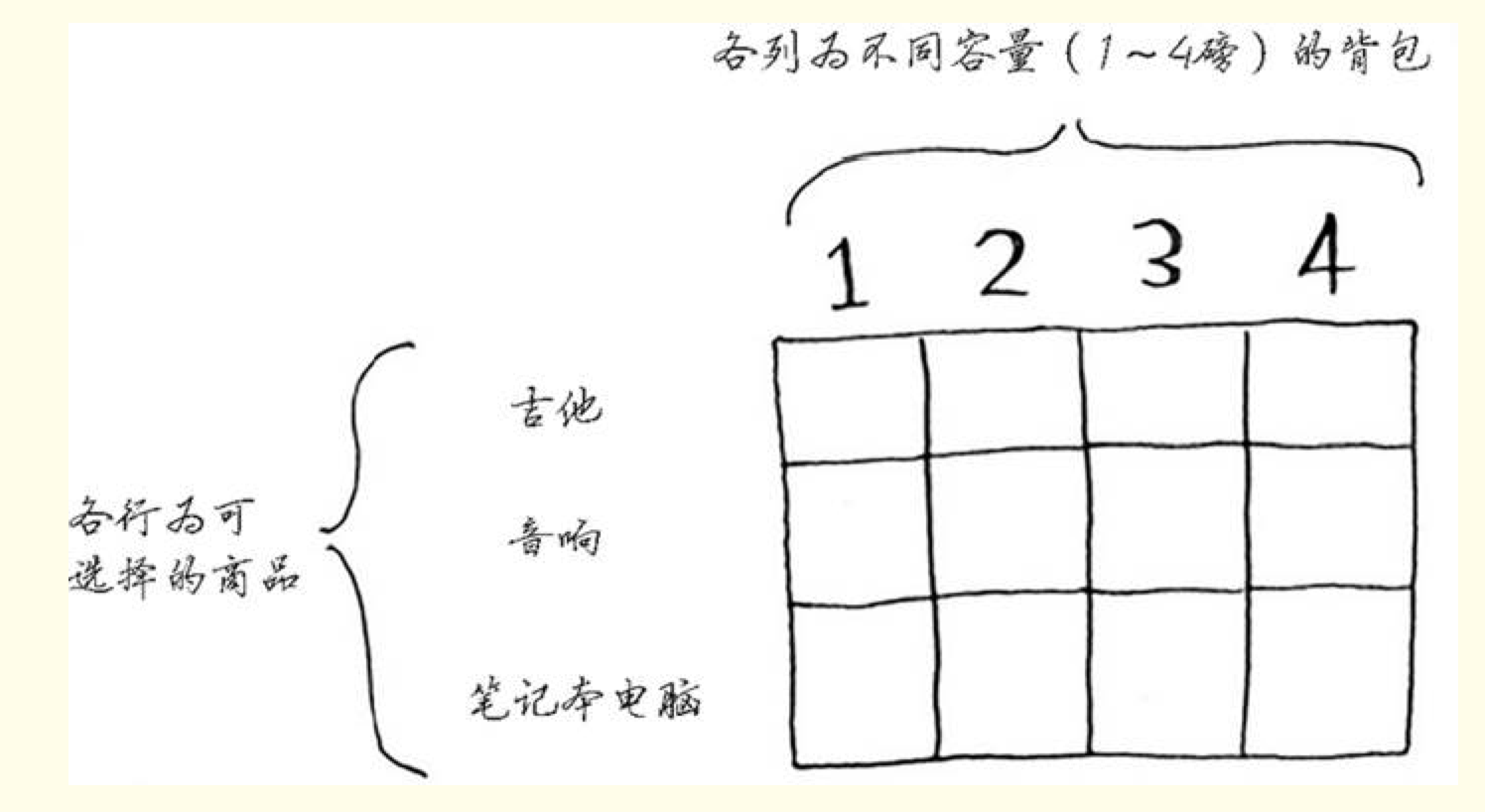
行和列的思想:
from collections import namedtuple
from pprint import pprint
"""
动态规划算法
旅行行程最大化:
假设要去伦敦独家,假期是两天,但是想去的游览地点很多,你没发前往每一个地方游览,因此你需要列一个清单。
对于想起的名声景点,都列出所需的时间和景点的推荐指数,设计算法,在指定的时间内将此次旅行规划到指数最大化
背包问题:
假设你是一个小偷,你的背包只能装4磅的物品,现有一个可偷清单,分别标有物品的重量和价值,设计算法实现偷窃的价值最大化
野营问题:
假设你要出克玩,你的背包容量为6磅,需要决定携带哪些物品,实现价值最大化
附加:
1. 有些算法并非精确地解决步骤,而只是帮助你理清思路的框架
2. 相同的系数,最终保留的是偏后者的,就是清单里面靠后的,所以相同系数自己比较喜欢的,要写在后面
"""
item = namedtuple('项目', ['name', 'requirement', 'coefficient'])
def main(data, max_requirement):
"""
data:计划清单
max_requirement: 预计最大条件
"""
# 统计列数
requirements = [i.requirement for i in data]
min_col = min(requirements)
col_num = int(max_requirement // min_col)
row_num = len(data)
# 初始化数据结构
graph = [[{'total': 0, 'item': []} for j in range(col_num)] for i in range(row_num)]
# 列
col_context = [min_col+min_col*i for i in range(col_num)]
def get_col_index_item_without_self(row, rest_index, name):
"""从下往上(先出的结果就是最大的系数项),获取一个不包含自己的item"""
item = {'total': 0, 'item': []}
for r in range(row, -1, -1):
if name not in graph[r][rest_index]['item']:
return graph[r][rest_index]
return item
# 开始动态规划
for row in range(row_num):
for col in range(col_num):
name = data[row].name # 当前位置的条件值
requirement = data[row].requirement # 当前位置的条件值
coefficient = data[row].coefficient # 当前位置的系数值
# 如果当前条件小于等于对应列
if requirement <= col_context[col]:
# 假设用当前行内容条件填充,查看是否还有剩余
rest = col_context[col] - requirement
if rest:
# 有剩余的话
rest_index = col_context.index(rest)
# 查看剩余的对应列,当前行开始,行为阶梯,往上走
max_item = get_col_index_item_without_self(row, rest_index, name)
# 这就是当前内容+剩余的最大系数值,简称sum
maybe_max = coefficient + max_item['total']
# 将这个sum和row-1,col比较,高则合并,低则自己
same_col_top_row_item = graph[row and row-1 or 0][col]
if maybe_max >= same_col_top_row_item.get('total'):
graph[row][col] = {
'total': max_item['total'] + coefficient,
'item': max_item['item'] + [name]
}
elif maybe_max < same_col_top_row_item['total']:
graph[row][col] = same_col_top_row_item
else:
# 没有剩余
# 就看当前内容会不会比同列上一行的系数高,高则用,低则自己
top_row_item = graph[row and row-1 or 0][col]
if top_row_item['total'] > coefficient: # 高则用
graph[row][col] = top_row_item
else: # 低则自己
graph[row][col] = {'total': coefficient, 'item': [name]}
else: # 当前条件大于对应列
if row == 0: # 第一行就直接赋空
graph[row][col] = {'total': 0, 'item': []}
# 不是第一行就取等列上一行的数据
else:
graph[row][col] = graph[row-1][col]
return graph
if __name__ == '__main__':
# 旅行行程最大化
check_list = [
item('威斯敏斯特教堂', 0.5, 7),
item('环球剧场', 0.5, 6),
item('英国国家美术馆', 1, 9),
item('大英博物馆', 2, 9),
item('圣保罗大教堂', 0.5, 8),
]
max_requirement = 2
"""
[{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂'], 'total': 7}]
[{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂', '环球剧场'], 'total': 13},
{'item': ['威斯敏斯特教堂', '环球剧场'], 'total': 13},
{'item': ['威斯敏斯特教堂', '环球剧场'], 'total': 13}]
[{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂', '环球剧场'], 'total': 13},
{'item': ['威斯敏斯特教堂', '英国国家美术馆'], 'total': 16},
{'item': ['威斯敏斯特教堂', '环球剧场', '英国国家美术馆'], 'total': 22}]
[{'item': ['威斯敏斯特教堂'], 'total': 7},
{'item': ['威斯敏斯特教堂', '环球剧场'], 'total': 13},
{'item': ['威斯敏斯特教堂', '英国国家美术馆'], 'total': 16},
{'item': ['威斯敏斯特教堂', '环球剧场', '英国国家美术馆'], 'total': 22}]
[{'item': ['圣保罗大教堂'], 'total': 8},
{'item': ['威斯敏斯特教堂', '圣保罗大教堂'], 'total': 15},
{'item': ['威斯敏斯特教堂', '环球剧场', '圣保罗大教堂'], 'total': 21},
{'item': ['威斯敏斯特教堂', '英国国家美术馆', '圣保罗大教堂'], 'total': 24}]
"""
# 背包问题
check_list = [
item('音响', 4, 3000),
item('笔记本电脑', 3, 2000),
item('吉他', 1, 1500),
item('iphone', 1, 2000)
]
max_requirement = 4
"""
[{'item': [], 'total': 0},
{'item': [], 'total': 0},
{'item': [], 'total': 0},
{'item': ['音响'], 'total': 3000}]
[{'item': [], 'total': 0},
{'item': [], 'total': 0},
{'item': ['笔记本电脑'], 'total': 2000},
{'item': ['音响'], 'total': 3000}]
[{'item': ['吉他'], 'total': 1500},
{'item': ['吉他'], 'total': 1500},
{'item': ['笔记本电脑'], 'total': 2000},
{'item': ['笔记本电脑', '吉他'], 'total': 3500}]
[{'item': ['iphone'], 'total': 2000},
{'item': ['吉他', 'iphone'], 'total': 3500},
{'item': ['吉他', 'iphone'], 'total': 3500},
{'item': ['笔记本电脑', 'iphone'], 'total': 4000}]
"""
# 野营问题
check_list = [
item('水', 3, 10),
item('书', 1, 3),
item('食物', 2, 9),
item('夹克', 2, 5),
item('相机', 1, 6),
]
max_requirement = 6
"""
[{'item': [], 'total': 0},
{'item': [], 'total': 0},
{'item': ['水'], 'total': 10},
{'item': ['水'], 'total': 10},
{'item': ['水'], 'total': 10},
{'item': ['水'], 'total': 10}]
[{'item': ['书'], 'total': 3},
{'item': ['书'], 'total': 3},
{'item': ['水'], 'total': 10},
{'item': ['水', '书'], 'total': 13},
{'item': ['水', '书'], 'total': 13},
{'item': ['水', '书'], 'total': 13}]
[{'item': ['书'], 'total': 3},
{'item': ['食物'], 'total': 9},
{'item': ['书', '食物'], 'total': 12},
{'item': ['水', '书'], 'total': 13},
{'item': ['水', '食物'], 'total': 19},
{'item': ['水', '书', '食物'], 'total': 22}]
[{'item': ['书'], 'total': 3},
{'item': ['食物'], 'total': 9},
{'item': ['书', '食物'], 'total': 12},
{'item': ['食物', '夹克'], 'total': 14},
{'item': ['水', '食物'], 'total': 19},
{'item': ['水', '书', '食物'], 'total': 22}]
[{'item': ['相机'], 'total': 6},
{'item': ['书', '相机'], 'total': 9},
{'item': ['食物', '相机'], 'total': 15},
{'item': ['书', '食物', '相机'], 'total': 18},
{'item': ['食物', '夹克', '相机'], 'total': 20},
{'item': ['水', '食物', '相机'], 'total': 25}]
"""
for i in main(check_list, max_requirement):
pprint(i)
print()