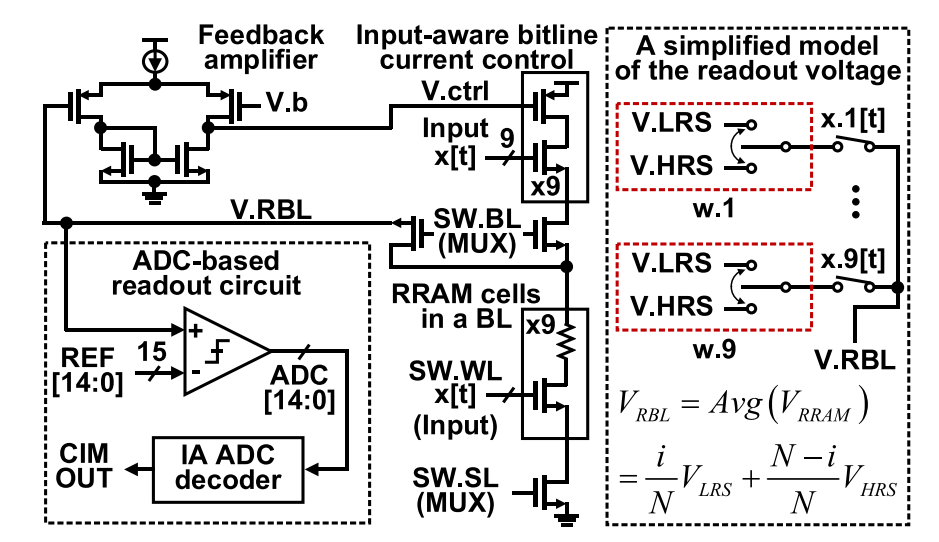
电压采样的读出结构
上述结构输出的读出电压实际上是HRS电压和LRS电压的线性组合,通过将选中的单元个数馈入读出电路,以HRS电压和LRS电压之差作为输入参考,利用线性关系便可以得到计算结果[10]。
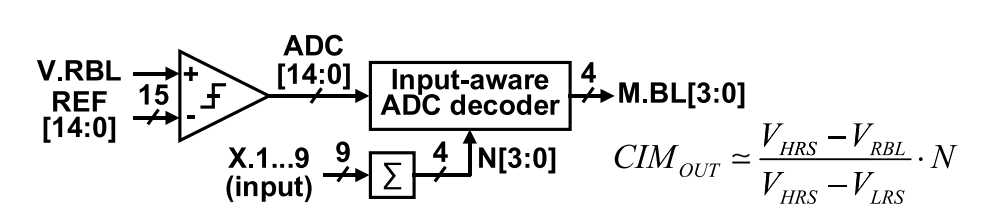
将选中的单元数量馈入读取电路的电压采样方式
5.2.2 ADC结构
在基于阻变阵列的CIM系统中,阵列本身的面积、延时和能耗的开销都非常低,主要是外围接口电路的开销影响了系统效率。在外围电路的功耗中,ADC工作产生的功耗又占了极大的比例,因此有大量的工作围绕存算系统中的ADC的优化展开。
一种具有典型性的优化思路是控制ADC的量化精度和转换频率,以满足系统要求的最低限度进行工作,从而减小系统的整体功耗。例如由积分器、比较器和分段电容DAC组成的ADC结构,其功耗由积分器和比较器的参考电流源控制,ADC分辨率通过设置采样时钟的频率进行配置[9]。
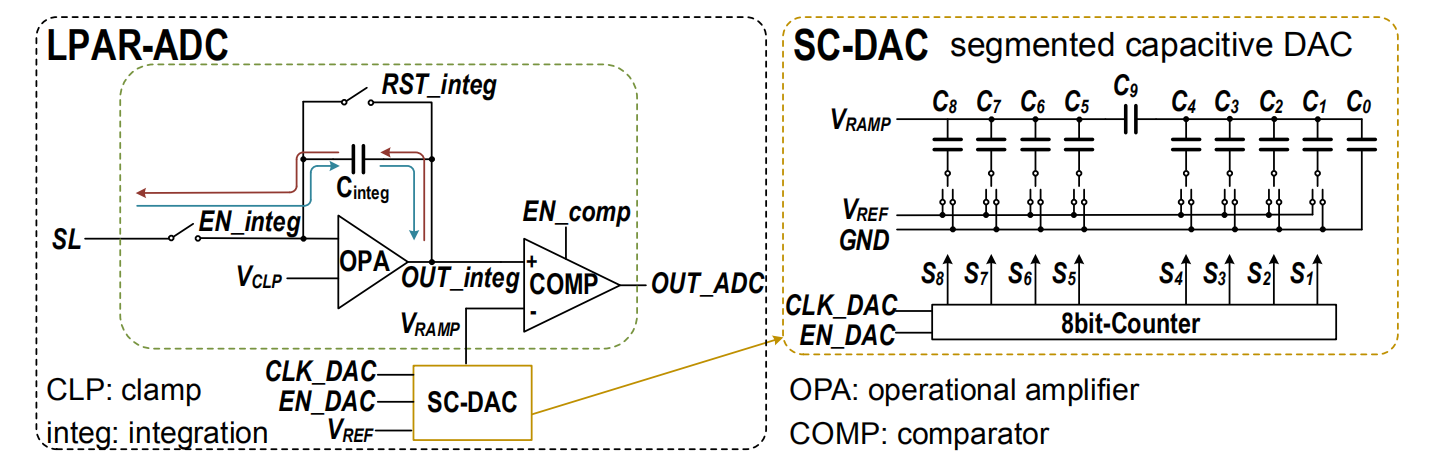
可配置参考电流源和采样时钟的ADC结构
另一种思路则是将ADC直接简化为更节省功耗和面积的电压读出放大器(Voltage Sense Amplifier,VSA)或电流读出放大器 (Current Sense Amplifier,CSA),将输出值与多个参考值并行比较,直接输出数字的结果[12]。
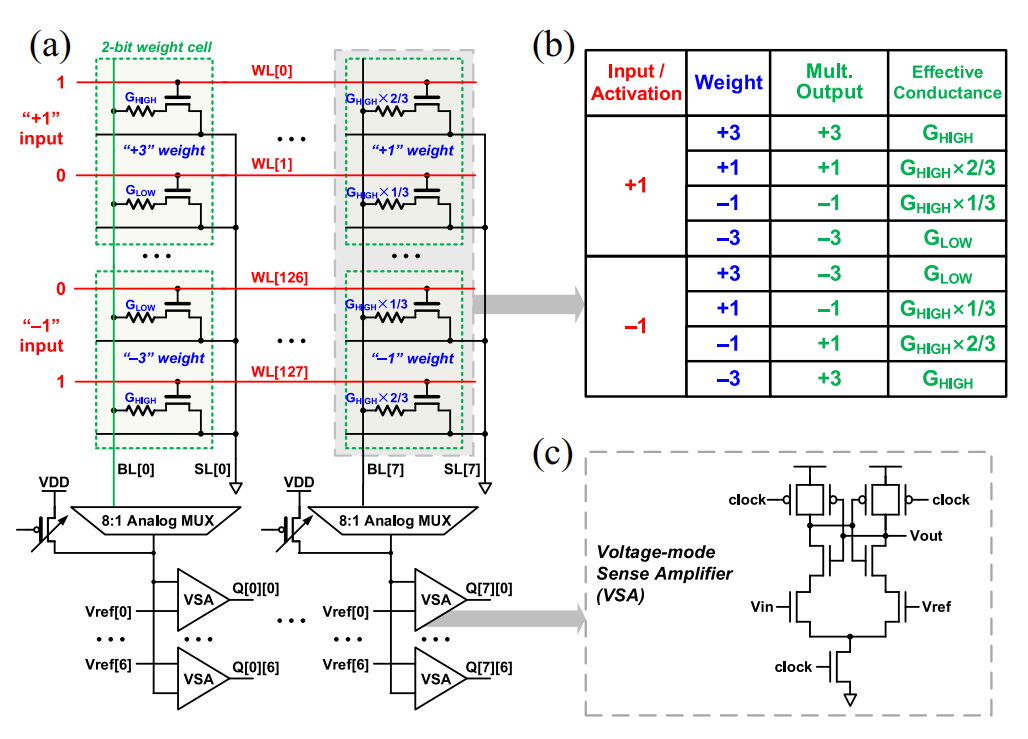
将模拟输出与参考值比较的VSA结构
5.3 系统稳定性的优化
由于实际忆阻器件的非理想保持特性和耐擦写特性,阻值会随着外界环境变化和时间而产生漂移,反复的读操作也可能会导致阻态的转变,因此需要通过定期的单元状态检测和更新的方式改善这一问题。在读操作访问HRS单元时,通过检测阈值的方式判断是否发生了阻态转变,若超过阈值阈值,则为访问的HRS单元执行RESET操作。单个写脉冲足以重置遭受干扰的HRS单元,因为忆阻器件的电阻仍然接近HRS电阻[10]。
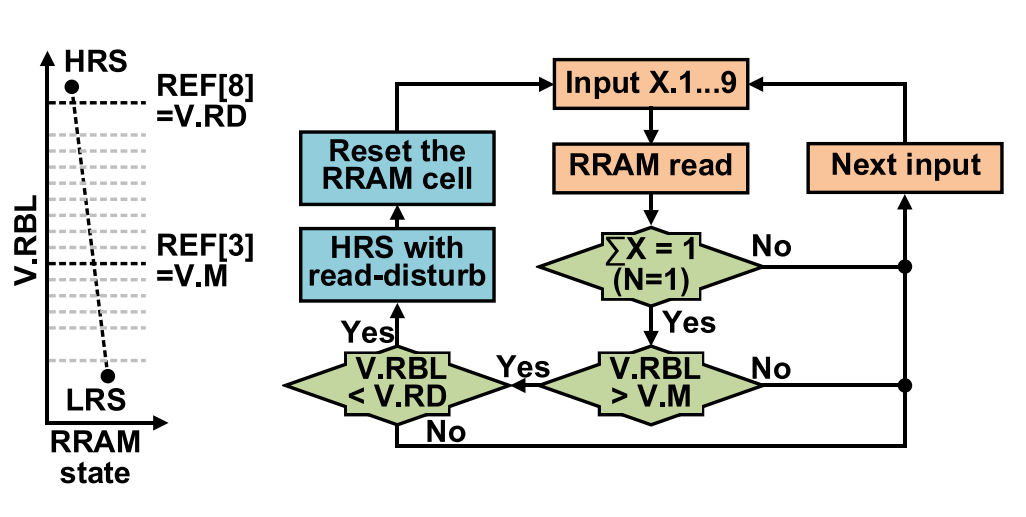
状态检测和更新逻辑
6. 未来研究方向与展望
基于阻变阵列的CIM系统所具备的高能效比优势使得其成为后摩尔时代的算力提升方案的有力候选,但器件的脉冲编程非理想性和可靠性问题,以及工艺方面的限制,使得大容量的CIM系统的实现仍然存在困难。此外,相比传统的CMOS数字解决方案,阻变阵列受到拓扑结构的限制,灵活性低,可实现的算法少。因此CIM系统需要找到一个适合自己的使用场景。
随着物联网(Internet of Things, IoT)技术的发展,各类应用对终端节点的计算能力的要求不断提升,同时节点的功耗又有严格的限制。将节点的工作内容根据算力要求和功耗要求的差别划分为不同的阶段,通过不同的硬件方案实现不同阶段的功能,是一种非常有效的方案。
以物联网应用中的监控摄像头系统为例,其工作可以分多个阶段实现节能。首先,系统仅检测运动,因此仅需要来自摄像机的数据,以及一些简单的逻辑电路。 其次,在检测到运动后,系统需要识别运动目标是人,宠物还是其他物体(例如扫地机器人)。 在此阶段,需要低至中等分辨率的图像和计算能力。最后,如果将该运动识别为人,则执行更高分辨率的图像和面部识别以识别该运动是否由入侵者引起。 在此例中,硬件需要是可配置的,以便系统在最佳条件下运行。
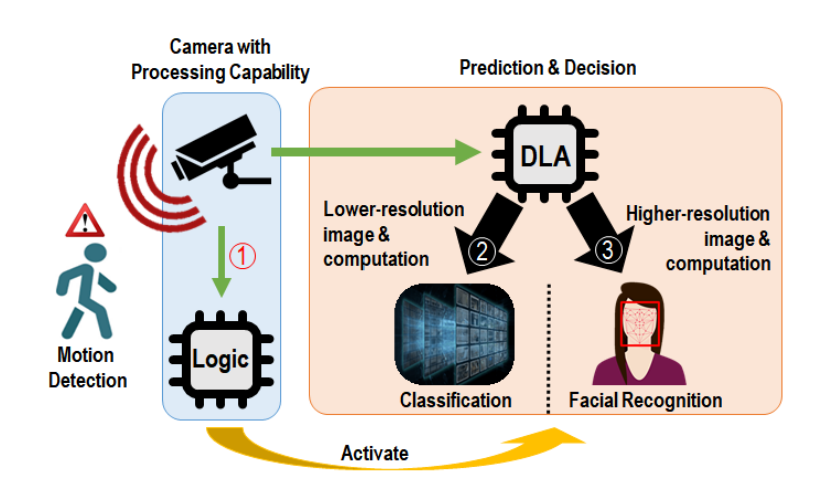
物联网应用中的监控摄像头系统的三个工作阶段
在上述的例子中,最前端的检测运动功能对算力的要求极低,通过像素值间的差分就可以实现,通过感知计算(Process In Sensor,PIS)技术以极低的功耗便可以实现其功能。而系统分辨目标类别的功能,对算力要求更高了,通过CIM技术部署卷积神经网络分类检测算法可以实现其功能,其功耗则可以做到远低于传统的数字方案。最后的高精度面部识别,需要输入高分辨率的图象,对算力的要求更高,因此通过传统的数字方案进行实现功能。由于后端的功能由前端的功能进行唤醒,功耗大的工作阶段的工作时长大大减少,从而降低了整个系统的功耗[13]。
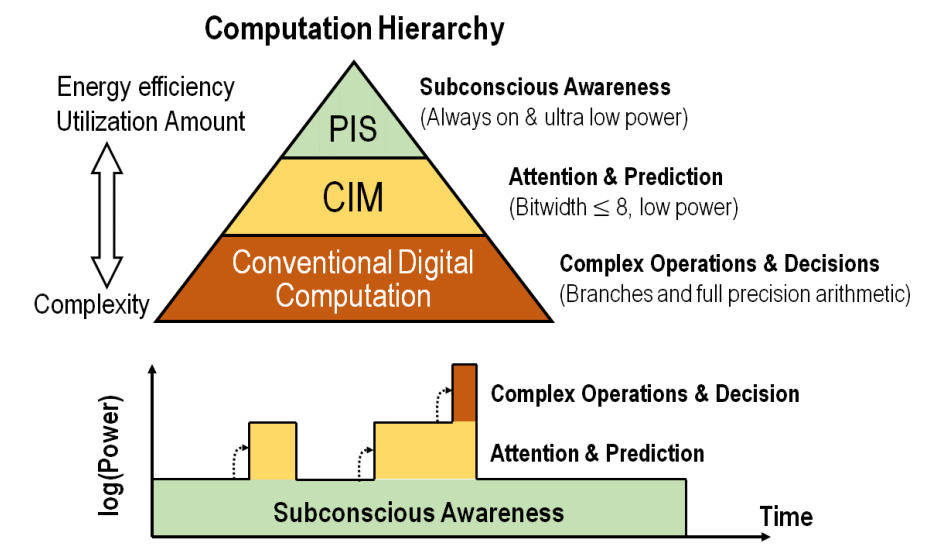
PIS,CIM和传统数字计算在应用中的层次化关系
在未来的研究中,需要发挥CIM技术在存储容量,高能效比以及CMOS工艺兼容性等优势,通过从器件到算法的优化技术减小非理想性带来的性能损失,将CIM技术与传统的CMOS数字技术,PIS技术等良好融合,在实际IoT应用的部署中灵活配置软硬件方案,提升整个系统的性能。
7.引用文献
特别感谢清华大学姚鹏博士,本文主体结构借鉴了其毕业论文。
[1]Metal–Oxide RRAM
[2]8-Layers 3D vertical RRAM with excellent scalability towards storage class memory applications
[3]First Demonstration of OxRRAM Integration on 14nm FinFet Platform and Scaling Potential Analysis towards Sub-10nm Node
[4]A 14nm-FinFET 1Mb Embedded 1T1R RRAM with a 0.022μm2 Cell Size Using Self-Adaptive Delayed Termination and Multi- Cell Reference
[5]In-memory computing with resistive switching devices
[6]Resistive memory-based analog synapse: The pursuit for linear and symmetric weight update
[7]基于阻变阵列的多层神经网络存算一体实现研究,清华,姚鹏
[8]Fully hardware-implemented memristor convolutional neural network
[9]A Fully Integrated Analog ReRAM Based 78.4TOPS/W Compute-In-Memory Chip with Fully Parallel MAC Computing
[10]A 40-nm, 64-Kb, 56.67 TOPS/W Voltage-Sensing Computing-In-Memory/Digital RRAM Macro Supporting Iterative Write With Verification and Online Read-Disturb Detection
[11]CMOS-integrated memristive non-volatile computing-in-memory for AI edge processors
[12]2-Bit-Per-Cell RRAM-Based In-Memory Computing for Area-/Energy-Efficient Deep Learning
[13]AI Edge Devices Using Computing-In-Memory and Processing-In-Sensor: From System to Device