首先实现rdd缓存
准备了500M的数据 10份,每份 100万条,存在hdfs 中通过sc.textFile方法读取
val rdd1 = sc.textFile("hdfs://mini1:9000/spark/input/visitlog").cache
在启动spark集群模式时分配内存2g,第一次分配1g 只缓存了40% 当数据需要的内存大于实际的内存时spark会尽力的缓存
然后调用cache方法
rdd1.count
第二次调用rdd的count方法就显示出差距了
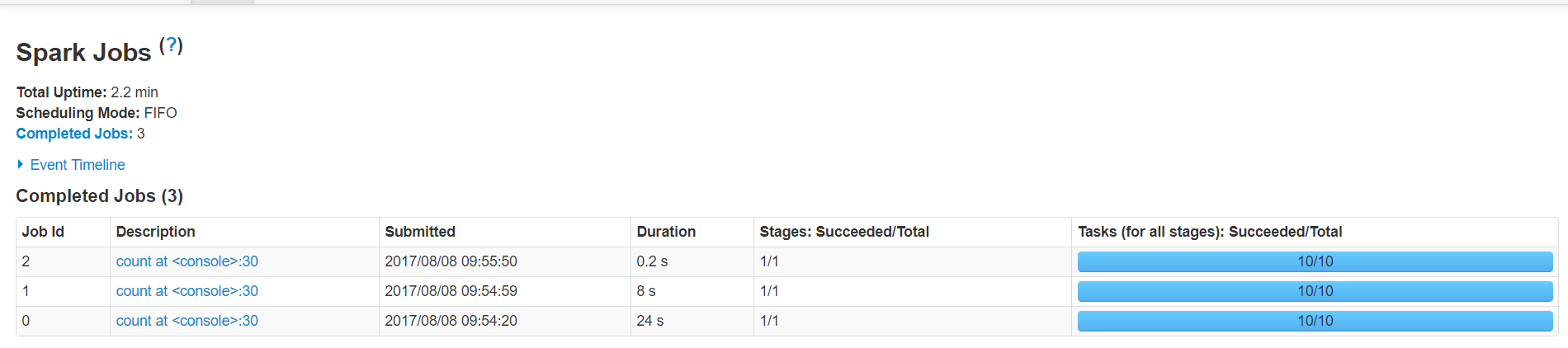
默认缓存策略是memory_only
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
其他的缓存策略
object StorageLevel { //不缓存 val NONE = new StorageLevel(false, false, false, false) //只往磁盘中缓存 val DISK_ONLY = new StorageLevel(true, false, false, false) //磁盘中缓存两份 val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) //放在内存中 val MEMORY_ONLY = new StorageLevel(false, true, false, true) //内存中保存两份,多个机器报存 val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) //报存一份到内存,并且把数据序列化,序列化之后数据占用内存变小, //但是序列化时需要消耗时间,时间换空间 val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) // val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) //内存和磁盘都保存 val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) //内存和磁盘都保存 序列化两份 val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(false, false, true, false)