什么是回溯
在wiki百科中的定义是:
对于某些计算问题而言,回溯法是一种可以找出所有(或一部分)解的一般性算法,尤其适用于约束满足问题(在解决约束满足问题时,我们逐步构造更多的候选解,并且在确定某一部分候选解不可能补全成正确解之后放弃继续搜索这个部分候选解本身及其可以拓展出的子候选解,转而测试其他的部分候选解)
它是属于暴力搜索法的一种。
一般通俗的来讲,回溯的处理方式是如果不满足当前条件的最优解,就退回去重新去选其他的候选解,如不满足则再次退回,直到找到最优解。

在上面树状节点图中,如果我们需要找到 A3112 的这个节点的路径,那么 节点会按A1,A2,A3的先后顺序搜索,发现A1不满足条件,退回A 选择 A-A2的路径,也不满足。再找到A-A3。符合要求,继续A->A3->A31 符合要求,继续下去 A->A3->A31->A311 碰巧同样符合要求,再往下 A->A3->A31->A311->A3111 发现不符合要求,再退回A311 选择 A311->A3112 搜索路径成功,结束。
在Javascript正则表达式 同样有一套回溯的机制,看一下如下的 正则表达式,
//Regexp
/ab{1,3}c/
表示正则匹配 的字符串"abc",但是字符串中间的b可以有一个到三个。
下面的图表示的是 正则匹配 "abbbc"的字符串,没有回溯
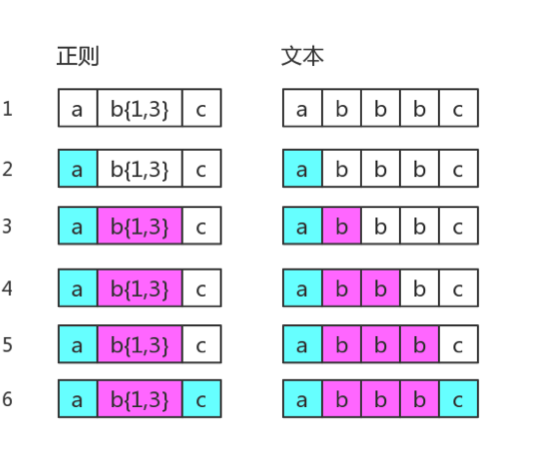
这里要提示下,正则表达式默认的是开启贪婪模式,理论上它匹配的b越多越好。
下面的图表示正则匹配 "abbc" ,出现了回溯。

上面的例子4步已经匹配了两个b了,再去匹配b的时候发现字符串后面是c,这时候发生了回溯,返回上一步匹配两个bb的时候,这时b{1,3}已经匹配完毕,再去匹配正则的下一个c匹配成功。
当我们使用 .* 匹配字符串的时候,会非常影响效率。因为如果我们用 /".*"/去匹配"abc"def这这样的字符串时,一直到最后一个字符f才会回溯。要从 f->e>d>" 回溯四次。
正则哪些地方会有回溯
-
贪婪量词
如上面例子所说,正则默认会开启贪婪模式。这会引起回溯。 -
惰性量词
/^d{1,3}?d{1,3}/这个正则如果要匹配12345时。是按如下方式匹配
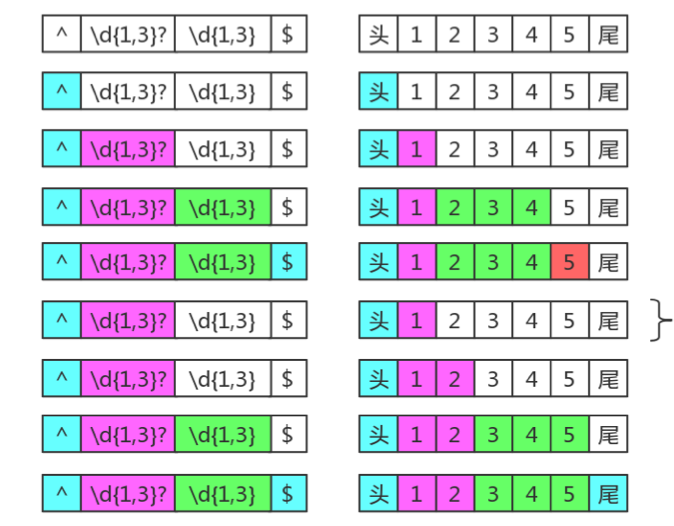
d{1,3}?先匹配的是 1 ,d{1,3}匹配的是234,- 当匹配到5的时候,觉得匹配不下去了,因为已经匹配了 1+3 个数,再匹配第五个数无法匹配。
- 从头开始
d{1,3}?这个时候匹配的是 12,d{1,3}匹配的是345,匹配成功。
-
分支结构
/can|candy/,去匹配字符串"candy",得到的结果是"can",因为分支会 一个一个尝试,如果前面的满足了,后面就不会再试验了
博文参考自 Javascript正则表达式迷你书(1.1版)
静坐常思己过 闲谈莫论人非