移除重复数据
DataFrame中常常会出现重复行。 例如:
df1 = DataFrame({'k1':['one']*3 + ["two"]*4, "k2":[1, 1, 2, 3, 3, 4, 4]})
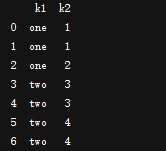
判断重复行duplicated
DataFrame的duplicated方法返回一个布尔型Series, 表示各行是否是重复行:
df1 = DataFrame({'k1':['one']*3 + ["two"]*4, "k2":[1, 1, 2, 3, 3, 4, 4]})
df2 = df1.duplicated() #duplicated("k2")
print(df2)
print(df1[df2])

还有个与此相关的drop_duplicates方法, 它用于返回一个移除了重复行的DataFrame

也可以根据指定部分列进行重复项判断


如果默认保留最后一个怎么办 take_last = True
df1 = DataFrame({'k1':['one']*3 + ["two"]*4, "k2":[1, 1, 2, 3, 3, 4, 4]})
df1['v'] = range(7)
print(df1)
print(df1.drop_duplicates(['k1', 'v'], take_last=True))