在机器学习-李航-统计学习方法学习笔记之感知机(1)中我们已经知道感知机的建模和其几何意义。相关推导也做了明确的推导。有了数学建模。我们要对模型进行计算。
感知机学习的目的是求的是一个能将正实例和负实例完全分开的分离超平面。也就是去求感知机模型中的参数w和b.学习策略也就是求解途径就是定义个经验损失函数,并将损失函数极小化。我们这儿采用的学习策略是求所有误分类点到超平面S的总距离。假设超平面s的误分类点集合为M,那么所有误分类点到超平面S的总距离为
显然损失函数L(w,b)是非负的,如果没有误分类点,那么损失函数的值就是0,因为损失函数的定义就是求误分类点到平面的距离,误分类点都没有,那么损失函数的值肯定是0.
感知机学习算法是误分类驱动,采用随机梯度下降法。首先,任意选取一个超平面w,b,然后极小化目标函数。相关定义在作者的书中都有给出。不在啰嗦了。
感知机学习算法的原始形式
对例子2.1做详细推导。作者其实已经给出了推导。对于很多基础知识扎实的人来说已经足够了。但对于一些大学期间高数忘了差不多的我们来说,理通作者思路也要仔细手写推导一下。
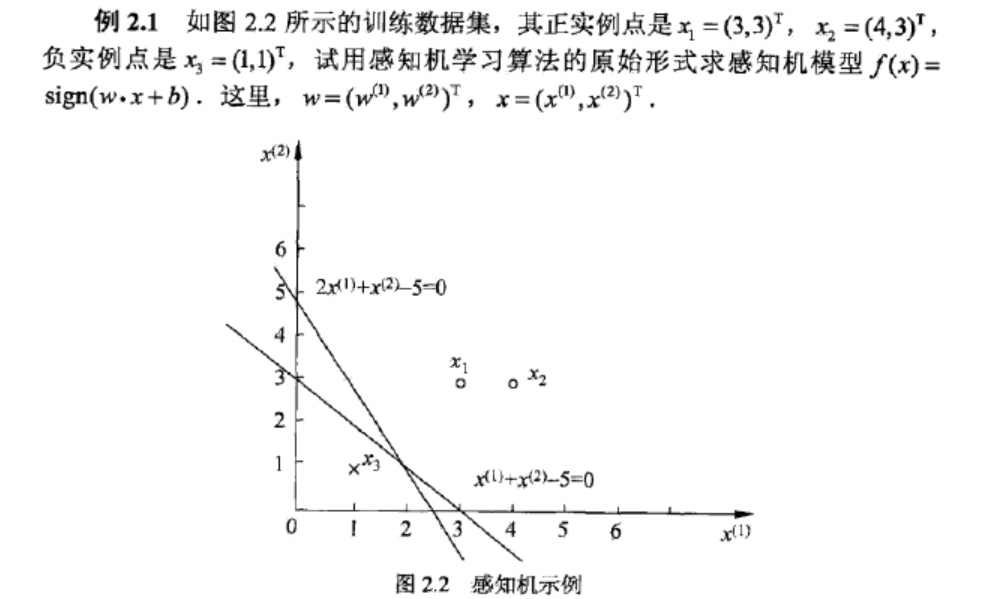
解 构建最优化问题: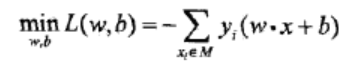 ,按照算法2.1求解w,b,学习η=1
,按照算法2.1求解w,b,学习η=1
取初值w0=(0,0)T (这里w0是初始的法向量,如果是三维空间应该是(0,0,0)T,这儿二维平面就够用了w0=(0,0)T。所以,w0=(0,0)T )
b0=0.
对x1=(3,3)T,因为是正分类点,所以y1=1带入分离 超平面公式
y1(w0•x1+b0)
= 1((0,0)T •(3,3)T+0) --------公式1.0
其中T代表矩阵的转置,也就是把(0,0)竖过来。同时这儿的(0,0)T和(3,3)T也是向量的表示。中间的圆点代表求两个向量的内积。我们看一下向量内积的定义

在线性代数中有对此的明确定义。所以(0,0)T和(3,3)T 的内积就为0*3+0*3=0.
所以公式1.0的值为0.因为要把所有的正实例和负实例分开,这儿该正实例在分离超平面上,显然不符合要求。所以我们要更新w,b.
w1=w0+y1x1 这儿更新w法向量的意义是移动分离超平面的方向,对于二维空间就是更改直线的斜率,更新b就是移动斜线的截距。
我们首先把这儿几个实例点表示出来x1y1=((3,3)T,1 ) x2y2=((4,3)T,1 ) x3y3=((1,1)T,-1 )
求得w1=(0,0)T+(3,3)T=(3,3)T b1=b0+y1=1
所以线性模型为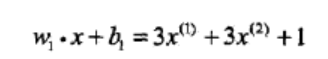
因为我们使用函数间隔来衡量是否被正确分类的,也就是在线性模型前面加上参数yi 因为正确分类时候yi=1,误分类的时候yi=-1,所以可以两者的乘积只要大于0就可以表示正确分类了,不需要更新函数参数。小于等于0就表示要更新参数。
新的线性模型对于点x1y1=((3,3)T,1 ) x2y2=((4,3)T,1 )显然都大于0,也就是可以被正确分类。对于 x3y3=((1,1)T,-1 ),带入后 函数间隔小于0代表函数未被正确分类。所以需要更新函数。
函数间隔小于0代表函数未被正确分类。所以需要更新函数。
w2=w1+y1x1 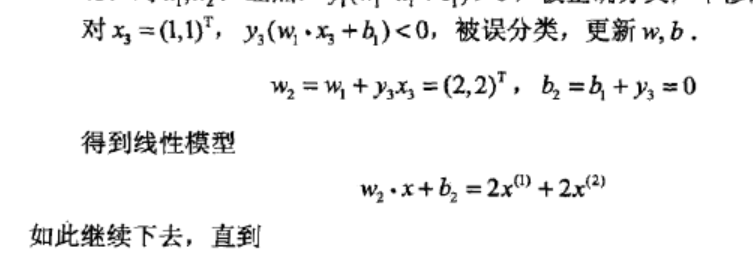
对于感知机求解的一般形式,很简单,仔细看书,了解几个数学概念就很容易明白。不在赘述。
感知机学习算法的收敛性
大体浏览了下,感觉不是很重要,也不是很难理解,可能是我没自己手动推导一下的原因。想研究的可以直接看作者的推导。
感知机学习算法的对偶形式
下面是作者书中给出的例子,但是没有具体的推导过程。

我们推导如下。从原始形式中我们可以知道。w的更新过程。
第一次更新是x1y1=((3,3)T,1 ) 点不能是函数模型大于零,所以 w1=w0+x1y1
第二次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w2=w1+x3y3
第三次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w3=w2+x3y3
第四次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w4=w3+x3y3
第五次更新是x1y1=((3,3)T,1 )点不能使其大于零,所以 w5=w4+x1y1
第六次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w6=w5+x3y3
第七次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w7=w6+x3y3
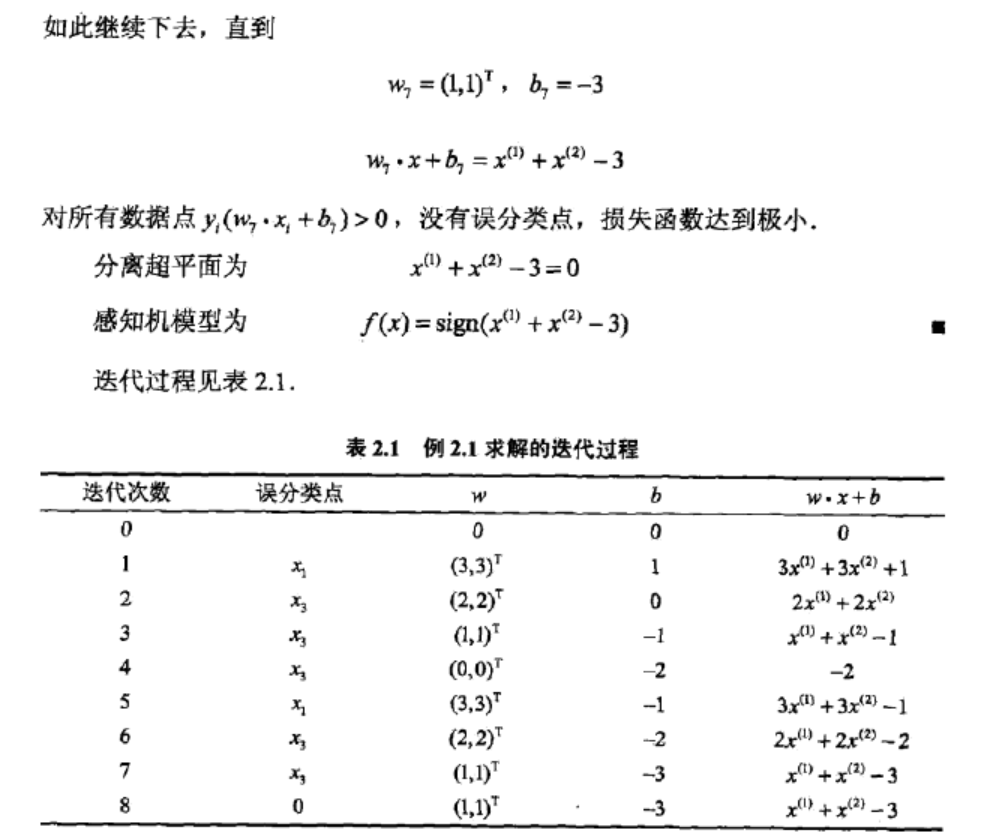
然后我们得到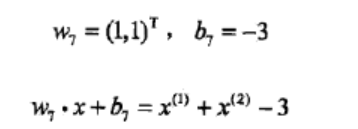
从上面可以总结出w7=w6+x3y3
w7=w5+x3y3 +x3y3
w7=w4+x1y1+x3y3 +x3y3
w7=w3+x3y3+x1y1+x3y3 +x3y3
w7=w2+x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w1+x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w0+x1y1 +x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
所以我们可以得出最终w7的值为两次x1y1 +五次x3y3
也就等于在对偶形式中的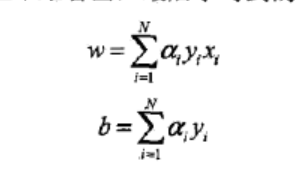
同理也可以得出b,例2.2中的误分条件我们还可以写成如下形式。
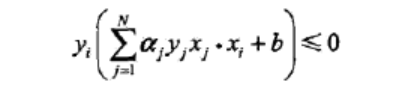

从上面的公式中对比作者给出的求解迭代过程。我们应该可以很容易理解对偶形式的感知机算法,推导后发现只是换了一个简便的计算形式。至此关于统计学习方法中的感知机篇章结束。
本文地址:http://www.cnblogs.com/santian/p/4351756.html
博客地址:http://www.cnblogs.com/santian/