来源:https://zhuanlan.zhihu.com/p/76709712
0 简介
CART剪枝算法从"完全生长"的决策树的底端剪去一些子树,使决策树变小(模型变简单),从而能够对未知数据有更准确的预测。
分两步:
1.从生产算法产生的整体的树 的最底端开始不断剪枝,直至剪到整个树
的根结点为止,从而形成了一个子树序列
;
2.通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选出最优子树。
1.剪枝,形成一个子树序列
剪枝剪枝,怎么来剪?
从前面第4节将的剪枝内容来看,我们需要整一个损失函数来控制剪枝。
这个损失函数为:
其中,T为任意子树, 为对训练数据的预测误差(如基尼指数),
为子树的叶结点个数,表示树的复杂度的。
为参数,
为参数是
时的子树T的整体损失。
参数 权衡训练数据的拟合程度与模型的复杂度。
上述关于损失函数的定义,在前面的章节中已经介绍的非常多了,看过前面的这部分就不难理解。以后的章节中,如果遇到前面详细介绍过的内容,除非必要,就都不啰嗦了。
对固定的一个 值,一定存在使损失函数
最小的子树,将其表示为
。这个
取值越大,最优子树就偏向于简单地子树(即叶结点少),
取值越小,最优子树偏向于与训练数据集更好地拟合。我们可以想象一个极端情况,当
时,最优子树是根结点构成的单结点树;当
时,最优子树就是整体树本身。(这个一定要结合上面的损失函数公式来理解)。
Breiman(CART提出者)等人证明:可以用递归的方法对树进行剪枝。什么意思呢?就是将 从0开始逐渐增大,
,产生一系列的区间
;对每一个
取值,都能得到一个最优子树,最终得到对应的最优子树集
,序列中
是整树,一直到
(根结点构成的单结点树),是嵌套的。子树序列对应着区间
。

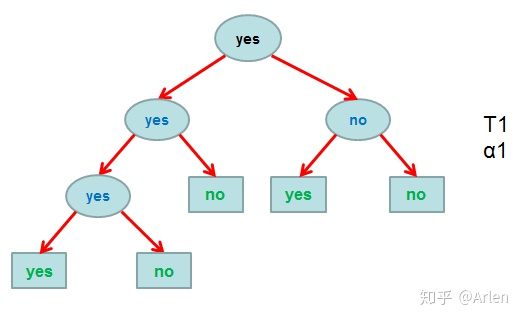


整个剪枝过程的示意图如上。接下来我们来看看具体数学过程是怎样的。
从整体树 开始剪枝。对于
的任意内部结点t(除叶结点外的所有结点,包括根结点),计算以t为单结点树的损失函数:
如下图
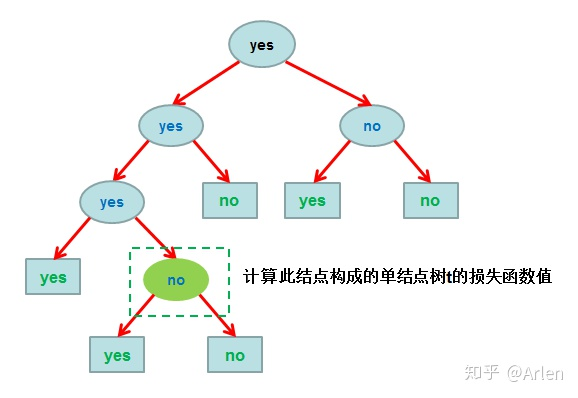
然后计算以t为根结点的子树 的损失函数:

如下图

接下来进行 的比较:
1) 当 ,有不等式
意思是,此时如果保留这个子树,得到的总的损失函数是会比剪掉它更小的,所以我们选择保留子树不剪。
2) 当 增大时,在某一
值时有
此时,由公式可以推出: 。
在这时取相同的损失函数值。但由于t的结点少,因此t比
更可取,故应对子树
进行剪枝。
3) 当 再增大时,1)中的不等式反向,即
此时就应该再取下一个内部结点,进行下一步剪枝判断了。
对 中每一内部结点t,计算:
(即对应着不同的
取值)
这个g(t)表示剪枝后整体损失函数减少的程度。在 中减去g(t)值最小的子树
,将得到的剩下的子树作为
,同时将最小的g(t)设为
。
为区间
的最优子树。
如此剪枝下去,直至得到根结点。在这一过程中,不断地增加 的值,得到更小的子树,产生新的区间。就得到了最优子树序列,
,剪枝后对新的叶结点t以多数表决法决定其类。
2.在剪枝得到的子树序列 ![[公式]](https://www.zhihu.com/equation?tex=T_0%2CT_1%2C...%2CT_n) 中通过交叉验证选取最优子树
中通过交叉验证选取最优子树 ![[公式]](https://www.zhihu.com/equation?tex=T_%7B%5Calpha%7D)
利用独立的验证数据集,测试子树序列 中各棵子树的平方误差或基尼指数。选择平方误差或基尼指数最小的决策树作为最优的决策树。在子树序列中,每棵子树
都对应于一个参数
。所以,当最优子树
确定时,对应的
也确定了,即得到最优决策树
。