0 简介
0.1 主题

0.2 目标
1) 能够掌握传统的集成框架的类型
2) 能够掌握GBDT的算法过程
3) 能够掌握GBDT的残差
1 提升的概念




2 基本函数
所有可行的弱函数集合(基函数)
3 目标函数
3.1 目标函数策略


3.2 损失函数

4 最优求解思路


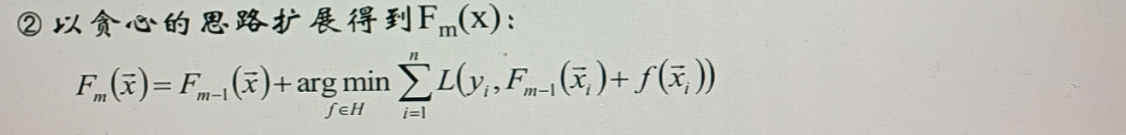
5 最优函数
5.1 过程简介


5.2 GBDT算法核心:残差拟合样本


5.3 小结

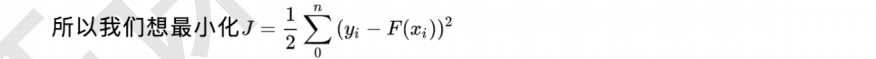


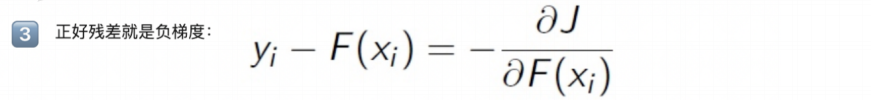

6 GDBT算法实验
import gzip import pickle as pkl from sklearn.model_selection import train_test_split def load_data(path): f = gzip.open(path, 'rb') try: #Python3 train_set, valid_set, test_set = pkl.load(f, encoding='latin1') except: #Python2 train_set, valid_set, test_set = pkl.load(f) f.close() return(train_set,valid_set,test_set) path = 'mnist.pkl.gz' train_set,valid_set,test_set = load_data(path) Xtrain,_,ytrain,_ = train_test_split(train_set[0], train_set[1], test_size=0.9) Xtest,_,ytest,_ = train_test_split(test_set[0], test_set[1], test_size=0.9) print(Xtrain.shape, ytrain.shape, Xtest.shape, ytest.shape)
(5000, 784) (5000,) (1000, 784) (1000,)
from sklearn.ensemble import GradientBoostingClassifier import numpy as np import time clf = GradientBoostingClassifier(n_estimators=10, learning_rate=0.1, max_depth=3) start_time = time.time() clf.fit(Xtrain, ytrain) end_time = time.time() print('The training time = {}'.format(end_time - start_time)) #prediction and evaluation pred = clf.predict(Xtest) accuracy = np.sum(pred == ytest) / pred.shape[0] print('Test accuracy = {}'.format(accuracy))
The training time = 22.512996673583984 Test accuracy = 0.807
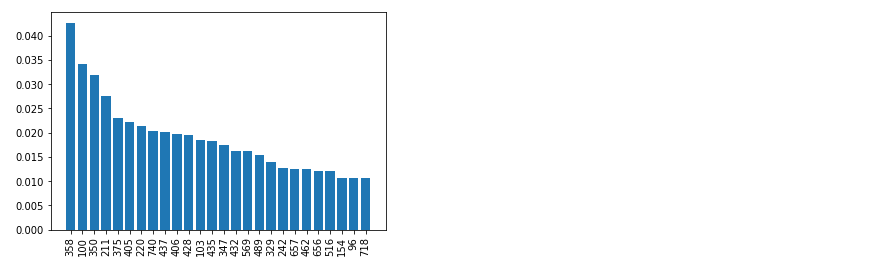
- 集成算法可以得出特征的重要度,说白了就是看各个树使用的特征情况,使用的多当然就重要了,这是分类器告诉我们的
%matplotlib inline import matplotlib.pyplot as plt plt.hist(clf.feature_importances_) print(max(clf.feature_importances_), min(clf.feature_importances_))
0.042681420232887304 0.0

from collections import OrderedDict d = {} for i in range(len(clf.feature_importances_)): if clf.feature_importances_[i] > 0.01: d[i] = clf.feature_importances_[i] sorted_feature_importances = OrderedDict(sorted(d.items(), key=lambda x:x[1], reverse=True)) D = sorted_feature_importances rects = plt.bar(range(len(D)), D.values(), align='center') plt.xticks(range(len(D)), D.keys(),rotation=90) plt.show()
7 Shrinkage(衰减)与Step(步长)

8 参数设置和正则化

9 总结
9.1 GDBT主要由Regression Decision Tree, Gradient Boosting, Shrinkage 三个概念组成

9.2 为什么GBDT的树深较RF通常比较浅(RF是通过减少模型的方差来提高性能,而GBDT是减少模型的偏差来提高性能的原理)

10 笔面试相关
10.1 什么是集成学习?集成学习有哪些框架?简单介绍各个框架的常用算法?

10.2 GBDT相比于决策树有什么优点/
