====2016/5/20:
经过上级指示,为了MR性能调优,需要截取MR的服务器的线程堆栈(Thread Dump)
战友介绍的方法是这样的:
①、使用ps命令【ps -ef | grep java】过滤出所有的Java进程(毕竟MapReduce是运行在JVM中的)
②、从Java进程中找到MR的运行进程的PID(Process ID)
③、使用kill -3 <pid> 的命令来获取Thread Dump。获取之后的标准输出日志stdout中。
同事的介绍还是比较详细的,按照这个方法尝试了一下,确实是能取得Thread Dump。
但是呢,实际操作的过程中有两个问题,给我带来了很大的困扰:
问题①、Java的进程太多了,用肉眼去查找MR的进行太困难了。经常没等找到,进程就已经结束了。
导致kill -3 <pid>的时候,就会提示下面的信息。

问题②、即使找到了MR进程的PID,使用kill -3 命令也不是每次都能成功取得Thread Dump。
※使用ps -ef | grep java的结果如下图:看这个图是比较心疼自己的眼睛的。
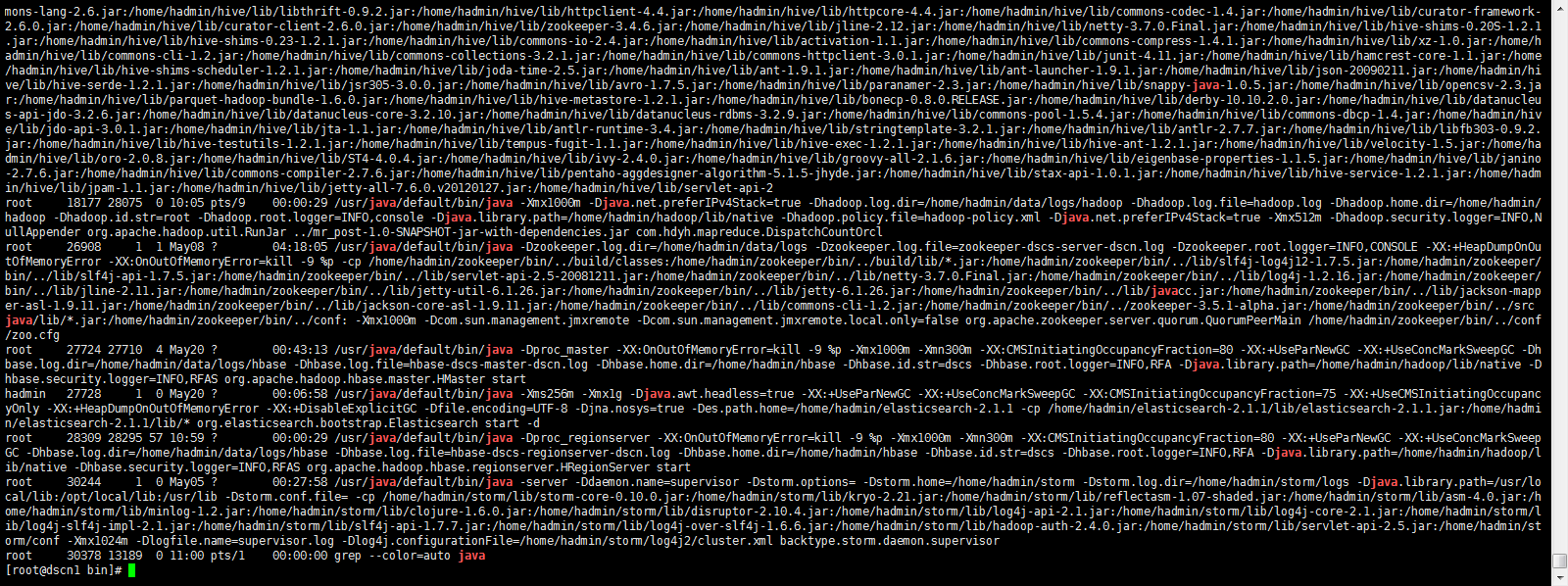
针对问题①,下午进行了一下改进,就是grep的时候,不去用java的关键字,而是使用MR的Job ID去Grep。
JobId可以通过一下两个途径来取得:
途径1:Shell命令行
在使用hadoop jar <jar名> <类名>运行某个Jar包的时候,这个Job被接受并开始运行时,会分配一个JobID,这个ID在控制台上会提示出来。

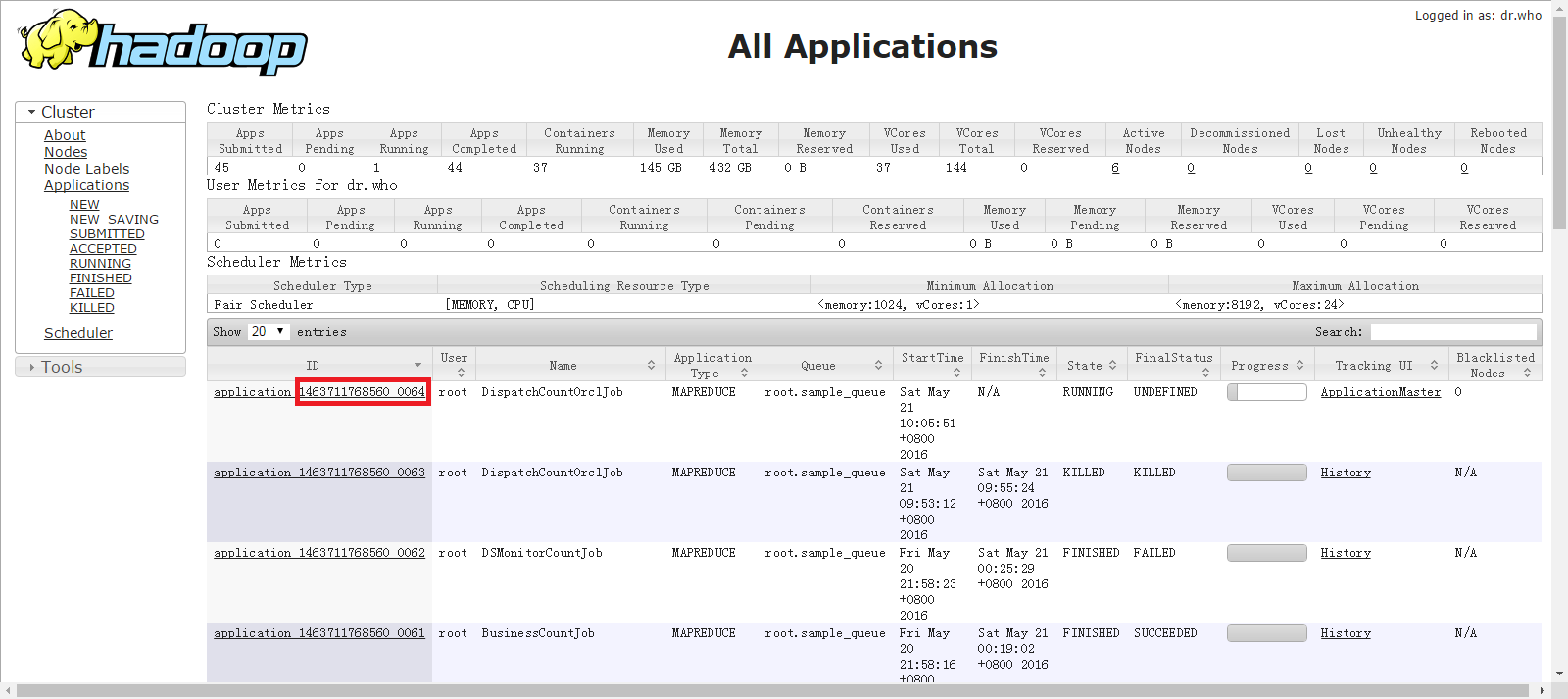
途径2:Web页面
所有的Job都会在Web页面上表示出来,其中第一列的应用管理器的ID的后半段是和JobID一样的,使用这个也可以。
然后使用ps -ef | grep <job id>来查找和这个Job相关的所有进程。如下图所示:
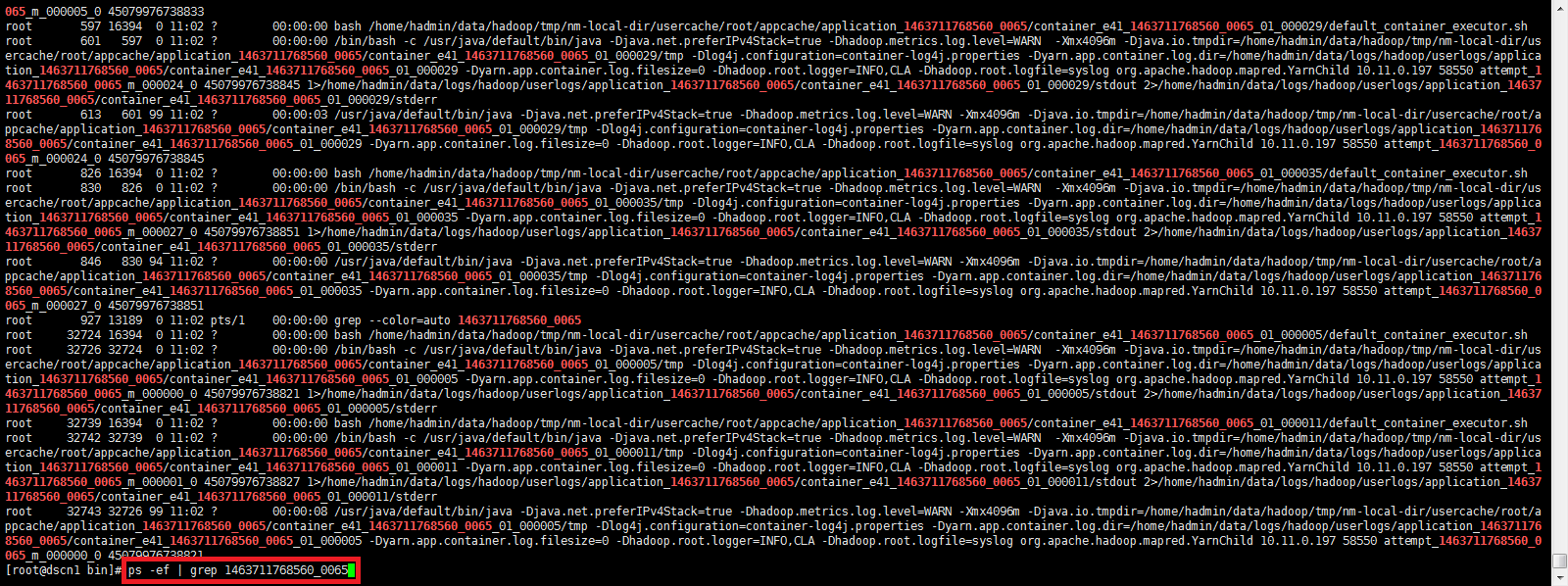
小试身手之后,果然查找MR的进程方便了很多。甚是欣慰。。。
不过上面的问题②,ThreadDump不能每次成功的问题仍然困扰着我。而且到下午之后,既然没有1次能够成功取得Thread Dump。
====2016/5/21
今天是周六,推掉一些生活上的预约(苦逼码农的常态),果断过来加班。
走在路上,满脑袋都是问题②的事情,没有任何头绪。后来想起昨天领导随意说的一句话:是不是你Kill的进程不正确?
感觉很是有道理嘛,为什么不试试呢?迫不及待的来到公司,打开电脑,尝试了一下对MR的不同的进程进行kill。
结果,日了狗了,竟然真的是有的进程无法取得Thread Dump,而有的进程就可以。悲催的同时,见到一丝曙光也是比较开心的。
那么,问题来了,这些进程之间有什么区别,什么进程可以取得Thread Dump呢?
经过一番调查之后,得到如下结论:
--------
系统在运行每个进程时都会关联几个号,分别为pid、ppid、uid、euid。
进程的pid为运行进程时,系统自动分配的,用于唯一标识此进程的一个整数。进程的ppid就是进程的父进程的pid
--------
也就是说进程之间是有父子关系的。只有找到正确的进行才可以取得到dump文件。
过程如下所示: ※蓝色部分为子进程,红色为父进程。
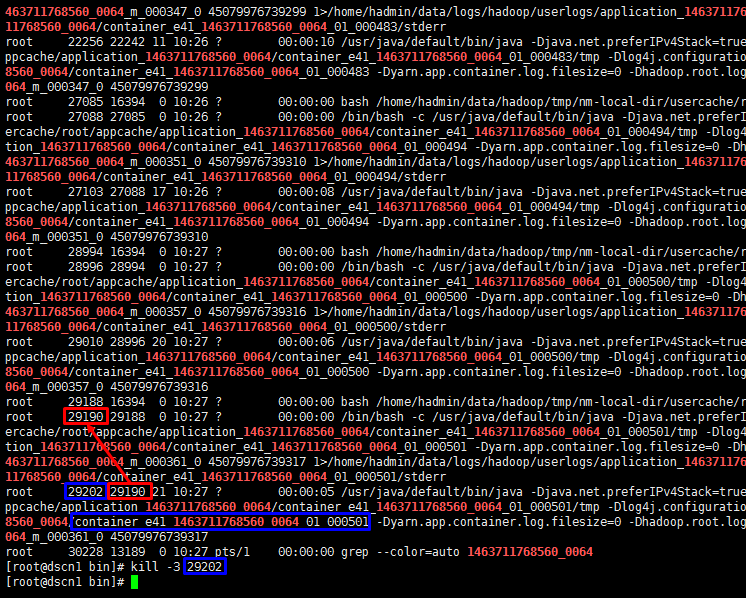
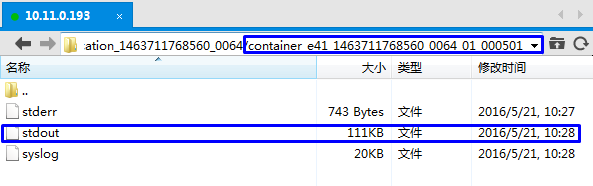
stdout中的内容如下所示。
看到下面的内容,有种想哭的感觉。。。。。
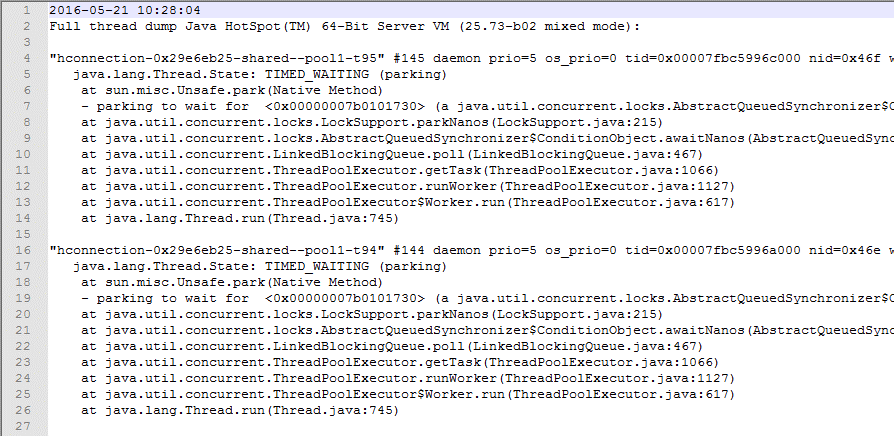
====总结
①、使用ps命令查看进程的pid的时候,可以活用grep关键字。以缩减范围
②、可以使用kill -3 <pid>来发送消息,从而达到截取Thread Dump的目的。
③、kill -3 一定要对正确的进行使用。切记切记。