★Spring生命周期
★Spring AOP Spring IOC
★Spring的事务实现方式,声明式事务是怎么实现的,spring事务的传播方式
★ES和MongoDB
HTTP报文 = 报文首部 + 报文主题(用户和资源的信息),其中 请求报文首部 = 请求行 + 请求首部字段 + 通用首部字段 + 实体首部字段 ,响应报文首部 = 状态行 + 响应首部字段 + 通用首部字段 + 实体首部字段。
★ Java接口和抽象类
抽象类:如果一个类含有抽象方法那么这个类就是抽象类,被abstract修饰,抽象类也可以有非抽象方法,但是没意义。子类继承抽象类必须重写抽象方法。其中,抽象方法必须被public或protected修饰,缺省情况下是被public修饰,抽象类不能用来创建对象。 接口:如果一个类实现了一个接口,就要实现接口内的所有方法。 区别: 1.抽象类可以有构造函数,接口不可以有构造函数 2.抽象类中可以有普通成员变量,接口中没有普通成员变量,只能有常量 3.抽象类中的方法可以被static修饰,接口中的方法不可以被static修饰 4.抽象类中可以有普通方法和抽象方法,接口中的方法全是抽象方法 5.抽象中的方法可以被public,protected等修饰符修饰,接口中的方法全都是public abstract的方法,如果省略修饰符,则默认的也都是public abstract修饰 6.一个类只能继承一个抽象类,接口可以被多实现,即一个类只能继承一个类,可以实现多个接口
★ 如何使用jar包,他人class文件如何使用?jar都有啥?
类加载机制
BootstrapClassLoader 负责加载 ${JAVA_HOME}/jre/lib 部分 jar 包 ExtClassLoader 加载 ${JAVA_HOME}/jre/lib/ext 下面的 jar 包 AppClassLoader 加载用户自定义 -classpath 或者 Jar 包的 Class-Path 定义的第三方包
★操作系统内核态和用户态的转换
1.为什么要有用户态和内核态 由于需要限制不同的程序之间的访问能力, 防止他们获取别的程序的内存数据, 或者获取外围设备的数据, 并发送到网络, CPU划分出两个权限等级 -- 用户态 和 内核态 2.切换 用户态--》核心态 a.系统调用 用户进程主动要求切换到内核态的一种方式 b.异常 运行在用户态的程序发生了不可预知的异常时,例如缺页异常; c.外部设备的中断 外部设备完成用户请求操作后会向CPU发出相应的中断信号,例如硬盘读写完成; 核心套--》用户态 内核态程序执行完毕时如果要从内核态返回用户态,可以通过执行指令iret来完成,指令iret会将先前压栈的进入内核态前的cs,eip,eflags,ss,esp信息从栈里弹出,加载到各个对应的寄存器中,重新开始执行用户态的程序,这个过程不再详述。
★唯一索引&主键索引?
唯一索引是不允许其中任何两行具有相同索引值的索引
1. 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。 2. 唯一性索引列允许空值,而主键列不允许为空值。 3. 主键列在创建时,已经默认为空值 + 唯一索引了。 4. 主键可以被其他表引用为外键,而唯一索引不能。 5. 一个表最多只能创建一个主键,但可以创建多个唯一索引。 6. 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。 7. 在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
★同步,异步,阻塞,非阻塞--组合
同步:当一个同步调用发出后,调用者要一直等待返回消息(结果)通知后,才能进行后续的执行;
异步:当一个异步过程调用发出后,调用者不能立刻得到返回消息(结果)。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务。
非阻塞:非阻塞是指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
Nginx采用异步非阻塞的事件处理机制,由进程循环处理多个准备好的时间,从而实现高并发和轻量级。
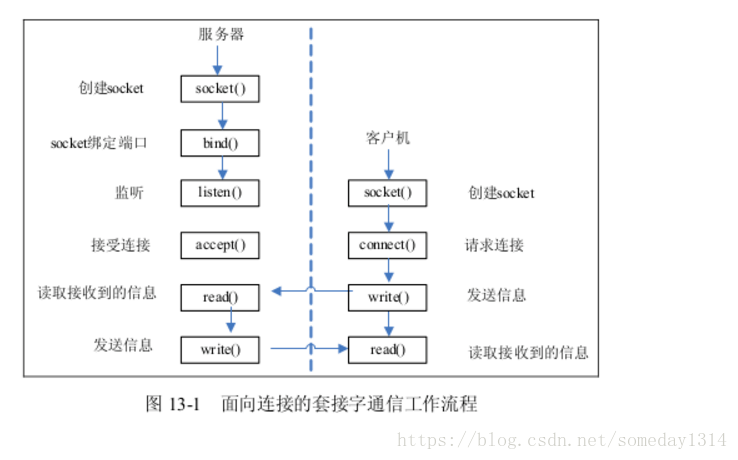
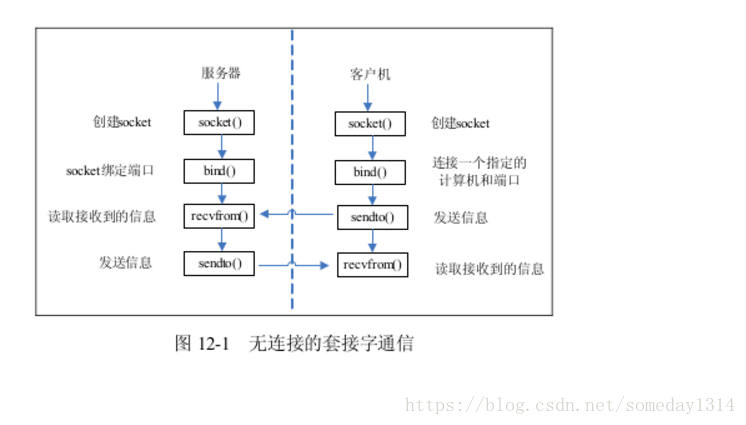
★套接字Socket通信过程
★Java基本数据类型和所占字节数
byte 1 byte = 8 bit char 2 short 2 long 8 int 4 double 8 float 4 boolean 理论上占用1bit 1/8byte,实际处理按1byte处理
G1垃圾收集器在内存上采用了Region化的方法,将堆内存划分为2000块左右的小块。每个Region分配成E、S、O区域。 大对象分配问题: 1.小于一半Region大小的正常存入E区 2.一半到一个Region大小的对象直接存入O区的一个region中,也成为H区 3.大于一个Region大小的使用多个O区存放,这多个Region都是H区。 两个概念: RememberSets:每个Region都有这样一份存储空间,用于存储本Region对象被其他Region对象引用的记录。 CollectionSets:每次GC需要清理的Region集合。 YoungGC过程 将E和S(from)区复制到S(to) MixGC YoungGC + 初次标记:标记GCRoot直接引用的对象的所在Region。与CMS不同的是,G1初次标记一般和YGC同时发生,利用YGC的STW时间,顺带把事情给干了。 RootRegion扫描:标记出RootRegion指向O区的region,标记这些region是为了降低并发标记的扫描范围。 并发标记:标记整个堆 重新标记: 重新标记阶段使用SATB速度比CMS快。 复制清除:将所有Y区的Region和对象存活率较低的O区租组成CollectionSets,进行复制清理。
★Cookie和Session区别 (详情讲解)
1.cookie数据存放在客户的浏览器上,session数据放在服务器上; 2.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session; 3.session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。考虑到减轻服务器性能方面,应当使用COOKIE; 4.单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能超过3K; :
★