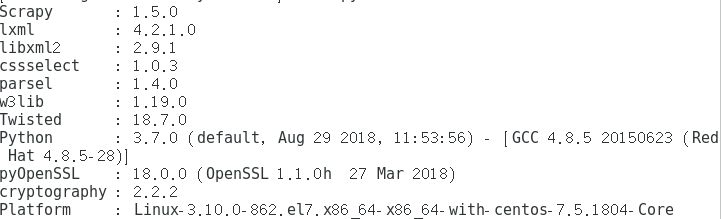
scrapy version -v #该命令用于查看scrapy安装的相关组件和版本
一个工程下可创建多个爬虫
scrapy genspider rxmetal rxmetal.com
scrapy genspider rxmetal2 rxmetal2.com
scrapy genspider rxmetal3 rxmetal3.com
..........
#该命令用于查看目录下的所有爬虫文件
scrapy list

#一个超级有用的玩意儿---------xpath目录文档获取器
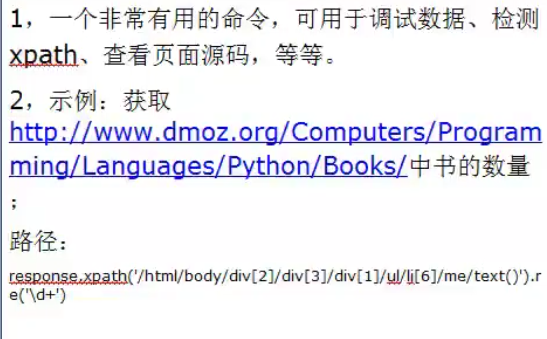
#scrapy shell一个通用爬虫命令,可以脱离爬虫项目而存在的命令
例如:我们可以爬取废旧金属交易网的某个页面
scrapy shell http://tj.copperhome.net/201807/26/tongjia_136193.html
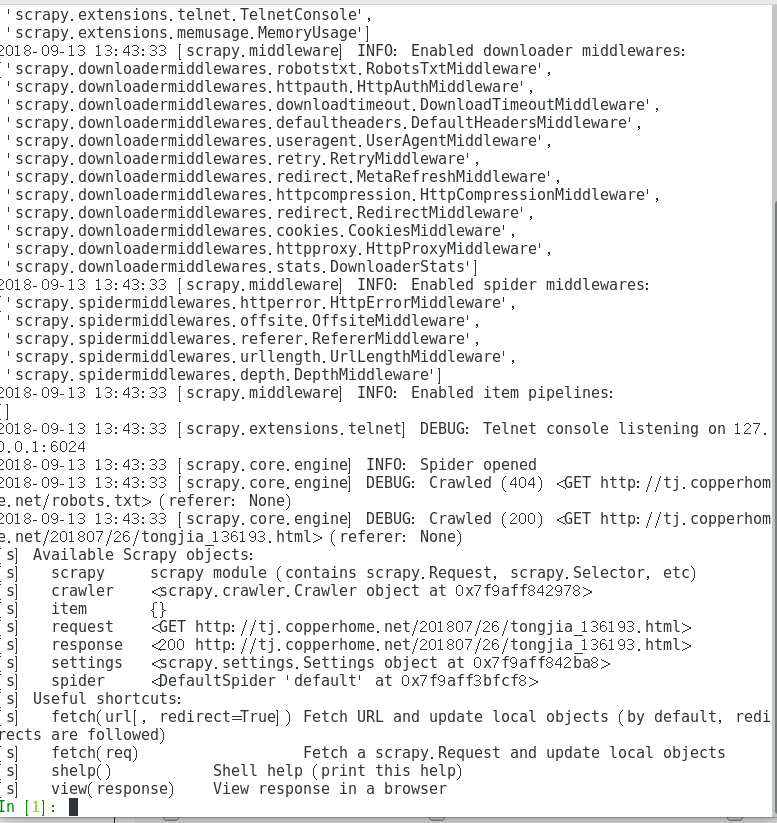
在成功获取页面代码之后,我们就可以用火狐浏览器打开下载的html,并配合火狐浏览器插件firebug获取感兴趣的dom结构的xpath信息。插件截图如下

使用方法如下,在页面选中感兴趣的行,右键弹出菜单,如果插件安装成功,你可以在菜单中选择inspect in firepath
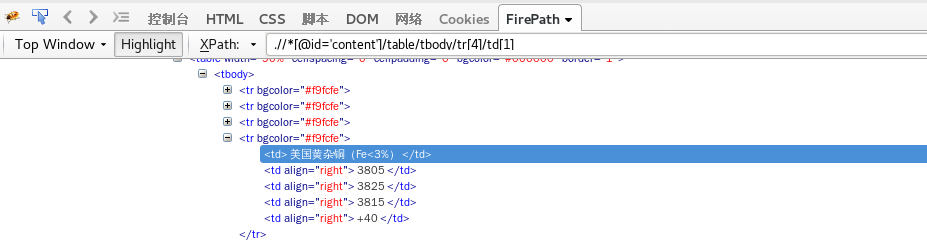
直接在shell命令行中执行
response.xpath(".//*[@id='content']/table/tbody/tr[3]/td[1]/text()").extract()
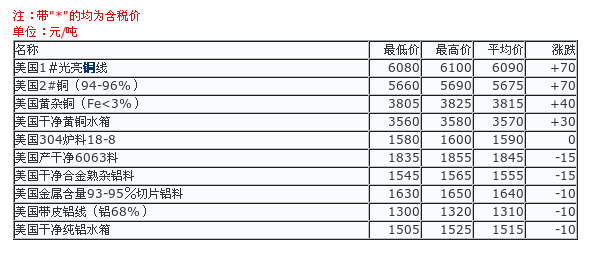
拿到金属材料的名称信息
