一、概述
之前的项目比较小,标识ID都是基于数据库主键自增,直到因为某表数据量大,采用分表时出现ID冲突问题,后来使用UUID方式解决。然后就有意识的去了解分布式相关的知识。数据分库分表后需要有唯一ID来标识一条数据,采用传统的数据库的自增ID显然不能满足需求,会有ID冲突,所以记录下分布式ID常见的解决方案
二、解决方案(参考:https://www.cnblogs.com/captainad/p/10954331.html)
在列举分布式ID解决方案前,先了解下我们对分布式ID的要求
- 全局唯一性:即唯一标识
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,所以尽量使用有序的主键保证写入性能。
- 单调递增:即在某种规则上保证后面的ID大于前面的ID
- 信息安全:如果ID是连续的,爬虫就有序可循,对我们的数据造成安全影响,尽量保证ID无规则、不规则。
- 分布ID最好包含时间戳,有利于我们通过ID解析数据生成时间
1、UUID方式实现分布式ID
UUID是最先想到的方式,UUID无规则不可读而且过长
(1)优点
-
- 简单方便。
- 通过本地生成,没有性能问题。
- 因为具备全球唯一的特性,所以对于数据库迁移这种情况不存在问题。
(2)缺点
-
- 每次生成的ID都是无序的,而且不是全数字,且无法保证趋势递增。
- UUID生成的是字符串,字符串存储性能差,查询效率慢。
- UUID长度过长,不适用于存储,耗费数据库性能。
- ID无一定业务含义,可读性差。
(3)适用场景
-
- 可以用来生成如token令牌一类的场景,足够没辨识度,而且无序可读,长度足够。
- 可以用于无纯数字要求、无序自增、无可读性要求的场景。
2、基于数据库多实例主键自增,设置步长
在传统的数据库自增ID的基础之上,设置step增长步长,让DB之前生成的ID趋势递增且不重复。
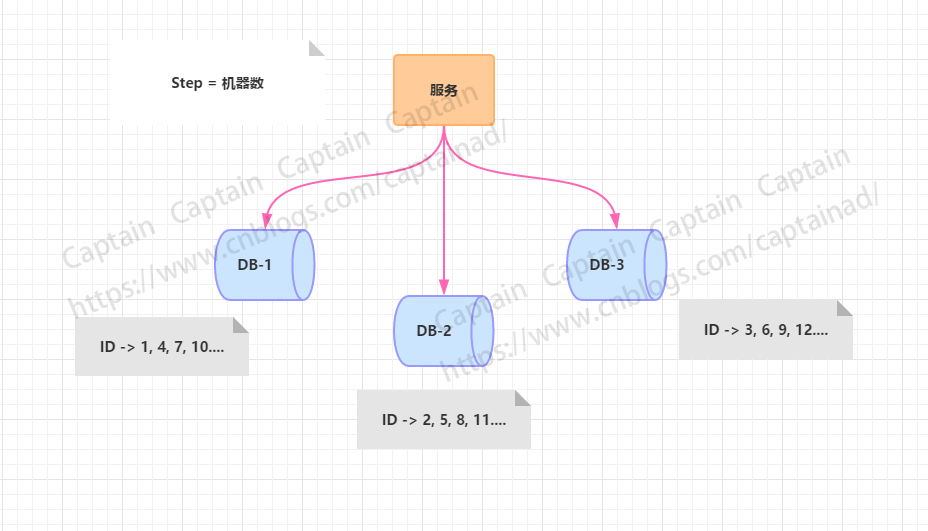
从上图可以看出,水平扩展的数据库集群,有利于解决数据库单点压力的问题,同时为了ID生成特性,将自增步长按照机器数量来设置,但是,这里有个缺点就是不能再扩容了,如果再扩容,ID就没法儿生成了,步长都用光了,那如果你要解决新增机器带来的问题,你或许可以将第三台机器的ID起始生成位置设定离现在的ID比较远的位置,同时把新的步长设置进去,同时修改旧机器上ID生成的步长,但必须在ID还没有增长到新增机器设置的开始自增ID值,否则就要出现重复了。
(1)优点
-
- 解决了ID生成的单点问题,同时平衡了负载。
(2)缺点
-
- 一定确定好步长,将对后续的扩容带来困难,而且单个数据库本身的压力还是大,无法满足高并发。
(3)适用场景
-
- 数据量不大,数据库不需要扩容的场景。
这种方案,除了难以适应大规模分布式和高并发的场景,普通的业务规模还是能够胜任的,所以这种方案还是值得积累。
3、类雪花算法
snowflake雪花算法是twitter公司内部分布式项目采用的ID生成算法,现在开源并流行了起来,下面是Snowflake算法的ID构成图。
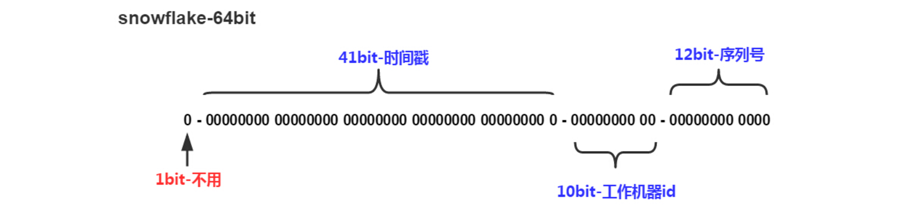
这种方案巧妙地把64位分别划分成多段,分开表示时间戳差值、机器标识和随机序列,先以此生成一个64位地二进制正整数,然后再转换成十进制进行存储。其中,1位标识符,不使用且标记为0;41位时间戳,用来存储时间戳的差值;10位机器码,可以标识1024个机器节点,如果机器分机房部署(IDC),这10位还可以拆分,比如5位表示机房ID,5位表示机器ID,这样就有32*32种组合,一般来说是足够了;最后的12位随即序列,用来记录毫秒内的计数,一个节点就能够生成4096个ID序号。所以综上所述,综合计算下来,理论上Snowflake算法方案的QPS大约为409.6w/s,性能足够强悍了,而且这种方式,能够确保集群中每个节点生成的ID都是不同的,且区间内递增。
(1)优点
-
- 每秒能够生成百万个不同的ID,性能佳。
- 时间戳值在高位,中间是固定的机器码,自增的序列在地位,整个ID是趋势递增的。
- 能够根据业务场景数据库节点布置灵活挑战bit位划分,灵活度高。
(2)缺点
-
- 强依赖于机器时钟,如果时钟回拨,会导致重复的ID生成,所以一般基于此的算法发现时钟回拨,都会抛异常处理,阻止ID生成,这可能导致服务不可用。
适用场景,不过目前有好多开源的方式解决了强依赖机器时钟
-
- 雪花算法有很明显的缺点就是时钟依赖,如果确保机器不存在时钟回拨情况的话,那使用这种方式生成分布式ID是可行的,当然小规模系统完全是能够使用的。
三、使用类雪花算法封装类库