Char2 XML
解析器:读入一个文件,确认其具有正确的格式,然后将其分解成各种元素,使程序员能够访问这些元素。
java库提供了两种XML解析器:DOM和SAX,即文档对象模型和流机制解析器。
DOM不适合处理太长的XML,考虑到内存的消耗。
如果只对XML中的某些元素感兴趣,而不关心上下文,考虑用SAX。
DOM解析器的接口已经被W3C标准化了,org.w3c.dom包中包含了这些接口类型的定义,比如Document和Element等。不同的组织都提供了实现这些接口的DOM解析器,如Apache和IBM。我们可以通过JAXP(Java API for XML Processing)库以插件的方式使用这些解析器中的任意一个。JDK本身也有自己的DOM解析器。本章就使用这个。所以,我们只要通过实现以上的接口或类就能达到使用解析器的目的。
以下是读入一个XML文档的方式:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder(); //这个就是解析器对象啦
书里说了三种XML的来源,File、URL、InputStream:
FIle f = ...
Document doc = builder.parse(f);
URL u = ...
Document doc = builder.parse(u);
InputStream in = ...
Document doc = builder.parse(in);
需要注意的是,如果以InputStream为输入源,当XML中有用到DTD等以该XML的位置为相对路径的引用时,解析器将无法定位这个DTD等文档。需要安装一个“实体解析器”(entity resolver)来解决这个问题。
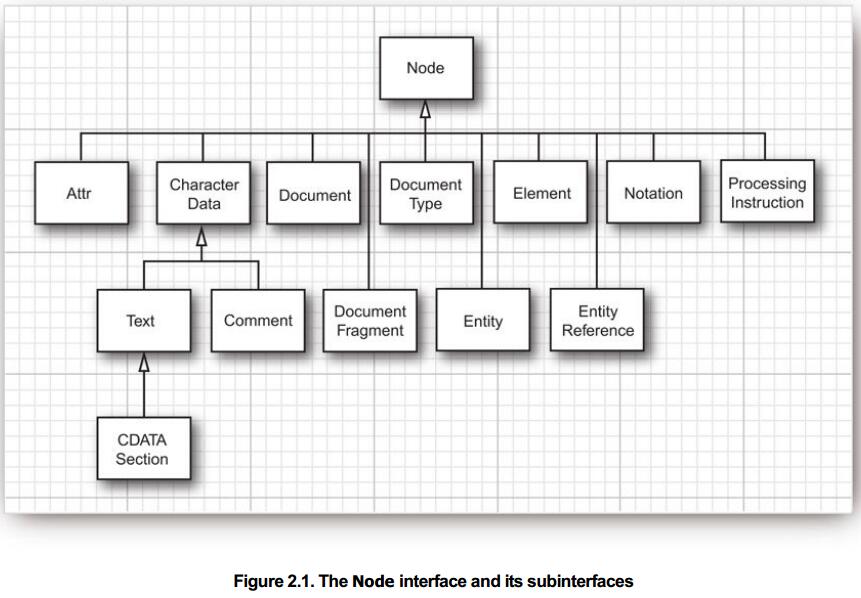
接下来就是解析Document对象各个部分的事了,具体看这个图:
例如,处理下面的文档:
<?xml version="1.0"?>
<font>
<name>Zhangsan</name>
<size>33</size>
</font>
Element root = doc.getDocumentElement(); //返回根元素font
root.getTagName(); //返回字符串"font"
获得该元素的子元素:
NodeList children = root.getChildNodes();
for(int i=0;i<children.getLength();i++){
Node child = children.item(i);
...
}
其中,getLength()=5而不是2,为啥?因为子元素与主元素之间、子元素与子元素之间空格也算了。如果只希望得到子元素,可以这样处理:
NodeList children = root.getChildNodes();
for(int i=0;i<children.getLength();i++){
Node child = children.item(i);
if(child instanceof Element){
Element childElement = (Element)child;
...
}
}
这样处理还是很麻烦的,这就是为啥后面要引入DTD的原因了,DTD能后对XML的内容进行规范处理,减少一些不必要的验证过程。
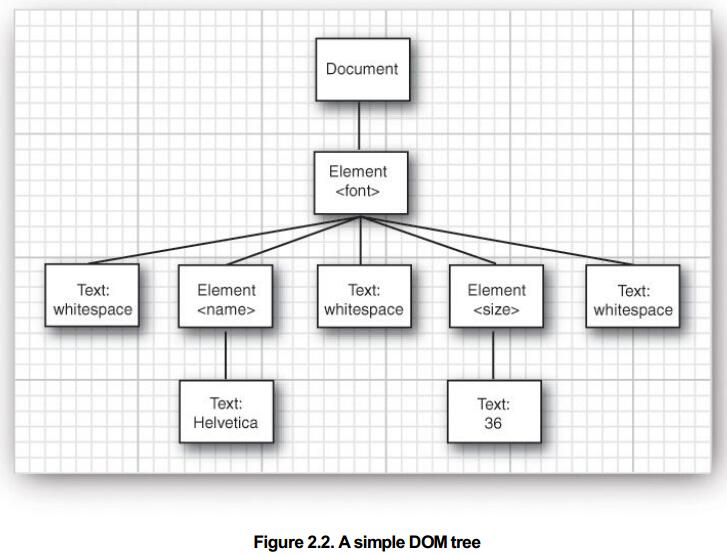
我们看上面的图,其中包括空白子元素,是Text类型的,另外,发现没?name和size的值也是Text类型的,所以,怎么样获得Zhangsan、33这两个值呢?自然通过Text类型的对象来处理:
for(int i=0;i<children.getLength();i++){
Node child = children.item(i);
if(child instanceof Element){
Element childElement = (Element) child;
Text textNode = (Text) childElement.getFirstChild();
String text = textNode.getData().trim();
if(childElement.getTagName().equals("name")){
name = text;
}else if(childElement.getTagName().equals(size")){
size = Integer.parseInt(text);
}
}
}
上面用到trim()是为了避免下面格式产生的空格:
<size>
33
</size>
这种情况下,解析器会把所有的换行符和空格都包含到Text中去。
最后一部分是获取XML中元素属性对象,直接上代码:
NameNodeMap attributes = element.getAttributes();
for(int i=0;i<attributes.getLength();i++){
Node attribute = attributes.item(i);
String name = attribute.getNodeName(); //属性名
String value = attribute.getNodeValue(); //属性值
}