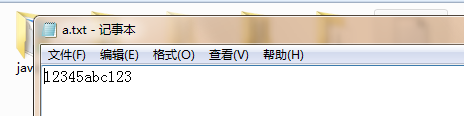
public class test { public static void main(String[] args) throws Exception { InputStream file = new FileInputStream("F://a.txt"); InputStreamReader inputStreamReader = new InputStreamReader(file); int i = 0 , count = 1; /* 基本思路 从文档中从头开始,逐次读取字符,让读取的字符与keySet(也就是map的键集合)里的值作对比: 如果有,则让map的value值 "+1" 赋给count,将键和值存到map集合里; 如果没有,则将map的value值设为 "1",同样,将键和值存到map集合里。 最后遍历 */ HashMap<Character, Integer> hashMap = new HashMap<Character, Integer>(); Set<Character> keySet = hashMap.keySet(); while ((i = inputStreamReader.read()) != -1) { if (keySet.contains((char)i)) { count = (int) hashMap.get((char)i)+1; hashMap.put((char)i,count); } else { hashMap.put((char)i, 1); } }
//遍历输出 for (Character character : keySet) { System.out.println("键(字符):"+character+" 值(出现次数):"+hashMap.get(character)); } } }