Scrapy——6
怎样进行APP抓包? 1.连接网络
- 安装fiddler,并且进行配置:
Tools >> options >> connections >> 勾选 allow remote computers to connect
- 查看本机ip地址:
在cmd窗口中,输入 ipconfig ,查看 以太网 ,可以看到
IPv4 地址...............:192.168.0.104
这个192.168.*.***(192.168.0.104) 就是你的本机IP
- 确保手机连接了wifi,并且和电脑是在同一个局域网,
- 设置代理,在WiFi中长按连接的wifi选择设置代理

- 在手机中,打开浏览器,访问
http://10.209.143:1234
IP:是第二步查看到的ip地址,替换成你自己的IP
port:8888是你在fiddler中配置的
注意:有些浏览器会显示打不开,更换其他浏览器就可以了
怎样进行APP抓包? 2.访问网络

打开后点击最后的链接(光标处),进行证书安装就可以了
怎样进行APP抓包? 3.安装证书
- 安装 证书
部分手机可以直接点击 安装
部分手机需要 设置 >> wifi(或WLAN) >> 高级设置 >> 安装证书 >>
选中刚刚下载的 证书文件 FiddlerRoot.cer >> 确定
设置(Settings) >> 更多设置 >> 系统安全 >> 从存储设备安装
为证书命名 , 输入自己喜欢的名字,譬如 fiddler ,确定 , 显示 证书安装完成
安装完成后,在 设置(Settings) >> 更多设置 >> 系统安全 >> 信任的凭证 >>
系统和用户2个tab页 >> 用户 >> 可以查看到 DO_NOT_RUST_FiddlerRoot
PS: 不安装证书,抓取http的数据是没问题的,但是抓取不了https的数据
怎样进行APP抓包? 4.手机抓包
注意:
1、大部分app都可以直接抓包
2、少部分app没办法直接获取,需要 wireshark、反编译、脱壳 等方式去查找加密算法
3、app抓包一般都是抓取到服务器返回的json数据包
scrapy框架抓取APP豆果美食数据
手机打开豆果美食APP,同时打开fiddler,浏览你需要爬取的数据页面,然后就可以在fiddler中分析抓取的网络请求
因为手机数据一般都是json格式的数据,所以多注意网络请求的格式即可

很快就找到了我们需要的请求,接下来就用scrapy模拟请求解析数据
- 创建项目

- Local/Scrapy/douguo/douguo/items.py 设置需要保存的数据(作者、菜名、用时、难度、前言、图片链接)
import scrapy class DouguoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() auth = scrapy.Field() cook_name = scrapy.Field() cook_time = scrapy.Field() cook_difficulty = scrapy.Field() cook_story = scrapy.Field() img = scrapy.Field()
- Local/Scrapy/douguo/douguo/settings.py 设置爬虫协议
# Obey robots.txt rules ROBOTSTXT_OBEY = False
Local/Scrapy/douguo/douguo/spiders/douguojiachang.py 编写代码
- 根据网络请求数据的方法,进行post请求,自行分析需要的请求头
- scrapy获取json数据,用的是response.body,再用json.dumps()转换
# -*- coding: utf-8 -*- import scrapy import json from ..items import DouguoItem class DouguoJiachangSpider(scrapy.Spider): name = 'douguo_jiachang' # allowed_domains = ['baidu.com'] # start_urls = ['http://api.douguo.net/recipe/v2/search/0/20'] page = 0 def start_requests(self): base_url = 'http://api.douguo.net/recipe/v2/search/{}/20' url = base_url.format(self.page) data = { 'client': '4', '_session': '1542354711458863254010224946', 'keyword': '家常菜', 'order': '0', '_vs': '400' } self.page += 20 yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse) def parse(self, response): date = json.loads(response.body.decode()) # 将json格式数据转换成字典 t = date.get('result').get('list') for i in t: douguo_item = DouguoItem() douguo_item['auth'] = i.get('r').get('an') douguo_item['cook_name'] = i.get('r').get('n') douguo_item['cook_time'] = i.get('r').get('cook_time') douguo_item['cook_difficulty'] = i.get('r').get('cook_difficulty') douguo_item['cook_story'] = i.get('r').get('cookstory') douguo_item['image_url'] = i.get('r').get('p') yield douguo_item
结果:

怎样用scrapy框架下载图片
在前面的代码基础上继续更加功能
- Local/Scrapy/douguo/douguo/settings.py 设置图片下载路径,设置下载延迟,激活相应的图片下载管道,调整相应优先级
- 路径IMAGES_STORE是固定写法,后面的DOWNLOAD_DELAT也是,setting里的都是如此
- “.”表示当前路径,属于相对路径的写法,也可以写成绝对路径
- 管道优先级,数字越小,优先级越高
# Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'douguo.pipelines.DouguoPipeline': 229, 'douguo.pipelines.ImagePipline': 300, } ............. ............. ............. IMAGES_STORE = './images/' DOWNLOAD_DELAY = 1
- Local/Scrapy/douguo/douguo/items.py 设置相应的图片下载链接和下载路径
import scrapy class DouguoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() auth = scrapy.Field() cook_name = scrapy.Field() cook_time = scrapy.Field() cook_difficulty = scrapy.Field() cook_story = scrapy.Field() image_url = scrapy.Field() image_path = scrapy.Field()
- Local/Scrapy/douguo/douguo/pipelines.py 设置图片下载管
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import os import scrapy from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem from .settings import IMAGES_STORE class DouguoPipeline(object): def process_item(self, item, spider): print(item) return item class ImagePipline(ImagesPipeline): def get_media_requests(self, item, info): ''' 对图片的地址生成Request请求进行下载 ''' yield scrapy.Request(url=item['image_url']) def item_completed(self, results, item, info): ''' 当图片下载完成之后,调用方法 ''' format = '.' + item['image_url'].split('.')[-1] # 设置图片格式 image_path = [x['path'] for ok, x in results if ok] # 获取图片的相对路径 old_path = IMAGES_STORE + image_path[0] # 老的路径 new_path = IMAGES_STORE + item['cook_name'] + format # 新的路径 路径+菜名+格式 item['image_path'] = new_path # 把新的路径传给item try: os.rename(old_path, new_path) # 改变下载的位置 except: raise DropItem('Image Download Failed') return item
结果:
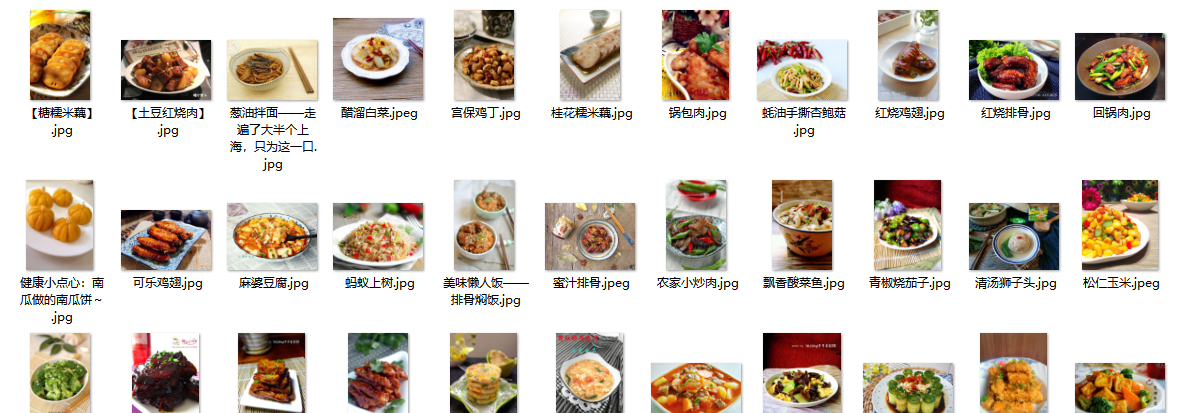
怎样用scrapy框架下载图片
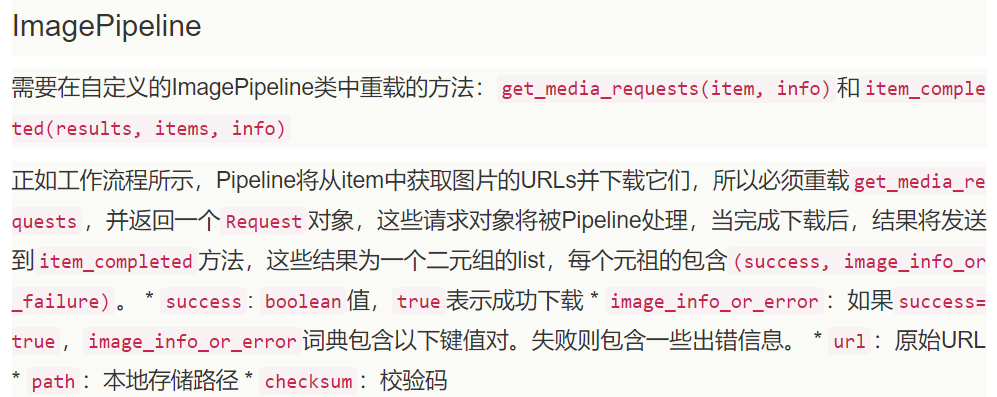
ImagePipeline:
Scrapy用ImagesPipeline类提供一种方便的方式来下载和存储图片。需要PIL库支持。

怎样用scrapy框架去下载斗鱼APP的图片?










常见问题

