pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas。
1 pandas数据结构
1.1 Series
注:由于pandas与numpy关系密切,所以在代码中经常将二者一同导入使用。

上图中,先利用numpy创建一个一维数组,再利用pandas的内置方法将其转换为pandas的序列类型Series。可以看到,pandas会自动将原有数据转换成一列,并添加行的索引。
1.2 DataFrame
pandas的第二种也是最具代表性的数据结构就是DataFrame。
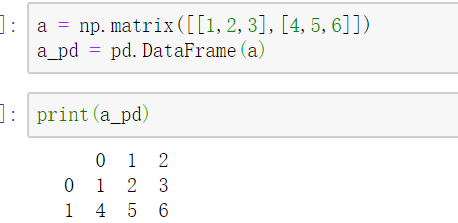
显然,DataFrame就是矩阵类型的数据,只不过pandas中会给矩阵添加行列索引,以便使用与查找元素。
2 创建DataFrame
由于Series可以视为DataFrame的一种简单情况,所以后面将主要介绍DataFrame,关于Series的情况可以类比过去。
从前一小节可以看到,pandas的数据可以通过运用内置方法转换numpy创建的数据得到,但也可以直接在pandas库内创建DataFrame。
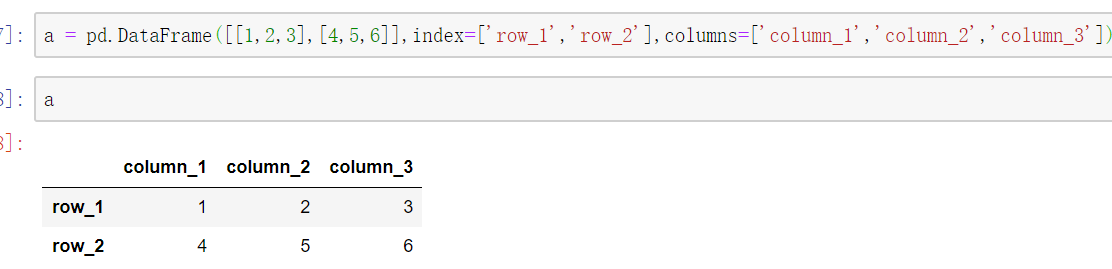
创建DataFrame时,可以手动给数据添加行列名,否则pandas会自动添加形如“0,1,2,3”的行列名。
由于pandas基于numpy制作,所以numpy中的一些常用方法可以直接移植过来。
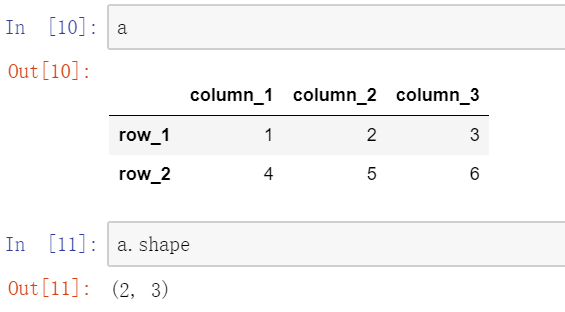
pandas中也有shape方法查看矩阵大小。
3 查找DataFrame的元素
因为pandas中的矩阵允许自定义行列名,所以定位其中的元素分为如下几种方式:使用行列名称,使用行列位置,名称位置混合。
3.1 行列名称定位
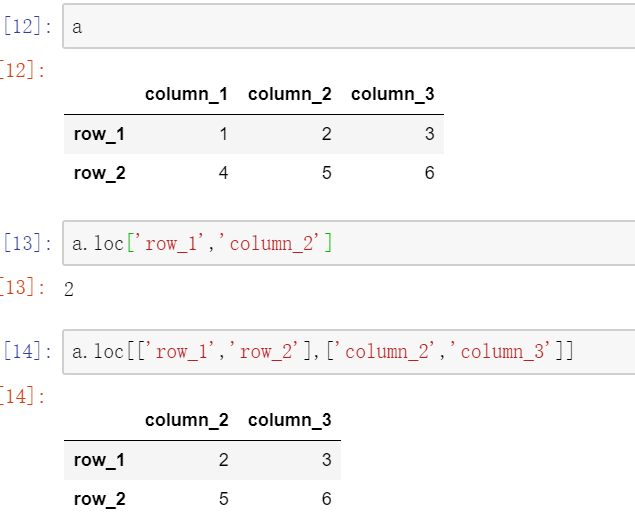
3.2 行列位置定位
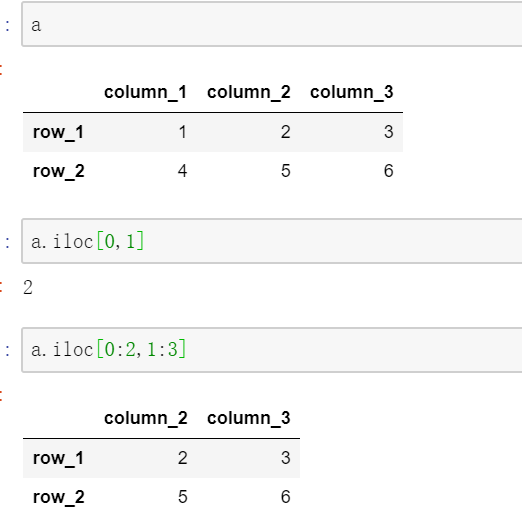
3.3 名称位置混合定位
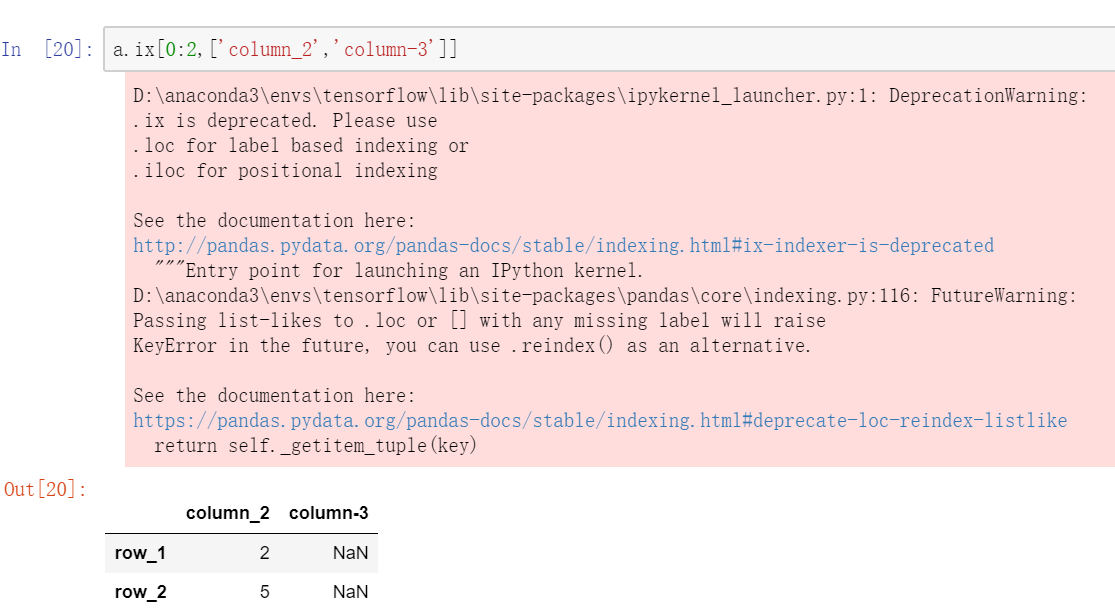
一般常用的还是前两种定位手段,混合定位了解即可。
小结:作为pandas系列的开篇,本文就介绍到此,沿用numpy系列的模式,后面的博文将介绍pandas中关于DataFrame的常用方法。