一、简介:
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言,具有20多年的发展历史,成熟且稳定。
应用领域:
(1).常规软件开发
Python支持函数式编程和OOP面向对象编程,能够承担任何种类软件的开发工作,因此常规的软件开发、脚本编写、网络编程等都属于标配能力。
桌面软件:PyQt、PySide、wxPython()、PyGTK是Python快速开发桌面应用程序的利器。
(2).科学计算
随着NumPy,SciPy,Matplotlib,Enthoughtlibrarys等众多程序库的开发,Python越来越适合于做科学计算、绘制高质量的2D和3D图像。和科学计算领域最流行的商业软件Matlab相比,Python是一门通用的程序设计语言,比Matlab所采用的脚本语言的应用范围更广泛,有更多的程序库的支持。虽然Matlab中的许多高级功能和toolbox目前还是无法替代的,不过在日常的科研开发之中仍然有很多的工作是可以用Python代劳的。
(3).自动化运维、操作系统管理
这几乎是Python应用的自留地,作为运维工程师首选的编程语言,Python在自动化运维方面已经深入人心,比如Saltstack和Ansible都是大名鼎鼎的自动化平台。
在很多操作系统里,Python是标准的系统组件。大多数Linux发行版以及NetBSD、OpenBSD和MacOSX都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器使用Python语言编写,比如Ubuntu的Ubiquity安装器,RedHatLinux和Fedora的Anaconda安装器。GentooLinux使用Python来编写它的Portage包管理系统。Python标准库包含了多个调用操作系统功能的库。通过pywin32这个第三方软件包,Python能够访问Windows的COM服务及其它WindowsAPI。使用IronPython,Python程序能够直接调用.NetFramework。一般说来,Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性几方面都优于普通的shell脚本。
(4).云计算
开源云计算解决方案OpenStack就是基于Python开发的。
【 OpenStack是一个由NASA(美国国家航空航天局)和Rackspace合作研发并发起的,以Apache许可证授权的自由软件和开放源代码项目。 。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。】
(5).WEB开发
基于Python的Web开发框架比较多,比如Django,还有Tornado,Flask。其中的Python+Django架构,应用范围非常广,开发速度非常快,学习门槛也很低,能够快速的搭建起可用的WEB服务。
【 Django(发音:[`dʒæŋɡəʊ]) 是用python语言写的开源web开发框架(open source web framework),它鼓励快速开发,并遵循MVC设计。Django遵守BSD版权,初次发布于2005年7月, 并于2008年9月发布了第一个正式版本1.0 。】
(6).网络爬虫、服务器软件
也称网络蜘蛛,是大数据行业获取数据的核心工具。能够编写网络爬虫的编程语言有不少,Python绝对是其中的主流之一。
Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫。第三方库Twisted支持异步网络编程和多数标准的网络协议(包含客户端和服务器),并且提供了多种工具,被广泛用于编写高性能的服务器软件。
(7).数据分析
在大量数据的基础上,结合科学计算、机器学习等技术,对数据进行清洗、去重、规格化和针对性的分析是大数据行业的基石。Python是数据分析的主流语言之一。
(8).人工智能
Python在人工智能大范畴领域内的机器学习、神经网络、深度学习等方面都是主流的编程语言,得到广泛的支持和应用。
(9).游戏
很多游戏使用C++编写图形显示等高性能模块,而使用Python或者Lua编写游戏的逻辑、服务器。相较于Python,Lua的功能更简单、体积更小;而Python则支持更多的特性和数据类型。
近些年,编程语言Python的热度越来越高,因为Python简单,学起来快,是不少程序员入门的首选语言。
在网络游戏开发中,Python也有很多应用,相比于Lua or C++,Python比Lua有更高阶的抽象能力,可以用更少的代码描述游戏业务逻辑,Python非常适合编写1万行以上的项目,而且能够很好的把网游项目的规模控制在10万行代码以内。
(10).金融分析与交易
金融分析包含金融知识和Python相关模块的学习,学习内容囊括NumpyPandasScipy数据分析模块等,以及常见金融分析策略如“双均线”、“周规则交易”、“羊驼策略”、“Dual Thrust 交易策略”等。
量化交易,就是以数学模型替代人的主观判断来制定交易策略。通常会借助计算机程序来进行策略的计算和验证,最终也常直接用程序根据策略设定的规则自动进行交易。
Python 由于开发方便,工具库丰富,尤其科学计算方面的支持很强大,所以目前在量化领域的使用很广泛。市面上也出现了很多支持 Python 语言的量化平台。通过这些平台,你可以很方便地实现自己的交易策略,进行验证,甚至对接交易系统
Python 量化平台:
国内平台:优矿 uqer.io 聚宽joinquant.com 米筐 ricequant.com
国外平台:quantopian.com
Python的就业方向
- 发展前景一:Linux运维
- 发展前景二:Python Web网站工程师
- 发展前景三:Python自动化测试
- 发展前景四:数据分析
- 发展前景五:人工智能
例子:
国外:谷歌、youtobe。。。
国内:知乎、搜狐、网易游戏、豆瓣。。。
二、安装
1、(下载安装 python运行环境) 上python官网下载python运行环境(https://www.python.org/downloads/),建议下载稳定版本,不推荐使用最新版本
2、(测试)打开cmd
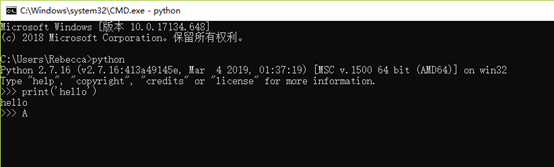
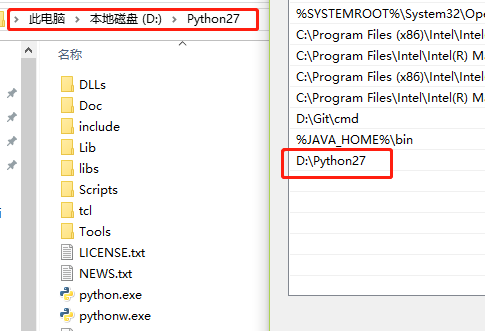
3、如果失败手动配置系统环境
3、安装python包
安装包有两种方法,一种是使用命令行,一种是IDE选择安装
1)下载 https://pypi.python.org/pypi/pip
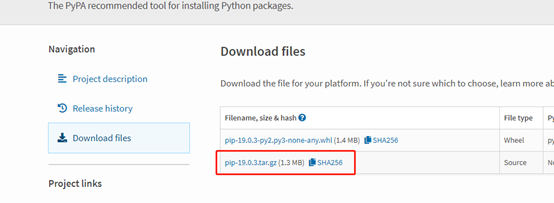
在管理员方式DOS下输入下图命令,进入pip-9.0.1文件夹,然后输入:python setup.py install 进行pip安装
2)(下载安装)上pycharm官网下载最新版的IDE(http://www.jetbrains.com/pycharm/download/#section=windows),官网提供了mac、windows和linux三种版本
1、
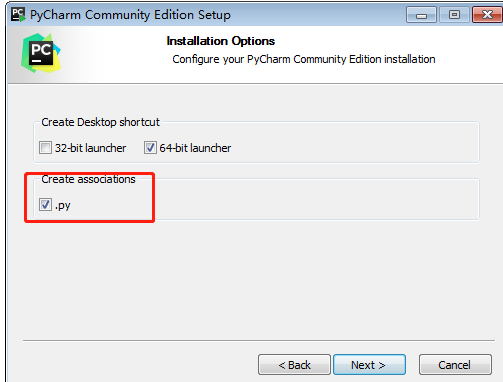
2、
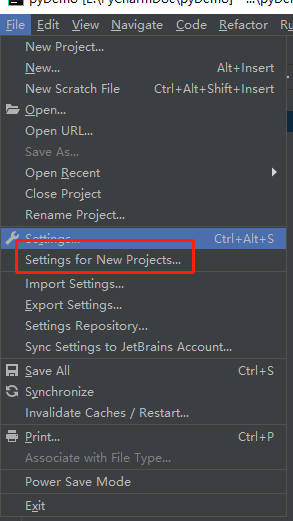
3、
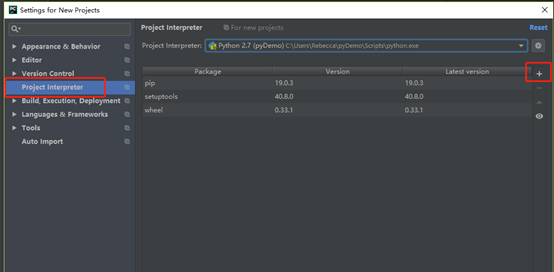
4、
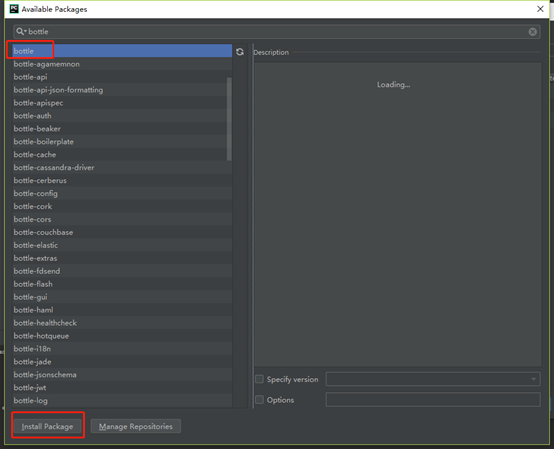
三、简单使用
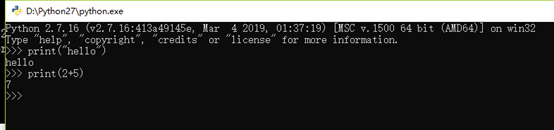
1、Python交互模式
2、使用IDE开发工具PyCharm
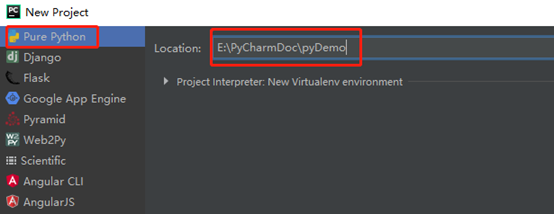
1)创建工程
2)创建一个python文件

3)编写简单语句

4)运行
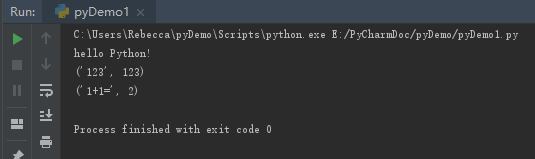
5)结果
五、使用
1、使用编码格式,否则出现中文会报错
使用编码格式,否则出现中文会报错
# encoding: utf-8
或者
# -*- coding:UTF-8 -*-

2、 由于类起到模板的作用,因此,可以在创建实例的时候,把我们认为必须绑定的属性强制填写进去。这里就用到Python当中的一个内置方法__init__方法,例如在Student类时,把name、score等属性绑上去:
lass Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
>>>student = Student("Hugh", 99)
>>>student.name
"Hugh"
>>>student.score
99
注:
(1)__init__方法的第一参数永远是self,表示创建的类实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
(2)有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器会自己把实例变量传进去:
(3)这里self就是指类本身,self.name就是Student类的属性变量,是Student类所有。而name是外部传来的参数,不是Student类所自带的。故,self.name = name的意思就是把外部传来的参数name的值赋值给Student类自己的属性变量self.name。
(4)在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
3、 如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线.
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print "%s: %s" %(self.__name,self.__score)
注:关于新旧式类
(1)继承object类是为了让自己定义的类拥有更多的属性,以便使用。当然如果用不到,不继承object类也可以。python2中继承object类是为了和python3保持一致,python3中自动继承了object类。
(2)python2中需要写为如下形式才可以继承object类。
def class(object):
python2中写为如下两种形式都是不能继承object类的,也就是说是等价的。
def class:
def class():
基础使用:
# encoding: utf-8 #coding=utf-8 # -*- coding: UTF-8 -*- # 编码格式,必须要使用 print('----------------1--------------') print ("hello Python!"); print ("123",123); print ("1+1=",1+1); print ("2的7次方",2 ** 7); print('-------------2---判断/循环------------------------------') # 判断 if (1!=1): print ("True1") elif 2==2: print ("True2") else: print ("False") print('----------') # 循环 for x in [1, 2, 3]: print(x) print('-------------3字符串--------------------------------') str = 'RunoobReb' print(str) # 含头不含尾 print("0-"+str[0]) print("01-"+str[0:-1]) print("25-"+str[2:5]) # 隔2个取数 print("162-"+str[1:6:2]) print("2-"+str[2:]) print(str * 2) print(str + "123asd") # print('-------------数组---------------------------------') # 数组 tup = (1, 2, 3, 4, 5, 6) # 含头不含尾 print(tup[0]) print(tup[1:5]) # 计算长度 print(len(tup)) # print('-------------集合1----------------------------') # list是python基本数据类型,它的元素类型可以不同,如:[1, 2, 'a', 3,4] # array是numpy的一种数据类型,它所包含的元素类型必须相同,如: [1, 2, 3, 4] # NumPy系统是Python的一种开源的数值计算扩展 list = [1,1,2,3] print ([[x, x**2] for x in list]) # 集合转元组 # 定义元组tuple的时候,用的是括号() # tuple一旦初始化就不能修改,这里说的不能修改是指tuple的每个元素,指向永远不变 # tuple和数组不同就在于,tuple中的元素也可以包括list可以包括自己,元组tuple不变,但是tuple里面的元素list是可变的 print (tuple(list)) # 统计1出现的次是 print ("统计",list.count(1)) # 删除 del list[2] print ("删除第三个元素 : ", list) # 新增 list.append(5) print ("增加一个元素 : ", list) # 嵌套列表 x = [['a', 'b', 'c'], [1, 2, 3]] print(x[0]) # 一次性追加一个集合 list.extend(x) print(list) list.append(x) print(list) print('-------------5集合2------------------------------') # Set(集合) 无序不重复的序列,自动去除重复 # 可以使用大括号({})或者set()函数创建集合 student = {'Tom', 'Jim', 'Mary', 'Tom','Tom', 'Jack','Jack', 'Rose'} print(student) if 'Rose' in student : print('Rose 在集合中') else : print('Rose 不在集合中') print('----update-是拆散了放进集合----') student.update({1,2},[3,4]) student.update('haha') print ("update--",student) print('----add--是整体放进集合---') student.add('haha') print ("add--",student) print('-------------6集合运算------------------------------') a = set('abcd') b = set('cdef') print(a) print(a - b) # a 和 b 的差集 print(a | b) # a 和 b 的并集 print(a & b) # a 和 b 的交集 print(a ^ b) # a 和 b 中不同时存在的元素 print('-------------7----键值对操作-------------------------') dict = {} dict['one'] = "1 - 键值对操作" dict[2] = "2 - 操作工具" tinydict = {'name': 'runoob', 'code': 1, 'site': 'www.runoob.com'} print (dict['one']) # 输出键为 'one' 的值 print (dict[2]) # 输出键为 2 的值 print (tinydict) # 输出完整的字典 print (tinydict["name"]) # 输出键为 name 的值 print (tinydict.keys()) # 输出所有键 print (tinydict.values()) # 输出所有值 print ("copy-",tinydict.copy()) # 复制 print('-------------8---特殊字符---------------------------') # 3个引号的特殊功能,可以直接打印多行内容,而单引号,双引号情况需要显示输入 才能换行 para_str = """这是一个多行字 符串的实例 多行字符串可以使用制表符 也可以使用换行符 [ ]。 TAB ( )。 """ print (para_str) print('-------------9------------------------------') yourSlushUStr = "\u559c\u6b22\u4e00\u4e2a\u4eba"; decodedUnicodeStr = yourSlushUStr.decode("unicode-escape") print decodedUnicodeStr
爬虫小例子:
属性
r.status_code
http请求的返回状态,200表示连接成功,404表示连接失败
r.text
http响应内容的字符串形式,url对应的页面内容
r.encoding
从HTTP header中猜测的响应内容编码方式
r.apparent_encoding
从内容分析出的响应内容的编码方式(备选编码方式)
r.content
HTTP响应内容的二进制形式
r.headers
http响应内容的头部内容
案例1:
# -*- coding: UTF-8 -*- import requests url="http://111.231.135.29/anon/home" try: r=requests.get(url) # r.raise_for_status()的功能是判断返回的状态码,如果状态码不是200(如404),则抛出异常 r.raise_for_status() r.encoding = "utf-8" # r.encoding = r.apparent_encoding print r.encoding # http响应内容的字符串形式,url对应的页面内容 # print r.text # http响应内容的头部内容 print r.headers # HTTP响应内容的二进制形式 # print r.content except: print "failed"
案例2:爬虫获取百度搜索结果
# coding: UTF-8 import requests url="http://www.baidu.com/s" kv={"wd":"rebecca"} r=requests.get(url,params=kv) r.encoding="utf-8" print r.request.url print r.text[:2000]
解决网站爬虫限制
有些网站限制了网络请求的来源,来阻止爬虫。一般是通过’user-agent’属性来区分。
通过
print r.request.headers
来查看user-agent属性。
requests库写的代码默认user-agent(用户代理)是’python-requests/x.xx.x’(x表示版本号)。如果访问不成功,可尝试修改’user-agent’属性。
方法如下:
1. 先构建一个字典
ua={"user-agent":"Mozilla/5.0"}
其中”Mozilla/5.0”是浏览器的普遍标识。
2. 在get方法里面加一个参数
r=requests.get(url,headers=ua)
例子3:
import requests url="http://www.cnblogs.com/hjw1" ua={"user-agent":"Mozilla/5.0"} r=requests.get(url) print r.request.headers r=requests.get(url,headers=ua) print r.request.headers
注:深究python爬虫-html可用 解析器beautifulsoup