1 工程目录结构
2 flink 读取 Kafka

package com.atguigu.day8
import java.util.Properties
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
object KafkaConsumerExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// kafka consumer config
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val stream = env.addSource(new FlinkKafkaConsumer011[String](
"atguigu",
new SimpleStringSchema(),
properties)
)
stream.print()
env.execute()
}
}
3 flink 写入 Kafka
package com.atguigu.day8
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011}
object FlinkKafkaProducerExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val conProperties = new Properties()
conProperties.setProperty("bootstrap.servers", "localhost:9092")
conProperties.setProperty("group.id", "consumer-group")
conProperties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
conProperties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
conProperties.setProperty("auto.offset.reset", "latest")
val stream = env.addSource(new FlinkKafkaConsumer011[String](
"test",
new SimpleStringSchema(),
conProperties
))
val prodProperties = new Properties()
prodProperties.setProperty("bootstrap.servers", "localhost:9092")
stream
.addSink(new FlinkKafkaProducer011[String](
"test",
new SimpleStringSchema(),
prodProperties
))
stream.print()
env.execute()
}
}
4 flink + kafka exactly once
package com.atguigu.day8 import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011} object FlinkKafkaProducerExample { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.enableCheckpointing(6000) // 启动检查点并设置保存检查点,时间间隔1分/次 env.setParallelism(1) val conProperties = new Properties() conProperties.setProperty("bootstrap.servers", "localhost:9092") conProperties.setProperty("group.id", "consumer-group") conProperties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") conProperties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") conProperties.setProperty("auto.offset.reset", "latest") val stream = env.addSource(new FlinkKafkaConsumer011[String]( "test", new SimpleStringSchema(), conProperties )) val prodProperties = new Properties() prodProperties.setProperty("bootstrap.servers", "localhost:9092") stream .addSink(new FlinkKafkaProducer011[String]( "test", new SimpleStringSchema(), prodProperties )) stream.print() env.execute() } }
5 flink kafkaSink自定义序列化类(实现按需流向不同topic)
5.1 代码
import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011} import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema case class SensorReading(name:String,time:Long,tempature:Double) object kafkaSinkTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment //消费kafka流进行处理 val properties = new Properties() properties.setProperty("bootstrap.servers", "localhost:9092") properties.setProperty("group.id", "consumer-group") properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") properties.setProperty("auto.offset.reset", "latest") //FlinkKafkaConsumer011(topic: String, valueDeserializer: DeserializationSchema[T], props: Properties) val dataStream = env.addSource(new FlinkKafkaConsumer011[String]("test_lir",new SimpleStringSchema(),properties)) val senseStream = dataStream.map(f=>{ val arr = f.split(",") SensorReading(arr(0).trim,arr(1).trim.toLong,arr(2).trim.toDouble) }) /* dataStream.addSink( new FlinkKafkaProducer011[String]("localhost:9092","test_result",new SimpleStringSchema())) FlinkKafkaProducer011构造器参数:(String brokerList, String topicId, KeyedSerializationSchema<IN> serializationSchema) SimpleStringSchema为默认的序列化 */ senseStream.addSink( new FlinkKafkaProducer011[SensorReading]("localhost:9092","test_result",new MySchema)) env.execute("kafka sink test") } class MySchema extends KeyedSerializationSchema[SensorReading]{ override def serializeKey(t: SensorReading): Array[Byte] = t.name.getBytes() //此方法才是实际底层produce的topic,FlinkKafkaProducer011中的topic_name级别不如此级别,重写该方法逻辑可以实现按需流向不同topic override def getTargetTopic(t: SensorReading): String = "test_result2" override def serializeValue(t: SensorReading): Array[Byte] = t.toString.getBytes } }
5.2 注意
getTargetTopic中的返回字符串为实际写入的topic名,级别比FlinkKafkaProducer011中的topic要高,从FlinkKafkaProducer011源码可知,只有targetTopic为空的时候才会使用FlinkKafkaProducer011中的topic
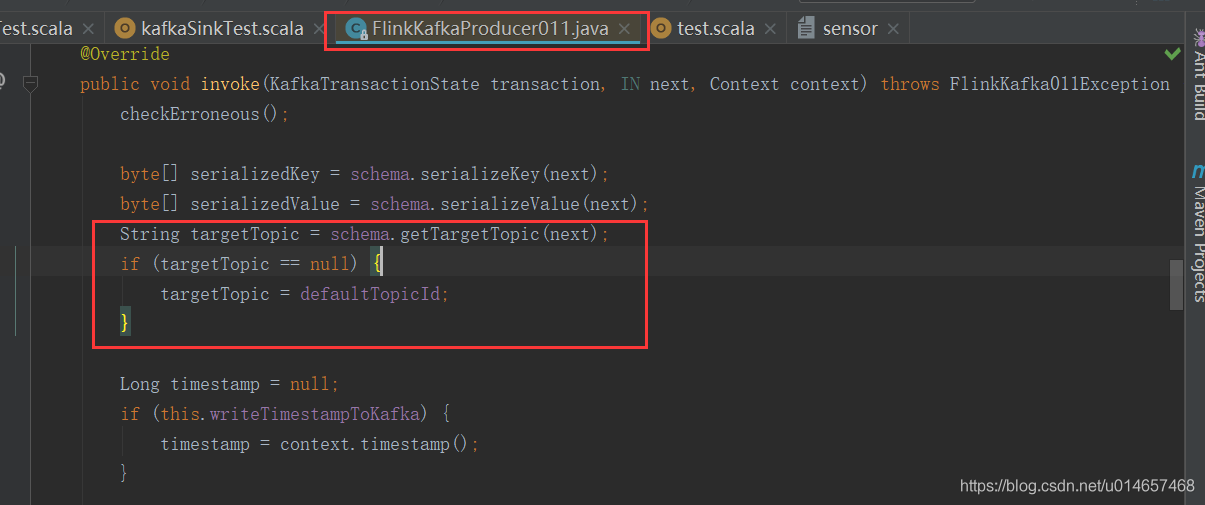
6 flink写入kafka之自定义分区器
6.1 代码
主程序
/*自定义分区*/ @SuppressWarnings("unchecked") FlinkKafkaProducer010<String> flinkProducer = new FlinkKafkaProducer010<String>( "topic名字", //自定义元数据 new MySchema(), //kafka producer的属性 pro, //自定义分区器 new MyPartitioner()); flinkDataStream.addSink(flinkProducer).setParallelism(2);
我们自己定义的元数据类
public static class MySchema implements KeyedSerializationSchema { //element: 具体数据 /** * 要发送的key * * @param element 原数据 * @return key.getBytes */ @Override public byte[] serializeKey(Object element) { //这里可以随便取你想要的key,然后下面分区器就根据这个key去决定发送到kafka哪个分区中, //element就是flink流中的真实数据,取出key后要转成字节数组 return element.toString().split("u0000")[0].getBytes(); } /** * 要发送的value * * @param element 原数据 * @return value.getBytes */ @Override public byte[] serializeValue(Object element) { //要序列化的value,这里一般就原封不动的转成字节数组就行了 return element.toString().getBytes(); } @Override public String getTargetTopic(Object element) { //这里返回要发送的topic名字,没什么用,可以不做处理 return null; } }
- 我们自己定义的分区器
public static class MyPartitioner extends FlinkKafkaPartitioner { /** * @param record 正常的记录 * @param key KeyedSerializationSchema中配置的key * @param value KeyedSerializationSchema中配置的value * @param targetTopic targetTopic * @param partitions partition列表[0, 1, 2, 3, 4] * @return partition */ @Override public int partition(Object record, byte[] key, byte[] value, String targetTopic, int[] partitions) { //这里接收到的key是上面MySchema()中序列化后的key,需要转成string,然后取key的hash值`%`上kafka分区数量 return Math.abs(new String(key).hashCode() % partitions.length); } }
这样flink发送到kafka的数据就不是随便发的了,是根据你定义的key发送的
7 flink读取之kafka自定义反序列化
反序列化为json
package com.atguigu.exercise.ETL.caiutil import com.alibaba.fastjson.{JSON, JSONObject} import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation} import org.apache.flink.streaming.util.serialization.KeyedDeserializationSchema class CustomDeSerializationSchema extends KeyedDeserializationSchema[JSONObject]{ //JSONObject 反序列化后的数据类型 override def isEndOfStream(t: JSONObject): Boolean = { false } override def deserialize(bytes: Array[Byte], bytes1: Array[Byte], s: String, i: Int, l: Long): JSONObject = { //bytes 键 bytes1 键值(存放的数据信息) s topic名 i 分区 l offset 偏移量 val datastr = new String(bytes1,"UTF-8") val datajson = JSON.parseObject(datastr) datajson } override def getProducedType: TypeInformation[JSONObject] = { TypeInformation.of(new TypeHint[JSONObject] {}) } }
应用
package com.atguigu.exercise.ETL import java.util.Properties import com.alibaba.fastjson.JSONObject import com.atguigu.exercise.ETL.caiutil.CustomDeSerializationSchema import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer011, FlinkKafkaProducer011} import org.apache.flink.streaming.util.serialization.SimpleStringSchema object SourceFromKafkaExample { def main(args: Array[String]): Unit = { val bsEnv = StreamExecutionEnvironment.getExecutionEnvironment bsEnv.setParallelism(1) val conProperties = new Properties() conProperties.setProperty("bootstrap.servers", "localhost:9092") conProperties.setProperty("group.id", "consumer-group") conProperties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") conProperties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") conProperties.setProperty("auto.offset.reset", "latest") val stream = bsEnv.addSource(new FlinkKafkaConsumer011[JSONObject]( "test", new CustomDeSerializationSchema(), conProperties )) val resultStream = stream.filter(data => data.isInstanceOf[JSONObject]) val prodProperties = new Properties() prodProperties.setProperty("bootstrap.servers", "localhost:9092") resultStream.print() bsEnv.execute() } }
参考资料:
https://blog.csdn.net/qq_24124009/article/details/89505189
https://bbs.huaweicloud.com/blogs/148532
https://blog.csdn.net/qq_31866793/article/details/108344286