字符串匹配一般有两种常见的算法,BF(Brute Force)算法和KMP算法,下面分别说明一下,假定目标串S,长度为n,模式串P,长度为m
BF算法是最直观的算法,从目标串S的起点0到n-m,依次遍历
伪代码如下
for i <- 0 to n-m j <- 0//每次P的指针j回溯到起点,S的指针i加一 while j < m if S[i+j] = P[j] j++ else break if j = m return i return -1
BMP算法利用了模式串P自身的一些属性,假定S[i, i+k-1] = P[0, k-1],但是S[i+k]!=P[k],我们可以找到k',k'满足以下条件
1.P[0 ,k'-1] = P[k-k', k-1]
2.k'是所有满足条件1中最大的
然后把整个模式串P之间向右平移k-k'次,也就是把P[k']移动到P[k]的位置,如图所示
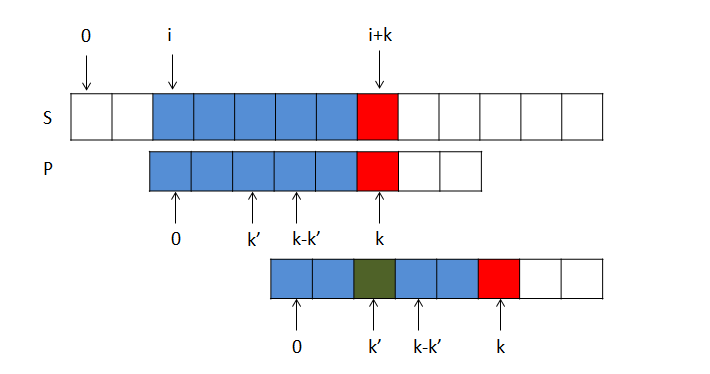
显然这么做的话,P[0, k'-1]与S[i+k-k' ,i+k-1]之间已经匹配好了,我们只需要比较P[k']与S[k]之间的是否相等。
等等,是不是落下了什么,正确的匹配会不会发生在模式串P向右平移[1, k-k'-1]之间的某次呢?不妨假设向右平移了c次,c属于上述区间,如下图
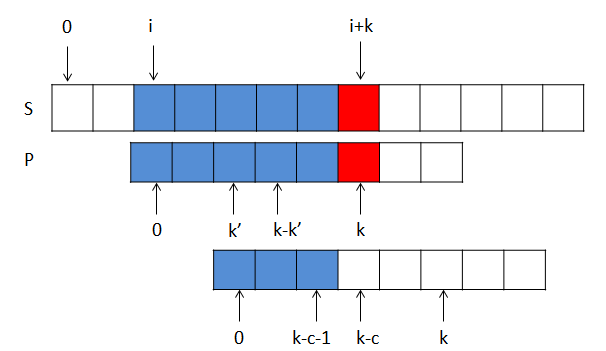
若是发生了正确匹配,必然有P[0, k-c-1] = S[i+c , i+k-1] = P[c+1, k]。另外k-c-1 > k'-1,显然违反了k'的性质2,假设不成立,也就是说正确的匹配不会发生在模式串P向右平移[1, k-k'-1]之间的某次,我们可以放心大胆的平移k-k'了。
在大多数经典论述中,上面所说的k'就是next[k],接下来就该考虑如何求解next[k]了,根据我看到的资料,关于next[k]的解法应该是有两种,区别在于是否考虑P[k]和P[k']是否相同,先说不考虑是否相同的情况。首先,next[0] = -1,表示从P的头部开始比较,假定已知k' = next[k],则P[0, k'-1] = P[k-k', k-1],要求next[k+1]
1.如果P[k'] = P[k],则P[0, k'] = P[k-k', k],next[k+1] = next[k] = k'
2.如果P[k'] != P[k],相当于模式串P自己与自己比对,k <- next[k],然后重复上述过程
附代码
void getNext(char *p, int *next) { next[0] = -1; int j = 0; int k = -1; while (j < strlen(p)) { if(k == -1 || p[k] == p[j]) { k++; j++; next[j] = k; /*if(p[k] == p[j]) next[j] = next[k]; else next[j] = k;*/ } else k = next[k]; } } int KMP(char *s, char *p) { int next[20]; getNext(p, next); int i = 0, j = 0; while (i < strlen(s)) { if(j==-1 || s[i]==p[j]) { i++; j++; } else { j = next[j]; } if(j == strlen(p)) return i-j; } return -1; }
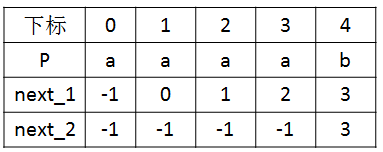
第二种算法是考虑了P[k]和P[k']是否相同,对于按照第一种算法算出k',如果P[k]和P[k']不相等,和第一种完全相同;否则k' <- next[k'],注意这句话中的隐含操作,把next[k']赋给k',那么next[k']中存储的又是什么呢,实际上是一种递归操作,找出最大的某下标d,使得P[d]!=P[k],而P[k]=P[k']=P[next[k']]=......P[pre_d],其中next[pre_d]=d,结果就是next[k] = next[k']=...=next[pre_d]=next[d],即把next[d]的值赋给其他,再次强调此时P[d]!=P[k]。可以直观地感觉出这种算法更加高效,因为如果P[k] = P[k'],则P[k'] != S[i+k],模式串仍然需要继续向右平移,而第二种算法一步到位。区别如表格所示
getNext的函数也改为如下形式
void getNext(char *p, int *next) { next[0] = -1; int j = 0; int k = -1; while (j < strlen(p)) { if(k == -1 || p[k] == p[j]) { k++; j++; //next[j] = k; if(p[k] == p[j]) next[j] = next[k]; else next[j] = k; } else k = next[k]; } }
而匹配算法int KMP(char *s, char *p)与原来的完全相同。