一、前言
文章:https://www.cnblogs.com/runnable/p/12905401.html中介绍了Tomcat处理一次请求的大致过程,其中包括请求接收、请求数据处理以及请求响应。接下来用两篇文章详细分析请求数据解析:请求行和请求头的读取、请求体的读取。
在分析请求数据处理之前,再次回顾一下2个概念
1、Tomcat中用于读取socket数据的缓冲区buf。它是一个字节数组,默认长度8KB。有2个重要的位置下标:pos和lastValid,pos标记下次读取位置,lastValid标记有效数据最后位置。
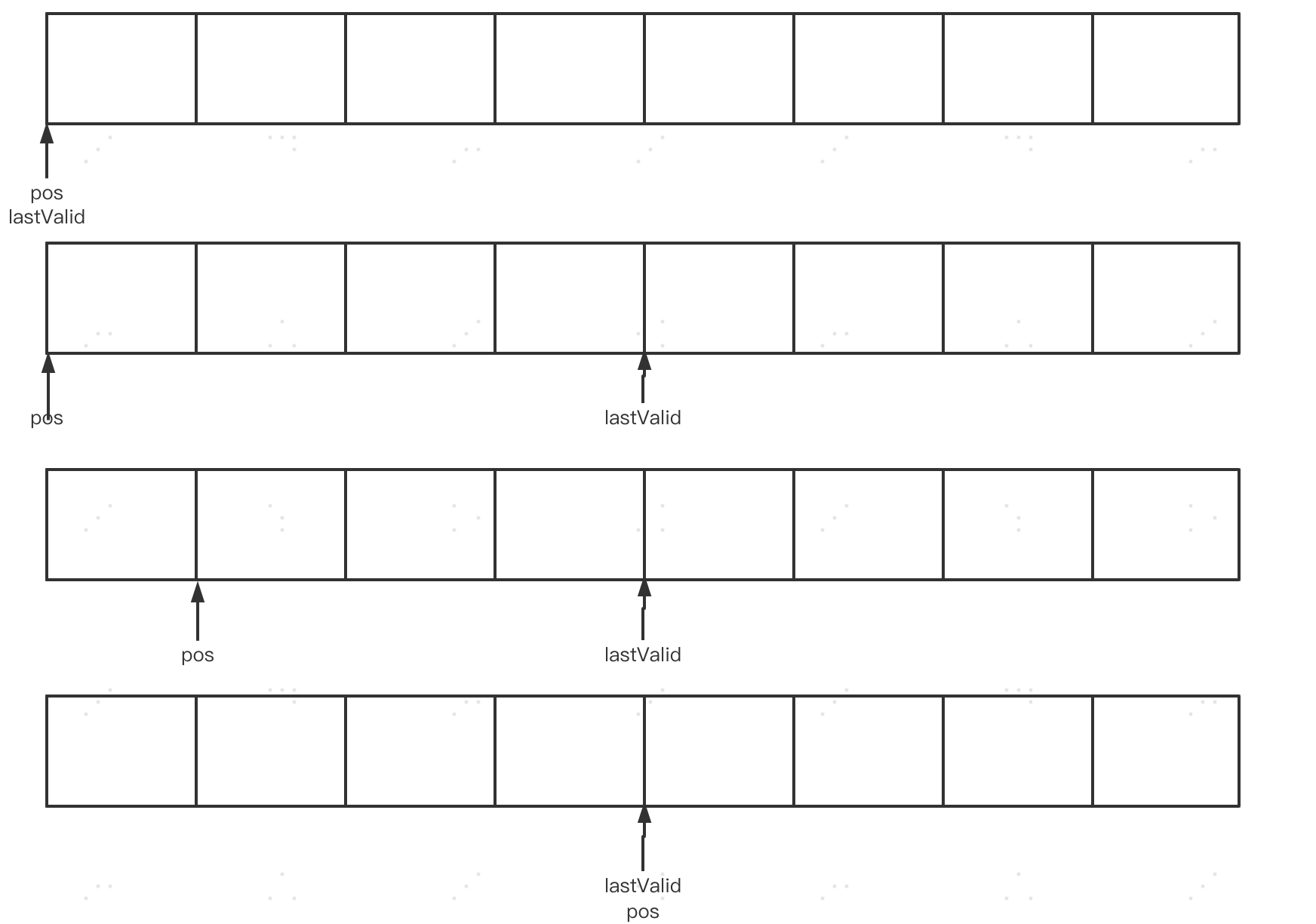
图中4种情况分别对应:初始数组;刚从操作系统中读取数据到buf;Tomcat解析过程中,已经读取第一位字节;本次从操作系统读取的数据已经全部解析完。
Tomcat中对请求数据的处理,其实就是重复这四个这个过程,把数据从操作系统读取到Tomcat缓存,然后逐个字节进行解析。我们后面详细分析。
2、字节块(ByteChunk),一种数据结构。有三个重要属性:字节数组buff,start,end。我们从三个属性可以看出,字节块是利用两个下标,标记了一个字节数组中的一段字节。在数据被使用时才把标记的字节转换成字符串,且相同的字节段,如果已经有字符串对应,则会共用该字符串。这样做最大的好处是提高效率、减少内存使用。如下图标记了字节块下标1-4的字节。

3、HTTP请求数据格式如下
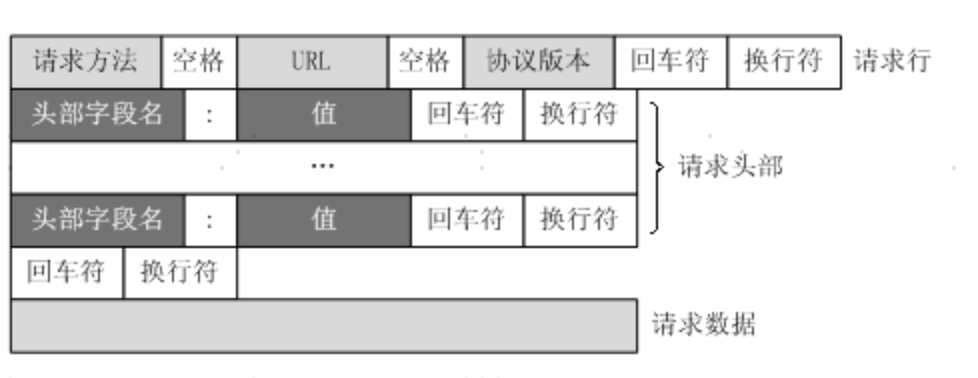
整个请求数据的解析过程实际就是根据HTTP规范逐个字节分析,最终转换成请求对象的过程,因此有必要对HTTP格式有了解
下面我们进入主题,通过源码分析请求行和请求头的解析过程
首先进入HTTP11处理器中处理请求的入口:


1 @Override 2 public SocketState process(SocketWrapper<S> socketWrapper) 3 throws IOException { 4 RequestInfo rp = request.getRequestProcessor(); 5 rp.setStage(org.apache.coyote.Constants.STAGE_PARSE); 6 7 // Setting up the I/O 8 setSocketWrapper(socketWrapper); 9 /** 10 * 设置socket的InputStream和OutStream,供后面读取数据和响应使用 11 */ 12 getInputBuffer().init(socketWrapper, endpoint); 13 getOutputBuffer().init(socketWrapper, endpoint); 14 15 // Flags 16 keepAlive = true; 17 comet = false; 18 openSocket = false; 19 sendfileInProgress = false; 20 readComplete = true; 21 if (endpoint.getUsePolling()) { 22 keptAlive = false; 23 } else { 24 keptAlive = socketWrapper.isKeptAlive(); 25 } 26 27 /** 28 * 长连接相关,判断当前socket是否继续处理接下来的请求 29 */ 30 if (disableKeepAlive()) { 31 socketWrapper.setKeepAliveLeft(0); 32 } 33 34 /** 35 * 处理socket中的请求,在长连接的模式下,每次循环表示一个HTTP请求 36 */ 37 while (!getErrorState().isError() && keepAlive && !comet && !isAsync() && 38 upgradeInbound == null && 39 httpUpgradeHandler == null && !endpoint.isPaused()) { 40 41 // Parsing the request header 42 try { 43 /** 44 * 1、设置socket超时时间 45 * 2、第一次从socket中读取数据 46 */ 47 setRequestLineReadTimeout(); 48 49 /** 50 * 读取请求行 51 */ 52 if (!getInputBuffer().parseRequestLine(keptAlive)) { 53 if (handleIncompleteRequestLineRead()) { 54 break; 55 } 56 } 57 58 // Process the Protocol component of the request line 59 // Need to know if this is an HTTP 0.9 request before trying to 60 // parse headers. 61 prepareRequestProtocol(); 62 63 if (endpoint.isPaused()) { 64 // 503 - Service unavailable 65 response.setStatus(503); 66 setErrorState(ErrorState.CLOSE_CLEAN, null); 67 } else { 68 keptAlive = true; 69 // Set this every time in case limit has been changed via JMX 70 // 设置请求头数量 71 request.getMimeHeaders().setLimit(endpoint.getMaxHeaderCount()); 72 // 设置做多可设置cookie数量 73 request.getCookies().setLimit(getMaxCookieCount()); 74 // Currently only NIO will ever return false here 75 // Don't parse headers for HTTP/0.9 76 /** 77 * 读取请求头 78 */ 79 if (!http09 && !getInputBuffer().parseHeaders()) { 80 // We've read part of the request, don't recycle it 81 // instead associate it with the socket 82 openSocket = true; 83 readComplete = false; 84 break; 85 } 86 if (!disableUploadTimeout) { 87 setSocketTimeout(connectionUploadTimeout); 88 } 89 } 90 } catch (IOException e) { 91 if (getLog().isDebugEnabled()) { 92 getLog().debug( 93 sm.getString("http11processor.header.parse"), e); 94 } 95 setErrorState(ErrorState.CLOSE_NOW, e); 96 break; 97 } catch (Throwable t) { 98 ExceptionUtils.handleThrowable(t); 99 UserDataHelper.Mode logMode = userDataHelper.getNextMode(); 100 if (logMode != null) { 101 String message = sm.getString( 102 "http11processor.header.parse"); 103 switch (logMode) { 104 case INFO_THEN_DEBUG: 105 message += sm.getString( 106 "http11processor.fallToDebug"); 107 //$FALL-THROUGH$ 108 case INFO: 109 getLog().info(message, t); 110 break; 111 case DEBUG: 112 getLog().debug(message, t); 113 } 114 } 115 // 400 - Bad Request 116 response.setStatus(400); 117 setErrorState(ErrorState.CLOSE_CLEAN, t); 118 getAdapter().log(request, response, 0); 119 } 120 121 if (!getErrorState().isError()) { 122 // Setting up filters, and parse some request headers 123 rp.setStage(org.apache.coyote.Constants.STAGE_PREPARE); 124 try { 125 prepareRequest(); 126 } catch (Throwable t) { 127 ExceptionUtils.handleThrowable(t); 128 if (getLog().isDebugEnabled()) { 129 getLog().debug(sm.getString( 130 "http11processor.request.prepare"), t); 131 } 132 // 500 - Internal Server Error 133 response.setStatus(500); 134 setErrorState(ErrorState.CLOSE_CLEAN, t); 135 getAdapter().log(request, response, 0); 136 } 137 } 138 139 if (maxKeepAliveRequests == 1) { 140 keepAlive = false; 141 } else if (maxKeepAliveRequests > 0 && 142 socketWrapper.decrementKeepAlive() <= 0) { 143 keepAlive = false; 144 } 145 146 // Process the request in the adapter 147 if (!getErrorState().isError()) { 148 try { 149 rp.setStage(org.apache.coyote.Constants.STAGE_SERVICE); 150 /** 151 * 将封装好的请求和响应对象,交由容器处理 152 * service-->host-->context-->wrapper-->servlet 153 * 这里非常重要,我们所写的servlet代码正是这里在调用,它遵循了Servlet规范 154 * 这里处理完,代表程序员开发的servlet已经执行完毕 155 */ 156 adapter.service(request, response); 157 // Handle when the response was committed before a serious 158 // error occurred. Throwing a ServletException should both 159 // set the status to 500 and set the errorException. 160 // If we fail here, then the response is likely already 161 // committed, so we can't try and set headers. 162 if(keepAlive && !getErrorState().isError() && ( 163 response.getErrorException() != null || 164 (!isAsync() && 165 statusDropsConnection(response.getStatus())))) { 166 setErrorState(ErrorState.CLOSE_CLEAN, null); 167 } 168 setCometTimeouts(socketWrapper); 169 } catch (InterruptedIOException e) { 170 setErrorState(ErrorState.CLOSE_NOW, e); 171 } catch (HeadersTooLargeException e) { 172 getLog().error(sm.getString("http11processor.request.process"), e); 173 // The response should not have been committed but check it 174 // anyway to be safe 175 if (response.isCommitted()) { 176 setErrorState(ErrorState.CLOSE_NOW, e); 177 } else { 178 response.reset(); 179 response.setStatus(500); 180 setErrorState(ErrorState.CLOSE_CLEAN, e); 181 response.setHeader("Connection", "close"); // TODO: Remove 182 } 183 } catch (Throwable t) { 184 ExceptionUtils.handleThrowable(t); 185 getLog().error(sm.getString("http11processor.request.process"), t); 186 // 500 - Internal Server Error 187 response.setStatus(500); 188 setErrorState(ErrorState.CLOSE_CLEAN, t); 189 getAdapter().log(request, response, 0); 190 } 191 } 192 193 // Finish the handling of the request 194 rp.setStage(org.apache.coyote.Constants.STAGE_ENDINPUT); 195 196 if (!isAsync() && !comet) { 197 if (getErrorState().isError()) { 198 // If we know we are closing the connection, don't drain 199 // input. This way uploading a 100GB file doesn't tie up the 200 // thread if the servlet has rejected it. 201 getInputBuffer().setSwallowInput(false); 202 } else { 203 // Need to check this again here in case the response was 204 // committed before the error that requires the connection 205 // to be closed occurred. 206 checkExpectationAndResponseStatus(); 207 } 208 /** 209 * 请求收尾工作 210 * 判断请求体是否读取完毕,没有则读取完毕,并修正pos 211 * 请求体读取分为两种: 212 * 1、程序员读取:在servlet中有程序员主动读取,这种方式读取数据不一定读取完整数据,取决于业务需求 213 * 2、Tomcat自己读取:如果servlet中没有读取,或者没有读取完全,则Tomcat负责读取剩余的请求体 214 * 1和2的差别在于,2中仅仅把数据从操作系统读取到buf中,尽管也用了字节块做标记,但是不会做其他的事情,而1中还会把字节块标记的数据拷贝到目标数组中 215 * 这个方法就是处理情况2中的请求体读取逻辑 216 */ 217 endRequest(); 218 } 219 220 rp.setStage(org.apache.coyote.Constants.STAGE_ENDOUTPUT); 221 222 // If there was an error, make sure the request is counted as 223 // and error, and update the statistics counter 224 if (getErrorState().isError()) { 225 response.setStatus(500); 226 } 227 request.updateCounters(); 228 229 if (!isAsync() && !comet || getErrorState().isError()) { 230 if (getErrorState().isIoAllowed()) { 231 /** 232 * 根据修正完的pos和lastValid,初始化数组下标,以便继续处理下一次请求 233 * 两种情况 234 * 1、读取请求体刚好读取完,将pos=lastValid=0,即都指向buf数组第一个位置,重新读取数据 235 * 2、读取请求体多读出了下次请求的数据,这个时候需要将下个请求的数据移动到buf数组头,以便处理下个请求 236 * 注意,buf数组中的数据没有删除,是直接覆盖,从而达到对buf数组的重复使用 237 */ 238 getInputBuffer().nextRequest(); 239 getOutputBuffer().nextRequest(); 240 } 241 } 242 243 if (!disableUploadTimeout) { 244 if(endpoint.getSoTimeout() > 0) { 245 setSocketTimeout(endpoint.getSoTimeout()); 246 } else { 247 setSocketTimeout(0); 248 } 249 } 250 251 rp.setStage(org.apache.coyote.Constants.STAGE_KEEPALIVE); 252 253 if (breakKeepAliveLoop(socketWrapper)) { 254 break; 255 } 256 } 257 258 rp.setStage(org.apache.coyote.Constants.STAGE_ENDED); 259 260 if (getErrorState().isError() || endpoint.isPaused()) { 261 return SocketState.CLOSED; 262 } else if (isAsync() || comet) { 263 return SocketState.LONG; 264 } else if (isUpgrade()) { 265 return SocketState.UPGRADING; 266 } else if (getUpgradeInbound() != null) { 267 return SocketState.UPGRADING_TOMCAT; 268 } else { 269 if (sendfileInProgress) { 270 return SocketState.SENDFILE; 271 } else { 272 if (openSocket) { 273 if (readComplete) { 274 return SocketState.OPEN; 275 } else { 276 return SocketState.LONG; 277 } 278 } else { 279 return SocketState.CLOSED; 280 } 281 } 282 } 283 }
分析:
上述方法展示整个请求处理的核心过程,其中52行开始处理请求行:getInputBuffer().parseRequestLine(keptAlive)
二、请求行解析
具体方法如下:
1 /** 2 * Read the request line. This function is meant to be used during the 3 * HTTP request header parsing. Do NOT attempt to read the request body 4 * using it. 5 * 6 * @throws IOException If an exception occurs during the underlying socket 7 * read operations, or if the given buffer is not big enough to accommodate 8 * the whole line. 9 */ 10 /** 11 * 读取请求行方法 12 * 请求行格式如下: 13 * ======================================== 14 * 请求方法 空格 URL 空格 协议版本 回车换行 15 * ======================================== 16 * @param useAvailableDataOnly 17 * @return 18 * @throws IOException 19 */ 20 @Override 21 public boolean parseRequestLine(boolean useAvailableDataOnly) 22 23 throws IOException { 24 25 int start = 0; 26 27 // 28 // Skipping blank lines 29 // 30 31 /** 32 * 过滤掉回车(CR)换行(LF)符,确定start位置 33 */ 34 do { 35 36 // Read new bytes if needed 37 if (pos >= lastValid) { 38 if (!fill()) 39 throw new EOFException(sm.getString("iib.eof.error")); 40 } 41 // Set the start time once we start reading data (even if it is 42 // just skipping blank lines) 43 if (request.getStartTime() < 0) { 44 request.setStartTime(System.currentTimeMillis()); 45 } 46 /** 47 * chr记录第一个非CRLF字节,后面读取请求头的时候用到 48 */ 49 chr = buf[pos++]; 50 } while (chr == Constants.CR || chr == Constants.LF); 51 52 pos--; 53 54 // Mark the current buffer position 55 start = pos; 56 57 // 58 // Reading the method name 59 // Method name is a token 60 // 61 62 boolean space = false; 63 64 /** 65 * 读取HTT请求方法:get/post/put.... 66 */ 67 while (!space) { 68 69 // Read new bytes if needed 70 if (pos >= lastValid) { 71 if (!fill()) 72 throw new EOFException(sm.getString("iib.eof.error")); 73 } 74 75 // Spec says method name is a token followed by a single SP but 76 // also be tolerant of multiple SP and/or HT. 77 if (buf[pos] == Constants.SP || buf[pos] == Constants.HT) { 78 space = true; 79 /** 80 * 设置HTTP请求方法,这里没有直接设置字符串,而是用了字节块ByteChunk 81 * ByteChunk中包含一个字节数据类型的属性buff,此处的setBytes方法就是将buff指向Tomcat的缓存buf。然后start和end标记为 82 * 此处方法的后两个入参,也就是将请求方法在buf中标记了出来,但是没有转换成字符串,等到使用的时候再使用ByteBuffer.wap方法 83 * 转换成字符串,且标记hasStrValue=true,如果再次获取就直接拿转换好的字符串,不用再次转换。效率考虑?牛逼! 84 * 因此,就算后面由于请求体过长,Tomcat重新开辟新的数组buf读取请求体。原buf也不会被GC,因为ByteChunk中的buff引用了原buf数组 85 * 什么时候原数组才会被GC?本次请求结束,request对象被GC后。。。 86 */ 87 request.method().setBytes(buf, start, pos - start); 88 } else if (!HttpParser.isToken(buf[pos])) { 89 String invalidMethodValue = parseInvalid(start, buf); 90 throw new IllegalArgumentException(sm.getString("iib.invalidmethod", invalidMethodValue)); 91 } 92 93 pos++; 94 95 } 96 97 // Spec says single SP but also be tolerant of multiple SP and/or HT 98 /** 99 * 过滤请求方法后面的空格(SP或者HT) 100 */ 101 while (space) { 102 // Read new bytes if needed 103 if (pos >= lastValid) { 104 if (!fill()) 105 throw new EOFException(sm.getString("iib.eof.error")); 106 } 107 if (buf[pos] == Constants.SP || buf[pos] == Constants.HT) { 108 pos++; 109 } else { 110 space = false; 111 } 112 } 113 114 // Mark the current buffer position 115 start = pos; 116 int end = 0; 117 int questionPos = -1; 118 119 // 120 // Reading the URI 121 // 122 123 boolean eol = false; 124 125 /** 126 * 读取URL 127 */ 128 while (!space) { 129 130 // Read new bytes if needed 131 if (pos >= lastValid) { 132 if (!fill()) 133 throw new EOFException(sm.getString("iib.eof.error")); 134 } 135 136 /** 137 * CR后面没有LF,不是HTTP0.9,抛异常 138 */ 139 if (buf[pos -1] == Constants.CR && buf[pos] != Constants.LF) { 140 // CR not followed by LF so not an HTTP/0.9 request and 141 // therefore invalid. Trigger error handling. 142 // Avoid unknown protocol triggering an additional error 143 request.protocol().setString(Constants.HTTP_11); 144 String invalidRequestTarget = parseInvalid(start, buf); 145 throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget)); 146 } 147 148 // Spec says single SP but it also says be tolerant of HT 149 if (buf[pos] == Constants.SP || buf[pos] == Constants.HT) { 150 /** 151 * 遇到空格(SP或者HT),URL读取结束 152 */ 153 space = true; 154 end = pos; 155 } else if (buf[pos] == Constants.CR) { 156 // HTTP/0.9 style request. CR is optional. LF is not. 157 } else if (buf[pos] == Constants.LF) { 158 // HTTP/0.9 style request 159 // Stop this processing loop 160 space = true; 161 // Set blank protocol (indicates HTTP/0.9) 162 request.protocol().setString(""); 163 // Skip the protocol processing 164 eol = true; 165 if (buf[pos - 1] == Constants.CR) { 166 end = pos - 1; 167 } else { 168 end = pos; 169 } 170 } else if ((buf[pos] == Constants.QUESTION) && (questionPos == -1)) { 171 questionPos = pos; 172 } else if (questionPos != -1 && !httpParser.isQueryRelaxed(buf[pos])) { 173 // %nn decoding will be checked at the point of decoding 174 String invalidRequestTarget = parseInvalid(start, buf); 175 throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget)); 176 } else if (httpParser.isNotRequestTargetRelaxed(buf[pos])) { 177 // This is a general check that aims to catch problems early 178 // Detailed checking of each part of the request target will 179 // happen in AbstractHttp11Processor#prepareRequest() 180 String invalidRequestTarget = parseInvalid(start, buf); 181 throw new IllegalArgumentException(sm.getString("iib.invalidRequestTarget", invalidRequestTarget)); 182 } 183 pos++; 184 } 185 /** 186 * 读取HTTP URL 187 */ 188 request.unparsedURI().setBytes(buf, start, end - start); 189 if (questionPos >= 0) { 190 /** 191 * 当有请求入参的时候 192 * 读取入参字符串 193 * 读取URI 194 */ 195 request.queryString().setBytes(buf, questionPos + 1, 196 end - questionPos - 1); 197 request.requestURI().setBytes(buf, start, questionPos - start); 198 } else { 199 /** 200 * 没有请求入参的时候,直接读取URI 201 */ 202 request.requestURI().setBytes(buf, start, end - start); 203 } 204 205 // Spec says single SP but also says be tolerant of multiple SP and/or HT 206 while (space && !eol) { 207 // Read new bytes if needed 208 if (pos >= lastValid) { 209 if (!fill()) 210 throw new EOFException(sm.getString("iib.eof.error")); 211 } 212 if (buf[pos] == Constants.SP || buf[pos] == Constants.HT) { 213 pos++; 214 } else { 215 space = false; 216 } 217 } 218 219 // Mark the current buffer position 220 start = pos; 221 end = 0; 222 223 // 224 // Reading the protocol 225 // Protocol is always "HTTP/" DIGIT "." DIGIT 226 // 227 /** 228 * 读取HTTP协议版本 229 */ 230 while (!eol) { 231 232 // Read new bytes if needed 233 if (pos >= lastValid) { 234 if (!fill()) 235 throw new EOFException(sm.getString("iib.eof.error")); 236 } 237 238 if (buf[pos] == Constants.CR) { 239 // Possible end of request line. Need LF next. 240 } else if (buf[pos - 1] == Constants.CR && buf[pos] == Constants.LF) { 241 end = pos - 1; 242 eol = true; 243 } else if (!HttpParser.isHttpProtocol(buf[pos])) { 244 String invalidProtocol = parseInvalid(start, buf); 245 throw new IllegalArgumentException(sm.getString("iib.invalidHttpProtocol", invalidProtocol)); 246 } 247 248 pos++; 249 250 } 251 252 /** 253 * 字节块标记协议版本 254 */ 255 if ((end - start) > 0) { 256 request.protocol().setBytes(buf, start, end - start); 257 } 258 259 /** 260 * 如果没有协议版本,无法处理请求,抛异常 261 */ 262 if (request.protocol().isNull()) { 263 throw new IllegalArgumentException(sm.getString("iib.invalidHttpProtocol")); 264 } 265 266 return true; 267 }
在这个方法中,其实就是请求行请求方法、url、协议版本这几个部分的读取。
分析:
34-50行:这个while循环是过滤行首的回车换行符,只要是回车换行符下标pos就往后移动一位,直到不是回车换行符,跳出循环。由于这里是先执行pos++,所以如果不满足条件,pos需要后移一位,也就是真正开始读取请求方法的位置,标记为start。
37-40行:这里是非常关键的几行代码,几乎贯穿整个请求处理部分。Tomcat接收请求,就是在接收客户端的请求数据,数据经过网络传输到Tomcat所在的服务操作系统缓冲区,Tomcat从操作系统读取到自己的缓冲区buf中。这几行代码主要就是干这个事情的。前面我们介绍了字节数在buf是通过pos和lastValid控制读取的。37行判断当pos>=lastValid,表示buf数组中读取自操作系统的数据已经解析完毕,调用fill()方法再次从操作系统读取。代码如下:
1 @Override 2 protected boolean fill(boolean block) throws IOException { 3 4 int nRead = 0; 5 6 /** 7 * 这个核心就是读取socket中数据到缓冲区buf中,循环读取,2种情况 8 * 1、请求行和请求头:不能超过缓冲区大小(默认8kb),如果超过,则抛异常,读完后将parsingHeader设置为false 9 * 2、请求行:没有任何大小限制,循环读取,如果剩下的少于4500个字节,则会重新创建buf数组,从头开始读取,直到读完位置,注意!buf原先引用的数组们,等待GC 10 */ 11 if (parsingHeader) { 12 13 /** 14 * 从socket中读取数据大于tomcat中缓冲区buf的长度,直接抛异常,这里有两点 15 * 1、这个就是我们很多时候很多人说的,get请求url不能过长的原因,其实是header和url等总大小不能超过8kb 16 * 2、这里的buf非常总要,它是InternalInputBuffer的属性,是一个字节数据,用户暂存从socket中读取的数据,比如:请求行,请求头、请求体 17 */ 18 if (lastValid == buf.length) { 19 throw new IllegalArgumentException 20 (sm.getString("iib.requestheadertoolarge.error")); 21 } 22 23 // 将socket中的数据读到缓冲区buf中,注意!这里就是BIO之所以难懂的关键所在,它会阻塞! 24 // 这个方法会阻塞,如果没有数据可读,则会一直阻塞,有数据,则移动lastValid位置 25 nRead = inputStream.read(buf, pos, buf.length - lastValid); 26 if (nRead > 0) { 27 lastValid = pos + nRead; 28 } 29 30 } else { 31 /** 32 * parsingHeader==false,请求行和请求头已经读取完毕,开始读取请求体 33 */ 34 35 if (buf.length - end < 4500) { 36 // In this case, the request header was really large, so we allocate a 37 // brand new one; the old one will get GCed when subsequent requests 38 // clear all references 39 /** 40 * 如果Tomcat缓存区buf读取完请求行和请求头后,剩余长度不足4500(可配置),新创建一个字节数组buf用于读取请求体 41 * 为什么要这么做,应该是考虑到如果剩余的数据长度较小,每次从操作系统缓存区读取的字节就比较少,读取次数就比较多? 42 * 注意,buf原先指向的字节数据会白GC么?应该不会,因为请求行和请求头有许多字节块(ByteChunk)指向了旧字节数据。 43 * 什么时候才会被GC?应该是一起request处理完毕后。 44 */ 45 buf = new byte[buf.length]; 46 end = 0; 47 } 48 /** 49 * 这里的end是请求头数据的后一位,从这里开始读取请求体数据。 50 * 从操作系统读取数据到buf中,下标pos开始,lastValid结束 51 * 注意:这里每次读取请求体数据的时候都会把pos重置为end(请求头数据的后一位)!!!!! 52 * 表示什么? 53 * 请求体数据每一次从操作系统缓存中读取到buf,然后读取到程序员自己的数组后,在下次再次从操作系统读取数据到buf时,就会把之前读取的请求体数据覆盖掉 54 * 也就是从end位置开始,后面的数据都只能读取一次,这个很重要!!! 55 * 为什么这么做?我的理解是因为请求体数据可以很大,为了单个请求不占用太大内存,所以设计成了覆盖的模式,真是秒啊! 56 */ 57 pos = end; 58 lastValid = pos; 59 60 /** 61 * 原则上这个方法要么阻塞着,要么nRead>0 62 */ 63 nRead = inputStream.read(buf, pos, buf.length - lastValid); 64 if (nRead > 0) { 65 lastValid = pos + nRead; 66 } 67 68 } 69 70 /** 71 * 注意,这里不出意外,只能返回true 72 */ 73 return (nRead > 0); 74 75 }
这个方法由两部分逻辑组成:parsingHeader=true或者false,这个变量表示读取的请求行和请求头,还是读取的请求体。变量名有点歧义,并不是只包含请求头,而是请求行和请求头。
11-30行:读取请求行和请求头数据,逻辑很简单:从操作系统读取数据到字节数组buf中,后移lastValid下标到buf数组最后一个字节的位置。在Tomcat解析完这部分数据后,会把parsingHeader置为false,且用end下标指向请求头后一个字节,以便后续可以读取请求体数据。
35-66行:读取请求体数据,逻辑比请求行和请求头读取稍微复杂点:判断buf数组剩余字节长度是否大于4500,反之重新创建数组。每次读取pos和lastValid都置为end,然后读取数据到buf数组中,lastValid后移。由于请求体数据可能比较大,且理论上没有上限限制,为了减少读取次数,buf剩余空间不能过小。每次读取数据到buf中,都是存放在end位置开始,每次都是覆盖上一次读取的数据,所以我们可以大胆猜测,请求体数据只能读取一次,程序员自己如果需要多次使用,必须自行保存。我想这是为了减少内存使用吧,你们看呢?
还有一个关键点:25行和63行代码:nRead = inputStream.read(buf, pos, buf.length - lastValid),这行代码是从操作系统读取字节,接触过socket编程的都知道read方法这里可能会阻塞的,当操作系统缓存中当前没有数据可读,等待网络传输的时候,read方法阻塞,直到有数据返回后再继续。
回到读取请求行的代码。确定好了start位置后,开始读取请求方法。
67-95行:又是一个while循环,当遇到SP或者HT时,表示请求方法已经读取完毕。
87行:将start到pos前一位用字节块进行标记,只是标记,并不会转换成字符串。具体代码:
1 /** 2 * Sets the buffer to the specified subarray of bytes. 3 * 4 * @param b the ascii bytes 5 * @param off the start offset of the bytes 6 * @param len the length of the bytes 7 */ 8 public void setBytes(byte[] b, int off, int len) { 9 buff = b; 10 start = off; 11 end = start + len; 12 isSet = true; 13 hasHashCode = false; 14 }
101-112行:继续过滤掉SP或者HT,重置start,为读取URL做准备。
128-184行:读取所有的URL字节,遇到空格退出,这里并没有标记URL.
188-203行:根据上面得出的位置标记,利用字节块对URI、URL、参数分别进行标记。
206-217行:再次对空格进行过滤,重置start,准备读取协议版本。
230-250行:读取剩余字节,遇到连续的两个字节CRLF,确定请求行结束位置。
256行:使用字节块标记协议版本。
自此,请求行解析完毕,每个部分都已经利用专门的字节块(ByteChunk)进行标记。我们看到每个循环里面都会调用fill()方法从操作系统读取数据到Tomcat缓冲区中,一次请求数据的传输不一定能够传输完毕,所以Tomcat中要始终保持读取数据的状态,这个是关键,一定要理解,否则就无法理解Tomcat对请求数据的解析过程。
三、请求头解析
再次回到处理请求的入口代码中:其中79行开始处理请求头:getInputBuffer().parseHeaders()。
1 /** 2 * Parse the HTTP headers. 3 */ 4 @Override 5 public boolean parseHeaders() 6 throws IOException { 7 /** 8 * 请求行和请求头读取的标志,如果不是请求行和请求头,进入此方法,抛异常 9 */ 10 if (!parsingHeader) { 11 throw new IllegalStateException( 12 sm.getString("iib.parseheaders.ise.error")); 13 } 14 15 /** 16 * 读取请求头,循环执行,每次循环读取请求头的一个key:value对 17 */ 18 while (parseHeader()) { 19 // Loop until we run out of headers 20 } 21 22 /** 23 * 请求头读取完毕,标志变为false,end=pos,标志此处是请求行和请求头读取完毕的位置 24 */ 25 parsingHeader = false; 26 end = pos; 27 return true; 28 }
整个parseHearders方法比较简单,分三部分逻辑:1、判断是否parsingHeader=true,不是的话抛异常。2、while循环。3、处理完毕parsingHeader=false,end=pos,为读取请求体做准备。
重点关注第二部分的循环,18行代码:while (parseHeader())。仅仅是一个循环,没有方法体。这里其实每次循环都是试图读取一个请求头的key:value对。代码如下:
1 /** 2 * 读取请求头信息,注意:每次调用该方法,完成一个键值对读取,也即下面格式中的一行请求头 3 * 请求头格式如下 4 * =================================== 5 * key:空格(SP)value回车(CR)换行(LF) 6 * ... 7 * key:空格(SP)value回车(CR)换行(LF) 8 * 回车(CR)换行(LF) 9 * =================================== 10 * 11 * Parse an HTTP header. 12 * 13 * @return false after reading a blank line (which indicates that the 14 * HTTP header parsing is done 15 */ 16 @SuppressWarnings("null") // headerValue cannot be null 17 private boolean parseHeader() throws IOException { 18 19 /** 20 * 此循环主要是在每行请求头信息开始前,确定首字节的位置 21 */ 22 while (true) { 23 24 // Read new bytes if needed 25 /** 26 * Tomcat缓存buf中没有带读取数据,重新从操作系统读取一批 27 */ 28 if (pos >= lastValid) { 29 if (!fill()) 30 throw new EOFException(sm.getString("iib.eof.error")); 31 } 32 33 /** 34 * 这里的chr最开始是在读取请求行时赋值,赋予它请求行第一个非空格字节 35 */ 36 prevChr = chr; 37 chr = buf[pos]; 38 39 /** 40 * 首位置是回车符(CR),有2种情况: 41 * 1、CR+(~LF) 首次先往后移动一个位置,试探第二个位置是否是LF,如果是则进入情况2;如果不是,则回退pos。key首字节可以是CR,但第2个字节不能是LF,因为行CRLF是请求头结束标志 42 * 2、CR+LF 请求头结束标志,直接结束请求头读取 43 * 首位置不是CR,直接结束循环,开始读取key 44 */ 45 if (chr == Constants.CR && prevChr != Constants.CR) { 46 /** 47 * 每次while循环首次进入这个if分支preChr都不是CR,如果当前位置pos是CR,则往后移动一位,根据后一位情况决定后续操作 48 * 如果后一位是LF,直接直接请求头读取 49 * 如果后一位不是LF,pos回退一位,用作key。 50 */ 51 // Possible start of CRLF - process the next byte. 52 } else if (prevChr == Constants.CR && chr == Constants.LF) { 53 /** 54 * 请求头结束,注意是请求头结束,不是当前键值对结束,请求头结束标志:没有任何其他数据,直接CRLF 55 */ 56 pos++; 57 return false; 58 } else { 59 /** 60 * 如果当前行的首字节不是CR,直接break,开始读取key 61 * 如果当前行首字节是CR,但是第二字节不是LF,pos回退1位,开始读取key 62 */ 63 if (prevChr == Constants.CR) { 64 // Must have read two bytes (first was CR, second was not LF) 65 pos--; 66 } 67 break; 68 } 69 70 pos++; 71 } 72 73 // Mark the current buffer position 74 /** 75 * 标记当前键值对行开始位置 76 */ 77 int start = pos; 78 int lineStart = start; 79 80 // 81 // Reading the header name 82 // Header name is always US-ASCII 83 // 84 85 /** 86 * colon标记冒号的位置 87 */ 88 boolean colon = false; 89 MessageBytes headerValue = null; 90 91 /** 92 * 读取key,直到当前字节是冒号(:)跳出循环,pos指向冒号后一个字节 93 */ 94 while (!colon) { 95 96 // Read new bytes if needed 97 /** 98 * 获取缓冲区数据 99 */ 100 if (pos >= lastValid) { 101 if (!fill()) 102 throw new EOFException(sm.getString("iib.eof.error")); 103 } 104 105 106 if (buf[pos] == Constants.COLON) { 107 /** 108 * 当前字节是冒号,colon=true,当前循环执行完后,结束循环 109 * 在Tomcat缓冲区buf字节数组中标记出头信息的名称key: 110 * 每个key:value对中有2个MessageBytes对象,每个MessageBytes对象中都有字节块ByteChunk,用来标记buf中的字节段 111 */ 112 colon = true; 113 headerValue = headers.addValue(buf, start, pos - start); 114 } else if (!HttpParser.isToken(buf[pos])) { 115 // Non-token characters are illegal in header names 116 // Parsing continues so the error can be reported in context 117 // skipLine() will handle the error 118 /** 119 * 非普通字符,比如:(,?,:等,跳过这行 120 */ 121 skipLine(lineStart, start); 122 return true; 123 } 124 125 /** 126 * 大写字符转换成小写字符,chr记录key中最后一个有效字节 127 */ 128 chr = buf[pos]; 129 if ((chr >= Constants.A) && (chr <= Constants.Z)) { 130 buf[pos] = (byte) (chr - Constants.LC_OFFSET); 131 } 132 133 /** 134 * 下标自增,继续下次循环 135 */ 136 pos++; 137 138 } 139 140 // Mark the current buffer positio 141 /** 142 * 重置start,开始读取请求头值value 143 */ 144 start = pos; 145 int realPos = pos; 146 147 // 148 // Reading the header value (which can be spanned over multiple lines) 149 // 150 151 boolean eol = false; 152 boolean validLine = true; 153 154 while (validLine) { 155 156 boolean space = true; 157 158 // Skipping spaces 159 /** 160 * 跳过空格(SP)和制表符(HT) 161 */ 162 while (space) { 163 164 // Read new bytes if needed 165 if (pos >= lastValid) { 166 if (!fill()) 167 throw new EOFException(sm.getString("iib.eof.error")); 168 } 169 170 if ((buf[pos] == Constants.SP) || (buf[pos] == Constants.HT)) { 171 pos++; 172 } else { 173 space = false; 174 } 175 176 } 177 178 int lastSignificantChar = realPos; 179 180 // Reading bytes until the end of the line 181 /** 182 * 183 */ 184 while (!eol) { 185 186 // Read new bytes if needed 187 if (pos >= lastValid) { 188 if (!fill()) 189 throw new EOFException(sm.getString("iib.eof.error")); 190 } 191 192 /** 193 * prevChr首次为chr=:,之后为上一次循环的chr 194 * chr为当前pos位置的字节 195 */ 196 prevChr = chr; 197 chr = buf[pos]; 198 if (chr == Constants.CR) { 199 /** 200 * 当前字节是回车符,直接下次循环,看下个字节是否是LF 201 */ 202 // Possible start of CRLF - process the next byte. 203 } else if (prevChr == Constants.CR && chr == Constants.LF) { 204 /** 205 * 当前字节是LF,前一个字节是CR,请求头当前key:value行读取结束 206 */ 207 eol = true; 208 } else if (prevChr == Constants.CR) { 209 /** 210 * 如果前一字节是CR,当前位置字节不是LF,则本key:value对无效,删除! 211 * 直接返回true,读取下一个key:value对 212 */ 213 // Invalid value 214 // Delete the header (it will be the most recent one) 215 headers.removeHeader(headers.size() - 1); 216 skipLine(lineStart, start); 217 return true; 218 } else if (chr != Constants.HT && HttpParser.isControl(chr)) { 219 // Invalid value 220 // Delete the header (it will be the most recent one) 221 headers.removeHeader(headers.size() - 1); 222 skipLine(lineStart, start); 223 return true; 224 } else if (chr == Constants.SP) { 225 /** 226 * 当前位置空格,位置后移一位 227 */ 228 buf[realPos] = chr; 229 realPos++; 230 } else { 231 /** 232 * 当前位置常规字符,位置后移一位,标记最后字符 233 */ 234 buf[realPos] = chr; 235 realPos++; 236 lastSignificantChar = realPos; 237 } 238 239 pos++; 240 241 } 242 243 realPos = lastSignificantChar; 244 245 // Checking the first character of the new line. If the character 246 // is a LWS, then it's a multiline header 247 248 // Read new bytes if needed 249 if (pos >= lastValid) { 250 if (!fill()) 251 throw new EOFException(sm.getString("iib.eof.error")); 252 } 253 254 /** 255 * 特殊逻辑: 256 * 当前key:value对读取完后, 257 * 如果紧接着的是SP(空格)或则HT(制表符),表示当前value读取并未结束,是多行的,将eol=false,继续读取,直到CRLF. 258 * 如果紧接着不是SP和HT,那vaLine=false,跳出循环,value读取完毕 259 */ 260 byte peek = buf[pos]; 261 if (peek != Constants.SP && peek != Constants.HT) { 262 validLine = false; 263 } else { 264 eol = false; 265 // Copying one extra space in the buffer (since there must 266 // be at least one space inserted between the lines) 267 buf[realPos] = peek; 268 realPos++; 269 } 270 271 } 272 273 // Set the header value 274 /** 275 * 使用新的字节块BytChunk标记当前key:value对的value 276 */ 277 headerValue.setBytes(buf, start, realPos - start); 278 279 return true; 280 281 }
22-71行:每行请求头开始读取前,确定首字节的位置。详细逻辑比较复杂,请看代码注释
94-138行:读取请求头key的数据,直到遇到冒号为止,这里同样使用了字节块来标记。
144-结尾:首先重置start,然后再次过滤空格,直到遇到联系的CRLF表示当前key:value结束。请求头value数据同样也使用了字节块来做标记。
读取value有个特殊逻辑:
260-271行:当前请求头value读取完毕后,如果紧接着是空格,表示当前请求头的值有多个,将eol=false,继续循环读取,直到CRLF。这种情况一般很很少使用,了解就好。
至此,已经完整分析了一次HTTP请求中请求行和请求头的详细读取过程。重点要理解Tomcat中的缓存缓冲区,以及IO读取数据的方式。最后按照HTTP规范解析,这个过程比较底层,也比较绕,需要有耐心,下篇文章我们继续开始请求体的处理,敬请关注!
再次强调:以上源码都是基于Tomcat7,且是BIO模型。