一、概述
1. Kafka是由LinkedIn(领英)开发的一个分布式的消息系统,最初是用作LinkedIn的活动流(Activity Stream)和运营数据处理的基础
a. 活动流数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析
b. 运营数据指的是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
2. Kafka是一个分布式的流式处理平台,主要包含三个功能
a. 发布和订阅数据,类似于消息队列或者企业中的消息传递系统
b. 存储数据的时候有容错(分布式+复本机制)和持久化机制
c. 数据产生的时候处理记录(数据)
3. 应用场景
a. 在系统或者应用程序之间构建可靠的数据传输的实时流管道
b. 在转换或者响应数据流的时候构建实时流程序
4. Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。
目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成
5.Kafla之间传输数据是使用的零拷贝技术
二、消息队列对比
1. RabbitMQ
a. RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发
b. 实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持
2. Redis
a. Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃
b. 虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用
3. ZeroMQ
a. ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景
b. ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战
c. ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty(NIO)作为传输模块)
4. ActiveMQ
a. ActiveMQ是Apache下的一个子项目
b. 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列,
c.类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
5. 消息队列的优势
a. 屏蔽生产者和消费者之间的异构型
b.实现消峰限流
三、Kafka的适用场景
1. Messaging
a. 对于一些常规的消息系统,kafka是个不错的选择,partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势
b. kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2. Website activity tracking
a. kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3. Metric
a. Kafka通常被用于可操作的监控数据。这包括从分布式应用程序来的聚合统计用来生产集中的运营数据提要。
4. Log Aggregatio
a. kafka的特性决定它非常适合作为"日志收集中心";
b. application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;
c. kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支。此时consumer端可以使hadoop等其他系统化的存储和分析系统
四、Kafka的安装
1.下载安装包
官网地址:http://kafka.apache.org/downloads.html
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
2.解压安装包
tar -zxvf kafka_2.11-2.3.0.tgz
3.进入config目录
cd kafka_2.11-2.3.0/config
4.编辑配置文件(根据自己需求配置,这里我最基本的配置)
vim server.properties
21行:broker.id=0(随意不重复即可)
60行:配置日志路径
123行:配置zookeeper集群
5.将kafka目录scp拷贝至另外两个主机,并更改broker.id(不重复即可)
6.启动zookeeper集群
7.启动Kafka,执行:sh kafka-server-start.sh ../config/server.properties
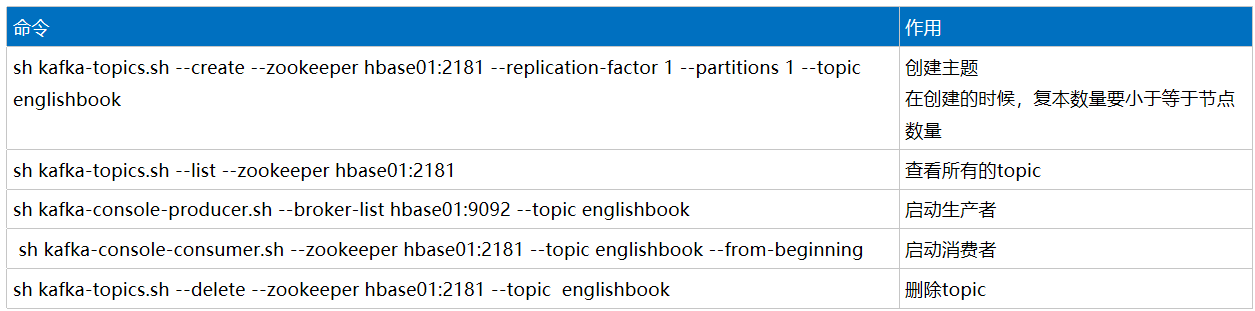
五、基本指令
六、参数配置