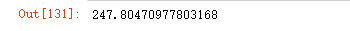第四期 当Pandas遇上NumPy
81.导入并查看pandas与numpy版本
import pandas as pd
import numpy as np
print(np.__version__)
print(pd.__version__)

82.从NumPy数组创建DataFrame
#备注 使用numpy生成20个0-100随机数
tem = np.random.randint(1,100,20)
df1 = pd.DataFrame(tem)
df1

83.从NumPy数组创建DataFrame
#备注 使用numpy生成20个0-100固定步长的数
tem = np.arange(0,100,5)
df2 = pd.DataFrame(tem)
df2

84.从NumPy数组创建DataFrame
#备注 使用numpy生成20个指定分布(如标准正态分布)的数
tem = np.random.normal(0, 1, 20)
df3 = pd.DataFrame(tem)
df3
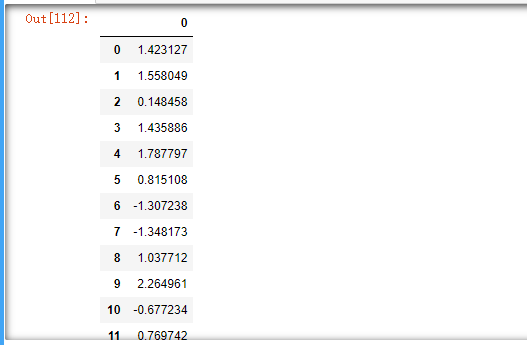
85.将df1,df2,df3按照行合并为新DataFrame
df = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
df

86.将df1,df2,df3按照列合并为新DataFrame
df = pd.concat([df1,df2,df3],axis=1,ignore_index=True)
df

87.查看df所有数据的最小值、25%分位数、中位数、75%分位数、最大值
print(np.percentile(df, q=[0, 25, 50, 75, 100]))
[-1.34817283 1.41754194 23.5 50. 95. ]
88.修改列名为col1,col2,col3
df.columns = ['col1','col2','col3']
89.提取第一列中不在第二列出现的数字
df['col1'][~df['col1'].isin(df['col2'])]

90.提取第一列和第二列出现频率最高的三个数字
temp = df['col1'].append(df['col2'])
temp.value_counts().index[:3]
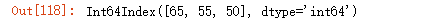
91.提取第一列中可以整除5的数字位置
np.argwhere(df['col1'] % 5==0)

92.计算第一列数字前一个与后一个的差值
df['col1'].diff().tolist()

93.将col1,col2,clo3三列顺序颠倒
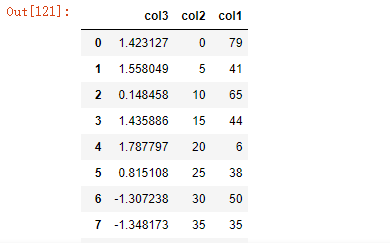
94.提取第一列位置在1,10,15的数字
df['col1'].take([1,10,15])
# 等价于
df.iloc[[1,10,15],0]
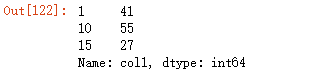
95.查找第一列的局部最大值位置
#备注 即比它前一个与后一个数字的都大的数字
tem = np.diff(np.sign(np.diff(df['col1'])))
np.where(tem == -2)[0] + 1

96.按行计算df的每一行均值
df[['col1','col2','col3']].mean(axis=1)

97.对第二列计算移动平均值
#备注 每次移动三个位置,不可以使用自定义函数
np.convolve(df['col2'], np.ones(3)/3, mode='valid')

98.将数据按照第三列值的大小升序排列
df.sort_values("col3",inplace=True)
99.将第一列大于50的数字修改为'高'
df.col1[df['col1'] > 50]= '高'
100.计算第二列与第三列之间的欧式距离
np.linalg.norm(df['col2']-df['col3'])