一、背景
awk 在 linux 服务器 上是处理 字符串的,对于 字符串中获取想要的 子字串方面是一个比较好的工具。
二、用法
1、选项

| 选项 | 说明 | 备注 |
| -F | 一行中的字符串的分割符 |
不指定的时候默认是按照空格进行分割 可以指定多个分割符 -F '[ ,]' 表示先按照空格分割,对分割后的结果再按照 , 分割 |
| -v | 设置变量 | 可以用于 '' 中 |
| -f | 执行的 awk 脚本文件 | |
awk -option '表达式',其中表达式是必填的内容,基本用法都是用 awk 进行字符串切割,获取第几列的数据,如: awk -F ':' '{print $1}' ,表示按照 : 分割每行内容,打印分割后的每行的 第一列
2、表达式

3、内建变量
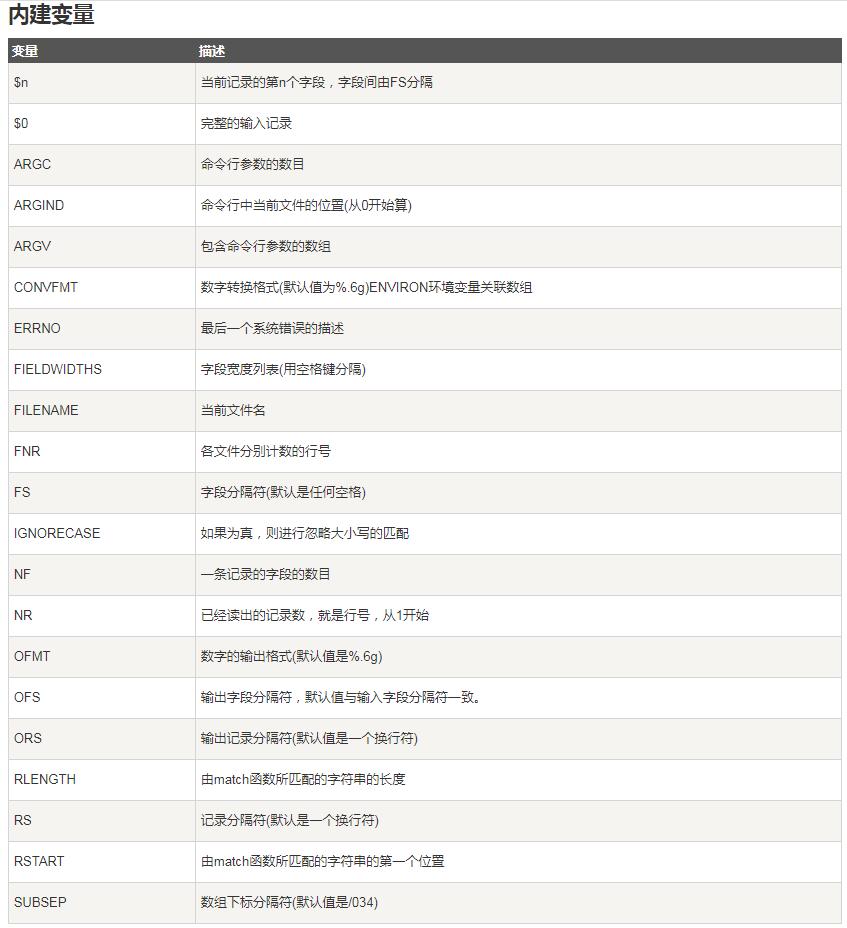
这里的 内建变量 主要用 在 '表达式' 中,如 ‘{print $n}’ ,展示第 n 列。
4、AWK 脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
1) 在 awk 命令里面直接 使用 Begin End 等

如上图中的示例,表示: 先打印表头 + 分行符 (BEGIN{ }),然后针对每行{ }的内容进行处理
2) 直接写一个 awk 脚本
$ cat score.txt Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62
$ cat cal.awk #!/bin/awk -f #运行前 BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL " printf "--------------------------------------------- " } #运行中 { math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d ", $1, $2, $3,$4,$5, $3+$4+$5 } #运行后 END { printf "--------------------------------------------- " printf " TOTAL:%10d %8d %8d ", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f ", math/NR, english/NR, computer/NR }
$ awk -f cal.awk score.txt NAME NO. MATH ENGLISH COMPUTER TOTAL --------------------------------------------- Marry 2143 78 84 77 239 Jack 2321 66 78 45 189 Tom 2122 48 77 71 196 Mike 2537 87 97 95 279 Bob 2415 40 57 62 159 --------------------------------------------- TOTAL: 319 393 350 AVERAGE: 63.80 78.60 70.00
以上示例来自:https://www.runoob.com/linux/linux-comm-awk.html
三、示例
1、打印所有列(默认按空格分割)
| ps -ef|grep ssh |awk '{print $0}' |

2、打印最后一列(默认按空格分割)
| ps -ef|grep ssh |awk '{print $NF}' |
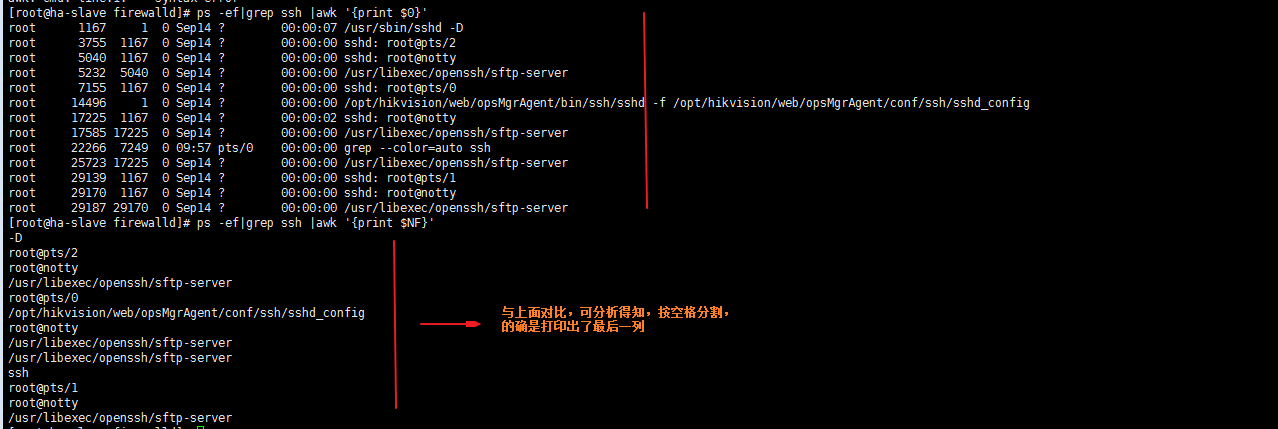
若想打印倒数第二列 则 为 $(NF-1) ,以此类推。
3、按照 : 分割,打印第一列
| date |awk -F ':' '{print $1}' |

4、打印倒数第二列,按照 : 分割
| date |awk -F ':' '{print $(NF-1)}' |

5、打印多列,如打印 第2列和第3列
| date |awk -F ':' '{print $2,$3}' |

6、打印N列之后的所有列(按空格分割)
awk '{for(i=1;i<=N;i++){$i=""}; print $0}' file
|
其原理是将其前N行全部设置为空,再打印全部
7、指定多个分割符,再按照多个分割符分割之后,打印第5列
| date |awk -F '[ :]' '{print $5}' |
示例表示:先按照空格分割,多分割后的结果再按照 : 分割,最后打印第5列

8、显示当前的分(仅显示当前时间中的分)+10,同时显示当前的分+单位
| date |awk -F ':' -va=10 -vb=m '{print $2+a,$2b}' |
这里设置了变量 a=10,b=m;对 date 显示出的时间按照 : 进行分割,同时获取分割后的第二列也就是 分,对其进行+10操作 和 显示带单位

9、表达式的使用
由上可以总结出 awk option '表达式' ,其中 '表达式' 在以上的例子上都用于 {print $N} 指定输出列了, 其实 '表达式' 可以有多种内容,并非仅仅用于指定输出列
test.txt 文件内容为:
1 xiaohong 33 2 xiaoming 22 3 tiantian 32
1) 显示第一列中大于1的所有行
| awk '$1>1' test.txt |
表达的意思是:仍然按照空格进行分割,显示第一列的数值大于1的所有行,由于这里在表达式中没有指定输出列,因此输出所有列

2) 显示第一列中大于1且第三列大于30的所有行
| awk '$1>1 && $3>30' test.txt |
表达的意思是:仍然按照空格进行分割,显示第一列的数值大于1且第三列大于30的所有行,由于这里在表达式中没有指定输出列,因此输出所有列

3) 显示第一列中大于1且第三列大于30的所有行,但仅显示第2列
| awk '$1>1 && $3>30 {print $2}' test.txt |
表达的意思是:仍然按照空格进行分割,显示第一列的数值大于1且第三列大于30的行中的第2列

10、内建变量的使用
1) 指定展示第3行
| awk 'NR==3' test.txt |
表达的意思:以空格作为分割符,展示第3行的数据
