l JAVA平台异步消息模块
JAVA平台异步消息模块,是一个针对RabbitMQ的消息发送及处理封装,包含消息的配置、发送、接收、失败重试、日志记录等,总共分为4个部分:
1)RabbitMQ访问封装:JAMQP(Jar包)
2)消息模块公共对象、配置读取及接口定义:JMSG(Jar包)
3)消息发送端:JMSG—Client(Jar包)
4)消息接收端:JMSG—Server(War包)
l RabbitMQ简介
MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断的写入消息,而另一端则可以读取或者订阅队列中的消息。RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是 AMQP的标准实现。
RabbitMQ的结构图如下:
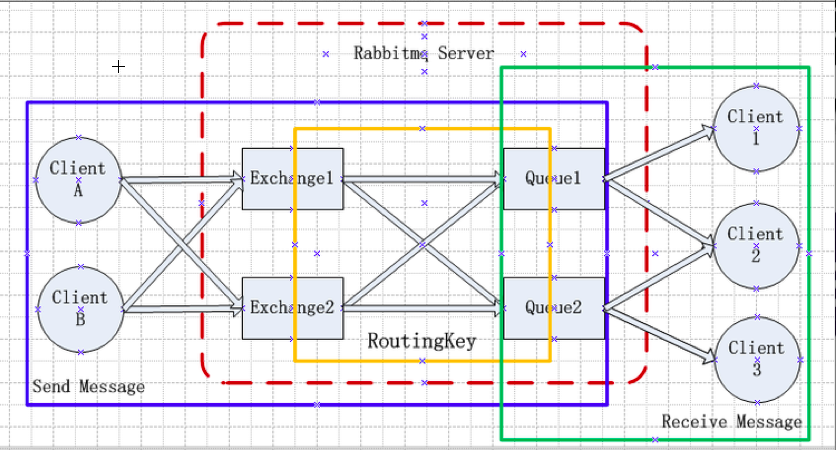
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Alternate exchange:发送给某Exchange的消息路由失败时,发送至该exchange。
Dead letter exchange:死信Exchange,将超过一定时间的Queue中的消息发送至该exchange。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把Exchange和Queue按照路由规则绑定起来。
Routing Key:路由关键字,Exchange根据这个关键字进行消息投递。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
l RabbitMQ封装
1) RabbitConfig :所有RabbitMQ有关配置
2) RabbitConnectPool :RabbitMQ连接池,管理所有对RabbitMQ的连接
3) RabbitProxy :RabbitMQ连接的封装,包含
4) RabbitSendProxy : 专门用于发送消息的连接,继承自RabbitProxy
5) RabbitReceiveProxy :专门用于接收消息的连接,继承自RabbitProxy
6) RabbitReceiverDispatcher : 消息分发器管理类,用于消息的接
7) 消息发送:从连接池RabbitConnectPool中Get出RabbitSendProxy,调用send方法发送消息,return获得的RabbitSendProxy。发送失败的消息记录本地文件,由轮询线程获取消息后重试3次
8) 消息接收:服务启动时向RabbitReceiverDispatcher注册要监听的队列,每一个监听对应一个线程以及一个处理消息的线程池,从RabbitMQ获取到推送来的消息后,通过线程池并行处理
l 内部流程
n 消息发送逻辑

n 消息接收逻辑

l 配置说明
n RabbitMQ配置表

n 消息配置表
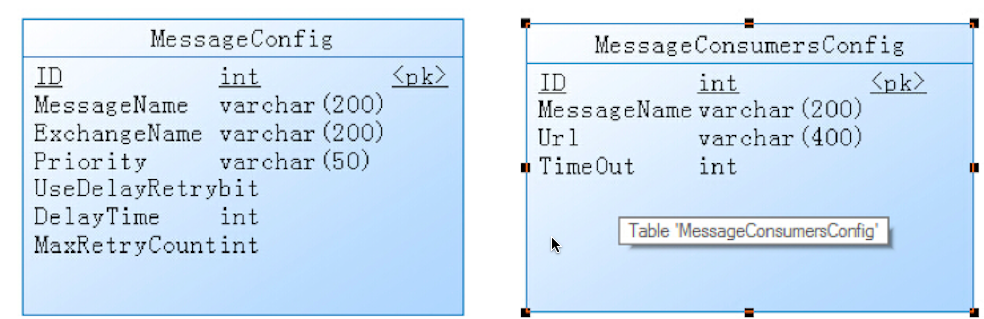
1) MessageName : 消息名称,MessageConfig表中唯一
2) Url : 消息的业务处理Http API地址
3) Priority : 消息优先级,必须写成P1,P2,P3....P8,P9,用于RabbitMQ的RouteKey,发送消息时的最终RouteKey = MessageName.Priority
l 使用方法
n 发送消息
消息发送方法定义:
/**
* 发送消息
* @param transferObject
* 消息主体对象
* @param customTag
* 自定义消息标签
* @param messageName
* 消息名称
*/
void send(Object transferObject, String customTag, String messageName);
在消息配置表中配置好消息的信息,引用JMSG和JMSG-Client 两个Jar包,调用方法如下:
public void SendMsg() {
RabbitMQSender sender = new RabbitMQSender();
sender.send(new Object(), "tag", "messageName");
}
注意:传输的对象(transferObject)进行JSON序列化后,大小不能超过64K,否则会抛出异常
n 接收消息
1) 实现一个能够接收Post请求的Http API,Post请求参数形式如下:
NameValuePair[] data = {
new NameValuePair("message", message.getTransferObjectJSON()),
new NameValuePair("messageName", message.getMessageName()),
new NameValuePair("tag", message.getCustomTag()),
};
2) 该API的返回值要求为JSON串,内容要求如下(responseCode:0表示处理成功,小于0表示系统异常,大于0表示业务异常):
"{exceptionMessgage:null, responseCode:0}"
3) 将该API的Url配置到MessageConsumersConfig表中
下面是一个简单的实例:
@Controller
public class ConsumerController {
private static final Logger logger = Logger.getLogger(ConsumerController.class);
@RequestMapping(value = "testmsgconsumer", method=RequestMethod.POST)
@ResponseBody
public String LogMessage(HttpServletRequest request) {
logger.info(request.getParameter("messageName") + "(" + request.getParameter("tag") + "): " + request.getParameter("message"));
return "{exceptionMessgage:null, responseCode:0}";
}
}
RabbitMQ组成及原理介绍-3
rabbitmq作为成熟的企业消息中间件,实现了应用程序间接口调用的解耦,提高系统的吞吐量。
1.RabbitMQ组成
- 是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的 Erlang 写成,因此也是继承了这些优点。
- AMQP 里主要要说两个组件:Exchange 和 Queue (在 AMQP 1.0 里还会有变动),如下图所示,绿色的 X 就是 Exchange ,红色的是 Queue ,这两者都在 Server 端,又称作 Broker ,这部分是 RabbitMQ 实现的,而蓝色的则是客户端,通常有 Producer 和 Consumer 两种类型:
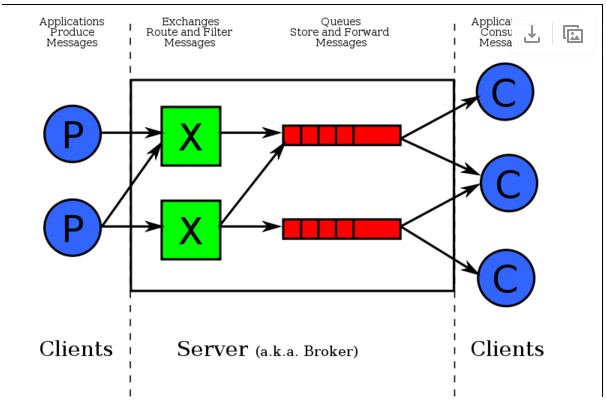
- RabbitMQ Server: 也叫broker server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQ isn’t a food truck, it’s a delivery service. 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
- Client A & B: 也叫Producer,数据的发送方。create messages and publish (send) them to a broker server (RabbitMQ).一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
- Client 1,2,3:也叫Consumer,数据的接收方。Consumers attach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
- Exchanges are where producers publish their messages.
- Queues are where the messages end up and are received by consumers
- Bindings are how the messages get routed from the exchange to particular queues.
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
- Connection: 就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
- Channels: 虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
-
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
Exchange
Exchange是属于Vhost的。同一个Vhost不能有重复的Exchange名称。 Exhange有四种类型:fanout,Direct,header,topic。
Exchange接受Producer发送的Message并根据不同路由算法将Message发送到Message Queue。
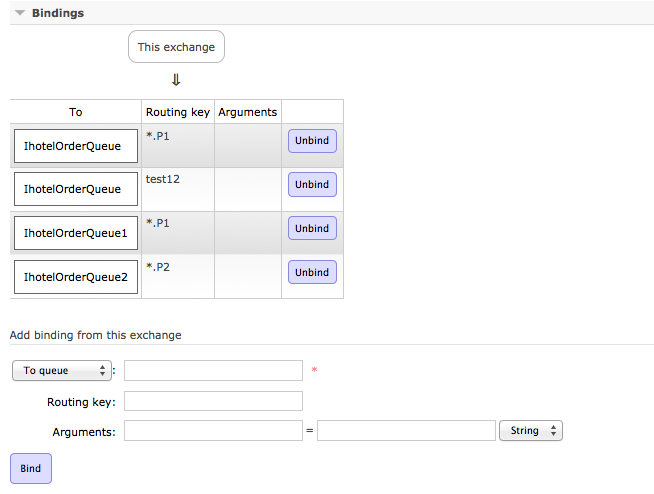
从架构图可以看出,Procuder Publish的Message进入了Exchange。接着通过“routing keys”, RabbitMQ会找到应该把这个Message放到哪个queue里。queue也是通过这个routing keys来做的绑定。
Exchange的绑定功能,可以绑定queue,也可以绑定Exchange。这个看具体业务了。如果绑定数据,需要在分发或者重新被分派,使用To Exchange绑定。如果要被直接处理,使用queue绑定。如果Exchange绑定了Queue,如果Route Key不对,也会导致数据不可达,被丢掉。(一个数据可以被Queue处理,需要Exchange绑定Queue,并且在Message发送的时候,Route Key 与绑定的Key相等。我们发送一个空数据,Route Key随便制定了Hello,消息虽然发送,但是客户获得失败。
有四种类型的Exchanges:direct, fanout,topic。 每个实现了不同的路由算法(routing algorithm)。
- Direct exchange: 如果 routing key 匹配, 那么Message就会被传递到相应的queue中。其实在queue创建时,它会自动的以queue的名字 作为routing key来绑定那个exchange。(转发消息到routigKey指定的队列)
- Fanout exchange: 会向响应的queue广播。(转发消息到所有绑定队列)
- Topic exchange: 对key进行模式匹配,比如ab*可以传递到所有ab*的queue。(按规则转发消息(最灵活))
Queue:
Message Queue会在Message不能被正常消费时将其缓存起来,但是当Consumer与Message Queue之间的连接通畅时,Message Queue将Message转发给Consumer。
Message由Header和Body组成,Header是由Producer添加的各种属性的集合,包括Message是否客被缓存、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
Exchange与Message Queue之间的关联通过Binding来实现。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。

Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。
Exchange Type分为Direct(单播)、Topic(组播)、Fanout(广播)。当为Direct(单播)时,Routing Key必须与Binding Key相等时才能匹配成功,当为Topic(组播)时,Routing Key与Binding Key符合一种模式关系即算匹配成功,当为Fanout(广播)时,不受限制。默认Exchange Type是Direct(单播)。
routing:exchange和queue之间绑定的媒介,成为routing key。
message acknowledgment: 消息确认,解决消息确认问题,只有收到ack之后才能从消息系统中删除。
message durability: 消息持久化,当rabbitmq退出或崩溃后,会把queue中的消息持久化。但注意,RabbitMQ并不能百分之百保证消息一定不会丢失,因为为了提 升性能,RabbitMQ会把消息暂存在内存缓存中,直到达到阀值才会批量持久化到磁盘,也就是说如果在持久化到磁盘之前RabbitMQ崩溃了,那么就 会丢失一小部分数据,这对于大多数场景来说并不是不可接受的,如果确实需要保证任务绝对不丢失,那么应该使用事务机制。
Virtual hosts
每个virtual host本质上都是一个RabbitMQ Server,拥有它自己的queue,exchange,和bind rule等等。这保证了你可以在多个不同的application中使用RabbitMQ。
RabbitMQ的Vhost主要是用来划分不同业务模块。不同业务模块之间没有信息交互。Vhost之间相互完全隔离,不同Vhost之间无法共享Exchange和Queue。因此Vhost之间数据无法共享和分享。如果要实现这种功能,需要Vhost之间手动构建对应代码逻辑。

Vhost其实在用户之间是透明的,Vhost可以被多个用户访问,而一个用户可以同时访问多个Vhost。 例如:peter可以同时访问"/"和"/vhost"。
Virtual Host是个虚拟概念,可以持有一些Exchange和Message Queue。一个Virtual Host可以是一台服务器,也可以是由多台服务器组成的集群。Exchange和Message Queue可以分别部署在一台或者多台服务器上。