0、文章参考链接:
https://blog.csdn.net/illikang/article/details/82019945
https://www.zybuluo.com/hanbingtao/note/476663
1、神经网络简介
(1)准备知识
①设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
②神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
③结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
④权值乘以输入值加上偏差值之后,再通过激活函数对结果进行一次处理,得出的输出就是该节点最终的结果。
(2)神经网络的求解是通过反向传播的技术来解决的。通过梯度下降法。问题是
①反向传播从输出层开始一步一步传到Layer 1时,越到低层,联结的权值变化越小,直到没变化。这种叫梯度消失。
②越到第一层,变化越来越大。这种叫梯度爆炸。常见于RNN
(3)一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
我们有一个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。
已知的属性称之为特征,未知的属性称之为目标。
2、感知器(神经元)
(1)神经元。神经元也叫做感知器。
在“感知器”中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。
(2)阶跃函数来作为激活函数

(3)功能
①实现简单的布尔运算,二分类问题。
②它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。
(4)权值和偏置项修改策略
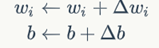
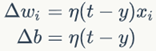
wi是与输入xi对应的权重项,b是偏置项。事实上,可以把b看作是值永远为1的输入xb所对应的权重。t是训练样本的实际值,一般称之为label。而y是感知器的输出值。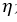 是一个称为学习速率的常数,其作用是控制每一步调整权重的幅度。
是一个称为学习速率的常数,其作用是控制每一步调整权重的幅度。
每次从训练数据中取出一个样本的输入向量,使用感知器计算其输出,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
3、神经网络
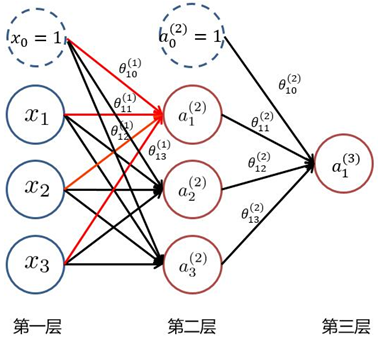
(1)分层:输入层、隐藏层、输出层
输入层:
隐藏层: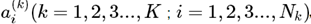 ,表示表示第k层中,第 i个神经元的激活值, Nk表示第k层的神经元个数,k=1时表示输入层(激活值)。
,表示表示第k层中,第 i个神经元的激活值, Nk表示第k层的神经元个数,k=1时表示输入层(激活值)。
我们使用 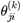 来表示第k 层的参数(边权)。
来表示第k 层的参数(边权)。
激活值:
在这里x0和a0是偏置项。
(2)偏置节点的作用:是决定竖直平面沿着垂直于直线方向移动的距离
https://blog.csdn.net/xwd18280820053/article/details/70681750
(3)损失函数
在监督学习下,对于一个样本,我们知道它的特征x,以及标记y。同时,我们还可以根据模型h(x)计算得到输出。注意这里面我们用y表示训练样本里面的标记,也就是实际值;用带上划线的表示模型计算的出来的预测值。我们当然希望模型计算出来的和越接近越好。
我们可以用y和的差的平方的½来表示它们的接近程度。
利用梯度下降法求解。
https://www.zybuluo.com/hanbingtao/note/448086
