1, KNN算法概述
简单地说,KNN算法采用测量不同特征值之间的距离方法进行分类。
举个例子:
我们可以通过电影里出现 kiss(接吻) 和 kick(打斗) 的次数多少来判断它是属于Romance type(爱情片)还是动作片
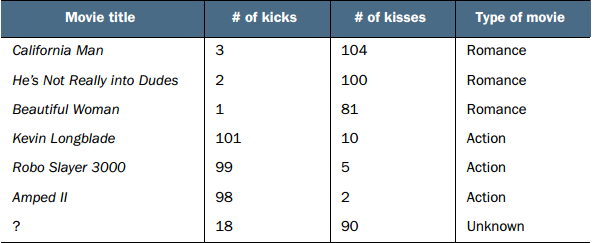
假设我们统计了前6部电影的kicks次数,kisses的次数和类型,现在问题来了,如果我知道这么一部电影它的kicks次数为18,kisses次数为90,那么它属于什么类型呢? KNN可以用来解决这个问题。
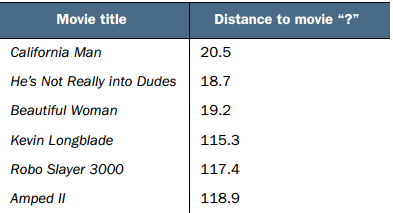
如上图 我们可以计算 '?'未知电影和已知的所有电影的欧几里得距离,然后进行排序,选出其中前3部电影,统计它们分别属于什么类型。 可以看出和未知电影距离近的3部电影都是爱情电影,因此我们可以将未知电影划分成 爱情片 。
现在可以得出KNN算法的一般描述:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
2, KNN算法的简单实现
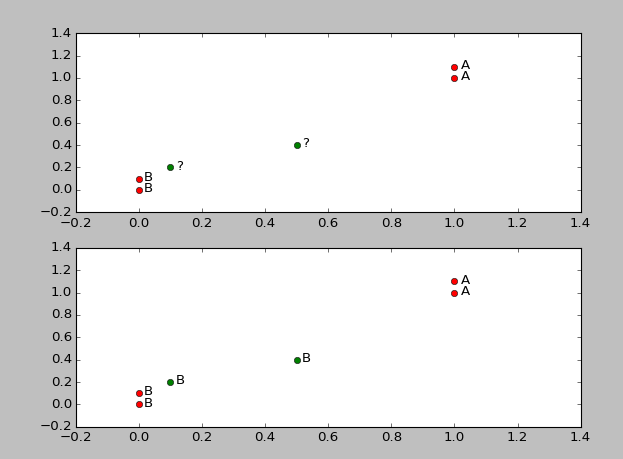
假设有四个点 (1.0,1.1),(1.0,1.0),(0,0),(0,0.1)类别分别为 ('A','A','B','B' ),现在输入两个点(0.5,0.4),(0.1,0.2) 预测它们的类别。 (0.5,0.4) ==> ? (0.1,0.2) ==>?
代码实现:


__author__ = 'xianweizheng' from numpy import * import matplotlib.pyplot as plt import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group, labels def dataSetPlot(group, labels): x = [] ; y = [] ;len =group.__len__() for i in arange(0,len): x.append([group[i][0]]) y.append([group[i][1]]) plt.text(group[i][0]+0.02,group[i][1]-0.02,labels[i]) return x,y def kNNClassify(inX, dataSet, labels, k): '''classify using kNN step 1: calculate Euclidean distance step 2: sort the distance step 3: choose the min k distance step 4: count the times labels occur step 5: the max voted class will return ''' ## step 1: calculate Euclidean distance dataSetSize = dataSet.shape[0] #dataSet.shape() 为 (4,2)表示4行两列 diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(a,(n1,n2)) n2表示列重复能n2次,n1表示行重复n1次 sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) #diffMat 行相加 构成一个新的list distances = array(sqDistances**0.5) ## step 2: sort the distance # argsort 标注出一个序列y,这个序列式是 排序后的数,在未排序数组x中出现的位置 sortedDistIndicies = distances.argsort() classCount={} # define a dictionary (can be append element) ## step 3: choose the min k distance for i in arange(k): voteIlabel = labels[sortedDistIndicies[i]] ## step 4: count the times labels occur classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 ## step 5: the max voted class will return maxCount = 0 for key, value in classCount.items(): if value > maxCount: maxCount = value maxIndex = key return maxIndex def display(inX,outputLabel): print("Your input is:", inX, " and classified to class: ", outputLabel ) def testKnnSimple(): group, labels = createDataSet() k=3 input = array([[0.5,0.4],[0.1,0.2]]) unknowLabels =[] outputLabels =[] for i in arange(input.__len__()): unknowLabels.append('?') outputLabel = kNNClassify(input[i], group, labels, k) display(input[i],outputLabel) outputLabels.append(outputLabel) plt.figure("Data plot") plt.subplot(211) plt.xlim(-0.2,1.4);plt.ylim(-0.2,1.4) x,y = dataSetPlot(group,labels) plt.plot(x,y,'ro') x,y = dataSetPlot(input, unknowLabels) plt.plot(x,y,'go') plt.subplot(212) plt.xlim(-0.2,1.4);plt.ylim(-0.2,1.4) x,y = dataSetPlot(group,labels) plt.plot(x,y,'ro') x,y = dataSetPlot(input, outputLabels) plt.plot(x,y,'go') plt.show() testKnnSimple()
运行结果: