ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。查询官方文档
基础概念
Near Realtime (NRT)
Elasticsearch是一个近乎实时的搜索平台。这意味着从索引文档到可以搜索的时间只有轻微的延迟(通常是1秒)。
Cluster
集群是一个或多个节点(服务器)的集合,它们共同保存你的整个数据,并提供跨所有节点的联合索引和搜索功能。一个集群由一个唯一的名称标识,默认这个唯一标识的名称是"elasticsearch"。这个名称很重要,因为如果节点被设置为按其名称加入集群,那么节点只能是集群的一部分。确保不要在不同的环境中用相同的集群名称,否则可能导致节点加入到错误的集群中。
Node
节点是一个单独的服务器,它是集群的一部分,存储数据,并参与集群的索引和搜索功能。就像集群一样,节点由一个名称来标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符(UUID)。如果不想用默认的节点名,可以定义任何想要的节点名。这个名称对于管理来说很重要,因为你希望识别网络中的哪些服务器对应于你的Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称来加入到一个特定的集群中。默认情况下,每个节点都被设置加入到一个名字叫"elasticsearch"的集群中,这就意味着如果你启动了很多个节点,并且假设它们彼此可以互相发现,那么它们将自动形成并加入到一个名为"elasticsearch"的集群中。
一个集群可以有任意数量的节点。此外,如果在你的网络上当前没有运行任何节点,那么此时启动一个节点将默认形成一个单节点的名字叫"elasticsearch"的集群。
Index
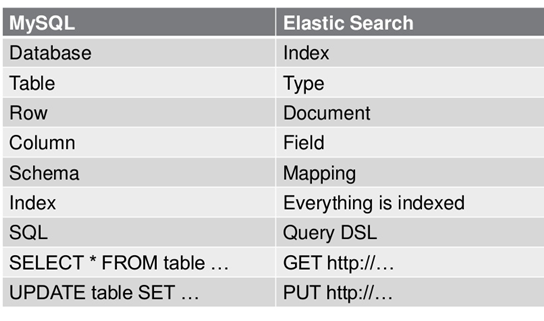
索引是具有某种相似特征的文档的集合。例如,你可以有一个顾客数据索引,产品目录索引和订单数据索引。索引有一个名称(必须是小写的)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在一个集群中,可以定义任意多的索引。可类比mysql中的数据库
Mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。相当于mysql中的创建表的过程,设置主键外键等等
Type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。 可类比mysql中的表
Document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。 插入索引库以文档为单位,类比与数据库中的一行数据
Filed
对文档数据根据不同属性进行的分类标识 。相当于是数据表的字段。
Shards
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的
Replicas
为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片
数据概念
7.x 已经移除Type概念。
Docker安装ElasticSearch
1.登录docker官网查询版本elasticsearch版本
https://hub.docker.com/_/elasticsearch?tab=tags&page=1&ordering=last_updated
2.通过docker拉取镜像
root@ryj-dev10:/home/wuh151# docker pull elasticsearch:7.10.1 7.10.1: Pulling from library/elasticsearch ...... Status: Downloaded newer image for elasticsearch:7.10.1 docker.io/library/elasticsearch:7.10.1 root@ryj-dev10:/home/wuh151# docker image list REPOSITORY TAG IMAGE ID CREATED SIZE mysql latest ab2f358b8612 3 weeks ago 545MB elasticsearch 7.10.1 558380375f1a 4 weeks ago 774MB harbor.lingda.com/common/java 8-jre-alpine fdc893b19a14 3 years ago 108MB
3.启动
root@ryj-dev10:/home/wuh151# docker run --name es -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.10.1 7f6a80868acc55b90f2c9333b4f270ce61c8a0f9828019c407a22c34668e7a23 root@ryj-dev10:/home/wuh151# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7f6a80868acc elasticsearch:7.10.1 "/tini -- /usr/local…" 12 seconds ago Up 10 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp es
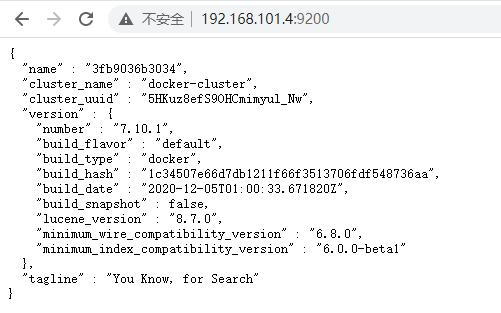
4.验证