本文知识 由 hadoop权威指南第四版获得,图片也来自与此
Read Data
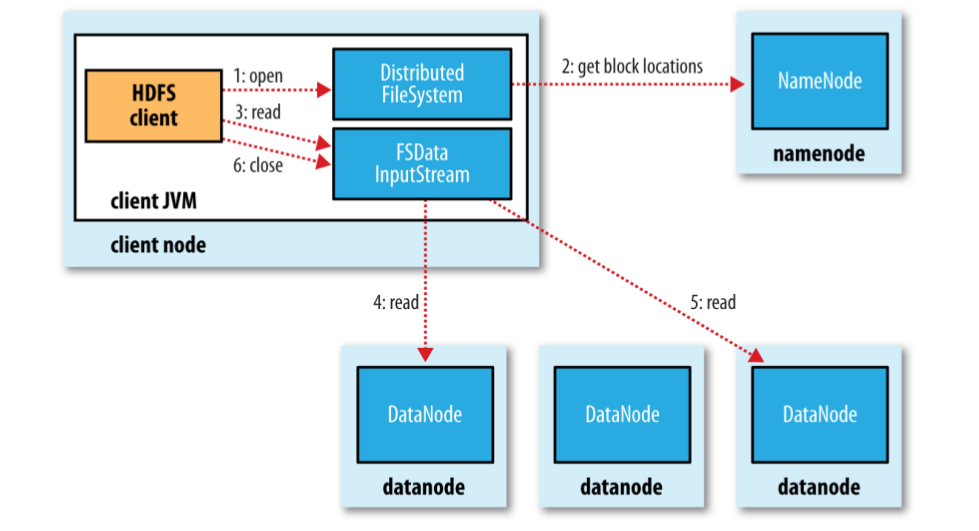
client通过调用 FileSystem对象的open()方法来打开文件。在HDFS中,FileSystem是DistributedFileSystem的一个实例。DistributedFileSystem是通过RPC调用namenode,获取文件起始block的位置。对于每一个block,namenode会返回存有该block副本的datanode地址,而且datanode 根据与client的距离来排序。如果该client本身就是一个datanode,并保存有相应数据块的一个副本时,该节点会从本地datanode读取数据。
DistributedFileSystem 会返回给client FSDataInputStream对象 用于读取数据。FSDataInputStream包装了 DFSInputStream对象,该对象管理着datanode和namenode的I/O。client调用read()方法时,FSDataInputStream会连接距离最近的datanode。通过反复调用read()方法,将数据从datanode传输到客户端。当读取完一个block时,DFSInputStream 会关闭与datanode的连接。然后寻找下一个block的最佳datanode。这写操作对客户端是透明的。
在读取数据期间,如果 DFSInputStream 在与datanode 通信时遇到错误,会尝试从这个block的另一个最近的datanode读取数据。并且会记住这个故障的datanode,确保不会反复读取该节点上后续的block。DFSInputStream 也会通过校验从datanode读取的数据是否完整。如果发现有block的损坏,DFSInputStream 会尝试从其他datanode读取备份,并将该损坏的blocak报告给namenode。
这个设计有个非常重要的一面,namenode 告诉client每个block 最佳的datanode,client可以直接连接该datanode 并检索数据。因为数据流分散到 集群中的datanode中,这种设计可以使HDFS 能够处理大量的并发连接。同时,namenode只相应块位置的请求(这些信息存储在内存中,所以非常高效)。namenode不响应数据的请求,否则随着client并发量的增长,namenode的性能将称为瓶颈。
Write Data
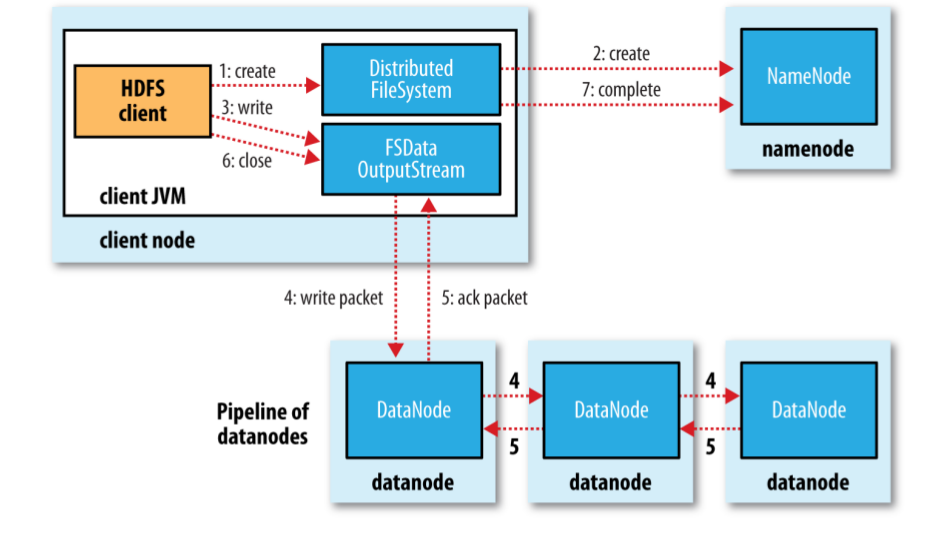
client通过调用 create()方法在DistributedFileSystem创建文件。DistributedFileSystem 会通过RPC调用namenode在 文件系统命名空间中新建一文件,但是该文件并未有block。namenode会执行严格的检查确保文件不存在并且client有新建该文件的权限。如果通过这些检查,namenode就会为这个新文件创建一个记录(the namenode makes a record of the new file).否则,文件创建失败,client会抛出一个IOException。
DistributedFileSystem向 client返回一个FSDataOutputStream对象,client拿到该对象就可以开始写入数据。就像数据读取一样,FSDataOutputStream 包装了 DFSOutputStream,该对象处理datanode和namenode通信。
client在写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部数据队列(data queue)。data queue由 DataStreamer处理,DataStreamer责任是,根据datanode列表请求namenode分配blocks用以存储 数据副本。(The data queue is consumed by the DataStreamer , which is responsible for asking the namenode to allocate new blocks by picking a list of suitable datanodes to store the replicas.) 这一组datanode形成一个管道流,如上图(假设有3个副本)。DataStreamer 将数据包发给pipeline的第一个datanode,该datanode存储数据包并将它发送到第二个datanode,以此类推。
DFSOutputStream 也维护一个内部数据包队列等待接受datanode的确认回执(ack queue)。在收到管道中所有的datanode确认信息后,该数据包才会从 ack queue 中删除。
如果数据在写入期间datanode fail,则会执行以下操作(对客户端是透明的)。
- 关闭pipeline。
- 将ack queue中所有数据包都添加回data queue的最前段,确保故障节点下游的datanode不会漏掉任何一个数据包。
- 将存储在 正常的datanode 节点上的当前block指定一个新的标示,并将该标示告知namenode,以便故障的datanode能够删除存储的部分的block。
- 故障节点会被从pipeline中移除,然后会从另两个新的节点上构造新的pipeline。并将剩余的block写入另外两个datanode。namenode会注意到replica数量不足,会在另一个节点上创建新的replica。后续的 block继续正常处理。
如果在写入一个block时,发生多个datanode故障,虽然少见,单不能排除。hadoop认为只要写入了 dfs.namenode.replication.min 设置的数量(默认为1) 就认为写操作是成功的。并且这个块可以在集群中异步复制,直到达到dfs.replication 所设置的副本数量。
当client完成数据的写入后,会调用close()方法关闭流。该操作会将 剩余的所有的数据包写入datanode pipeline,等待确认文件写入完成,并联系namenode发送完成信号。namenode已经知晓文件是由那些块构成的,所以在它返回成功钱只需要等待block进行最小量的复制。
Replica 存放
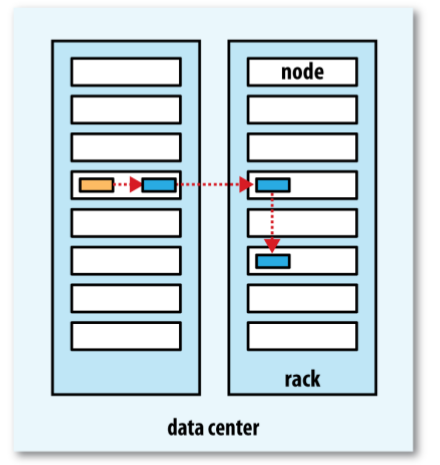
Hadoop默认block存放布局策略是,运行在客户端节点上存放第一个replica(如果客户端运行在集群节点之外,就随机选择一个节点,不过系统不会选择存储太满或者太忙的节点)。第二个replica放在与第一个不同且随机选择的机架中节点上。第三个replica与第二个replica放在同一个机架上,随机选择一个节点存放。其他replica放在集群中随机选择的节点上,不同系统会尽量避免在同一个机架上放太多的replica。