一、大数据介绍
(一)大数据趋势
- 不局限于Hadoop,格局小了
- 还有Cloud作为存储平台(new data lake)
- 使用Nosql接管
- hbase mongodb cassandra
- Spark & ML
- 流式处理 + 批处理 => 结合
- Spark 2.0+ & Flink 1.9+
- Variety -> drives big data(最重要)
- 最终都要转成结构化数据
- 实时处理&分析成为主流
-
Spark-Streaming/Kafka-Streaming/Flink-Streaming
-
- 数据仓库 & BI is getting hotter
- cloud -> new Data Lake
(二)数据来源
- 商务数据
- logs
- 合伙人数据
- 爬虫
- 会议
- 短信
- 消息板
- IOT/machine data 设备数据(使用水电的情况调整价格)
(三)大数据工具

二、系统概述
(一)项目介绍
① 项目链接:https://www.kaggle.com/c/event-recommendation-engine-challenge
② 项目描述:使用actions,event,人口数据 => 预测users会对哪些events感兴趣
③ 项目需求:
- 建模预测每个人感兴趣的events
- 对今后events提出指导方针
- 可视化反映users的兴趣和age/gender/...的关系
④ 项目背景:
周期性的产生数据

⑤ 项目定义:
- new data -> train data 更新 -> model应该重建 & 优化
- train data可能alone & come with 其他数据
- data cleaning 有必要
- 商业驱动:快速了解用户对即将到来的events的兴趣,并根据预测结果来调整events的内容
- 预测后,用户的兴趣与age/gender/events的分类/events发生时间等会被可视化
- 所有任务均自动化
(二)项目方案
一、 数据模型
二、 应用架构
方案一:Oozie自动化


flume:定时吞吐 -> kafka削峰,正则过滤 -> 再到kafka(用kafka streaming变换如下) (流不等于实时流)

-> 存储 -> hive来映射hbase(多列组合)-> pyspark ml -> model存储到hadoop
hive -> 维度表 -> 进入mysql
第二轮mysql通过ML model预测数据 获得事实表
方案二:nifi自动化


(三)项目目录
- 项目介绍
- 企业数据湖
- 数据抽取:Kafka/NiFi/Flume
- 数据存储:HBase/Cassandra/MongoDB
- 数据变换:Hive/Spark SQL
- 协调管理ETL工作流:Oozie
- 介绍推荐系统 & ML
- 建user-interest预测模型 & 使用ML pipeline预测
- 可视化BI model:Tableau
- 数据监管:Atlas
- Redis介绍
(四)使用工具
- HDFS
- kafka/NiFi/Flume
- HBase/Hive
- Spark/Spark ML
- Cassandra/MongoDB/Redis
- BI Tool Integration
- Atlas
三、数据湖介绍
>>>
国内情况:
- 阿里:“数据中台”,倾向数仓的吞吐管理+软件的管理
- 华为:“数据工厂”,倾向数据湖
<<<
(一)什么是数据湖?
--大型存储仓库和处理环境
--企业范围内的数据管理平台,分析来自不同数据源的源数据
- 先load data进Hadoop平台,数据分析/挖掘基于此
- 构建数据湖是公司开展业务的第一步
国内:Application-Driven(基于应用的数据)
国外:Data-Drivem(先有数据后有应用)
(二)数据湖 vs Hadoop
-
数据湖是一种系统中存储的方法论,便于整合各种结构形式的数据
-
包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)
-
- Hadoop是一种数据湖的实现。
- 其他实现有Azure Data Lake Store/Cloud计算环境
(三)3 key attributes
- Collect everthing: raw data & processed data(标准化/临时表)
- Dive in anywhere:可以在任何地方找到数据
- Flexible access:数据湖支持跨共享基础设施的多种数据访问模式:批处理、交互式、在线、搜索、内存中和其他处理引擎
- 有权限的管理数据
(四)EDW VS EDL
一、传统EDW(数据仓库)
- 设计,收集需求
- 数据模型
- facts and dimensions
- ETL >>> extract/transform/load data to warehouese
- BI tools -> reports
二、EDW和EDL对比
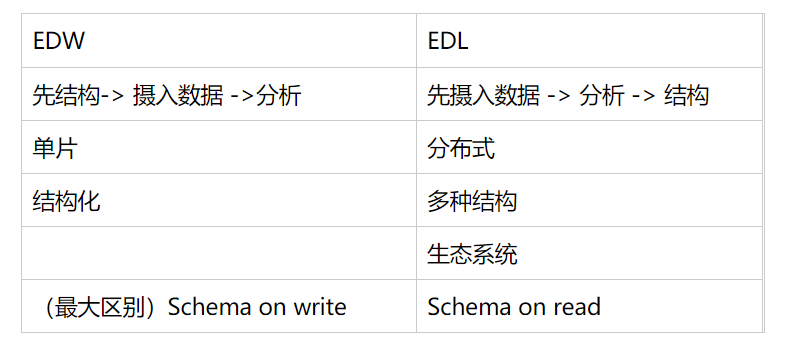
三、why USE EDL?
EDW :
-
数据过时
-
EDW可以针对主题,直接捞数据,查的快 (企业可以结合EDL+多个EDW)
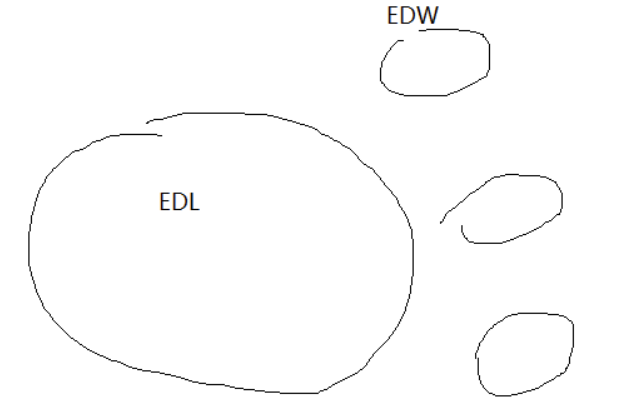
EDL :
-
容易数据集成
-
不利于实时查数据
-
adapt easily to changes
四、企业架构
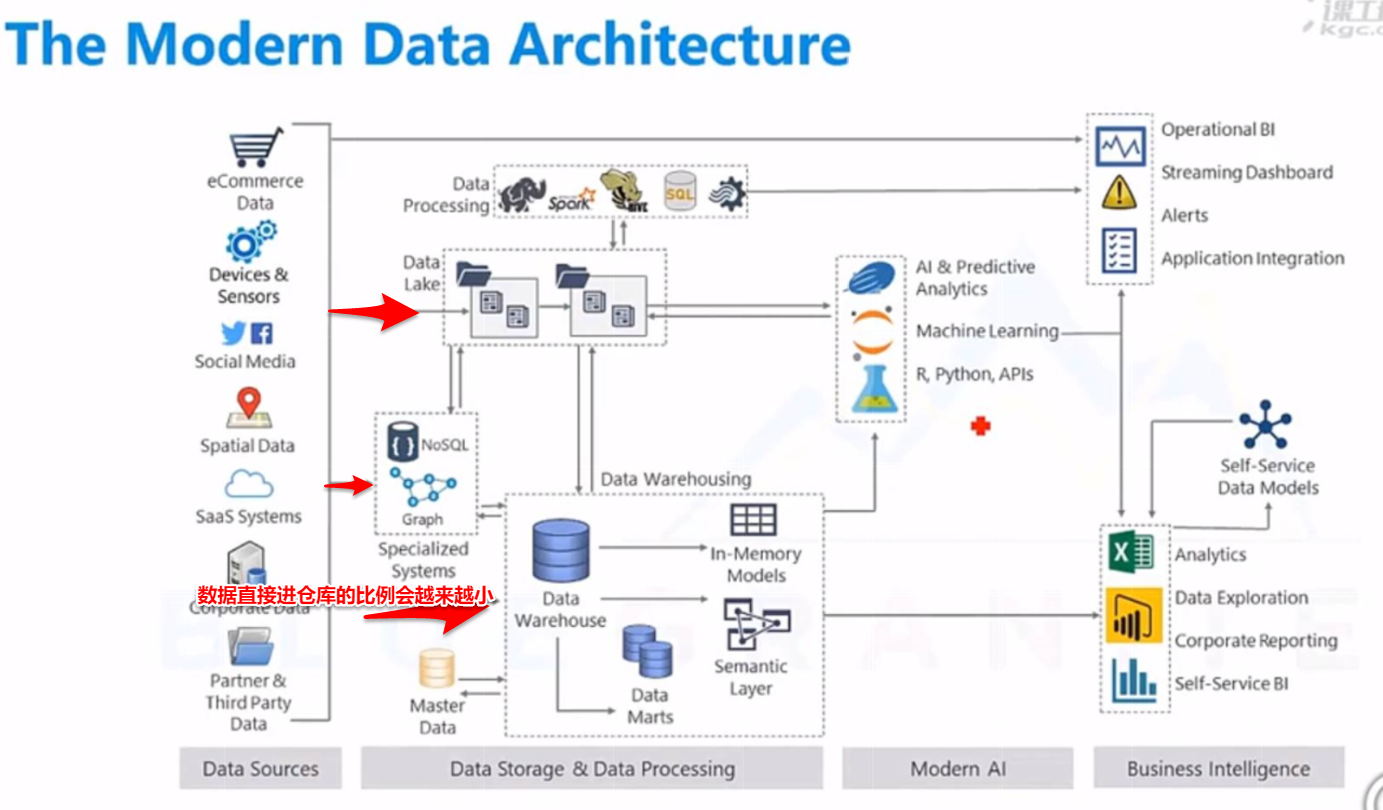
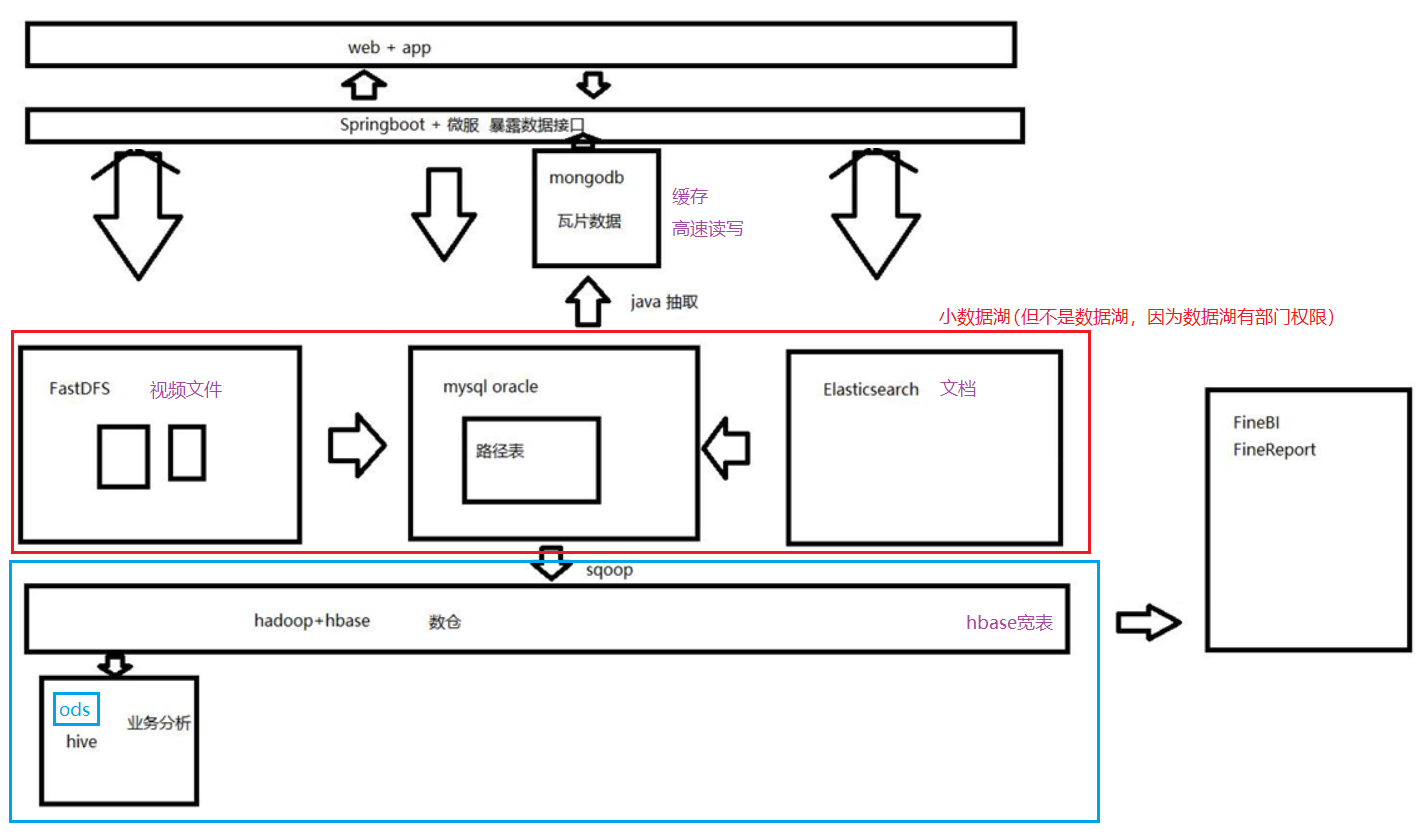
(五)分层
一、物理分层
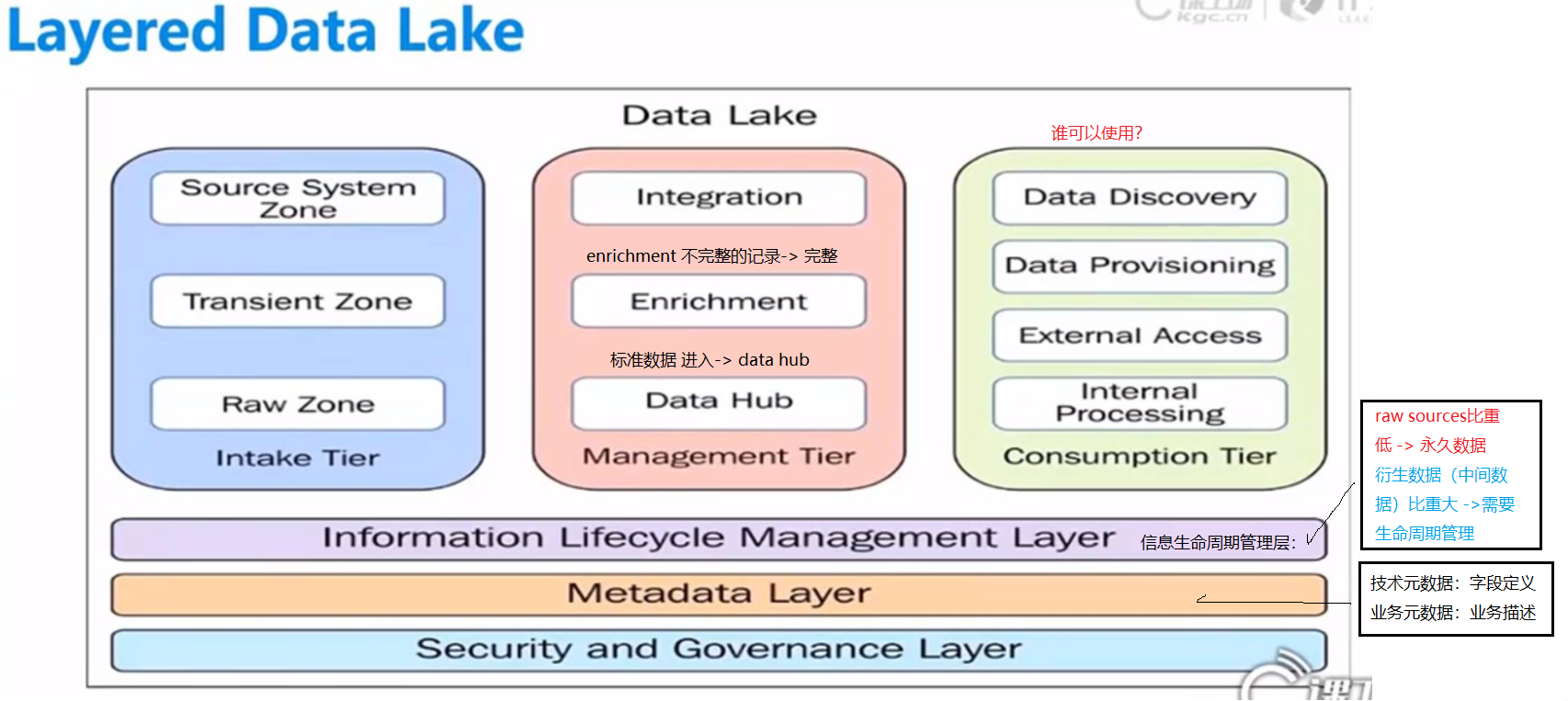
二、数据分层
数据导入-> 验证, -> 数据公开 ->数据转化
原始数据录入 public 抽取
catalog 分类
数据安全性处理 protect 对字段加密
