这里的SVF并不是生物学或医学的(Stromal Vascular Fraction),而是指GIS中的(Sky View Factor,SVF),即为(城市)天空开阔度。
城市天空开阔度(Sky View Factor,SVF)是重要的城市形态学参数,那今天博主就跟大家讲一下如何用ArcMap来计算天空开阔度。
1、加载数据
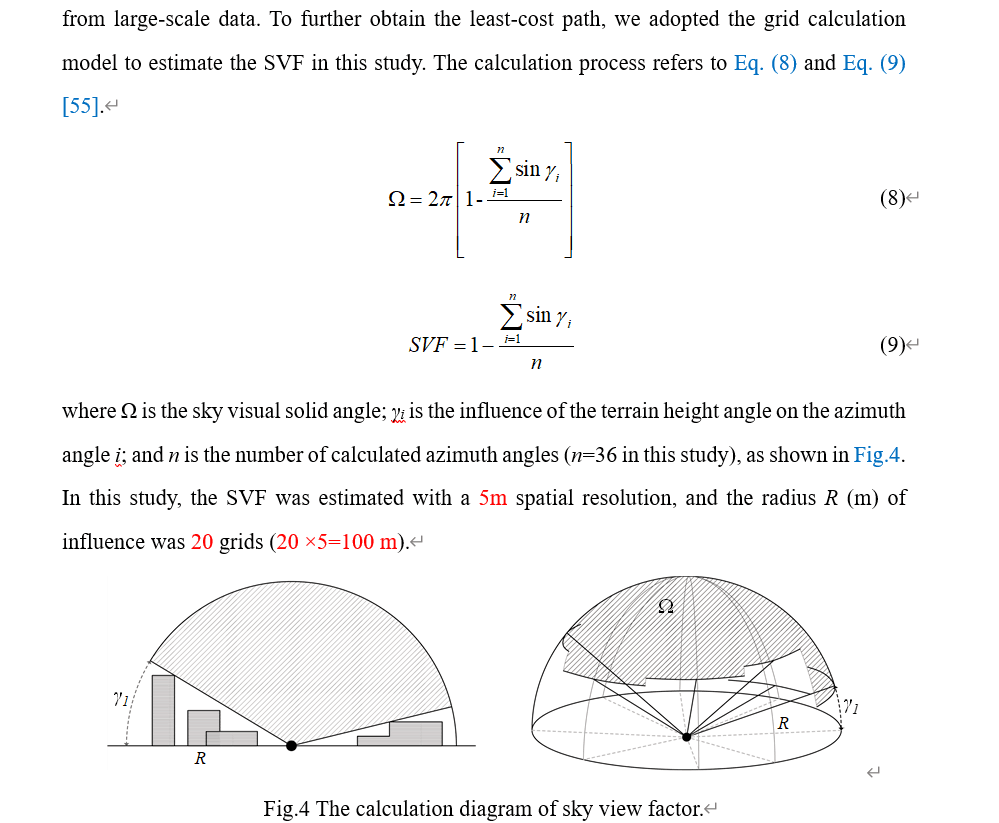
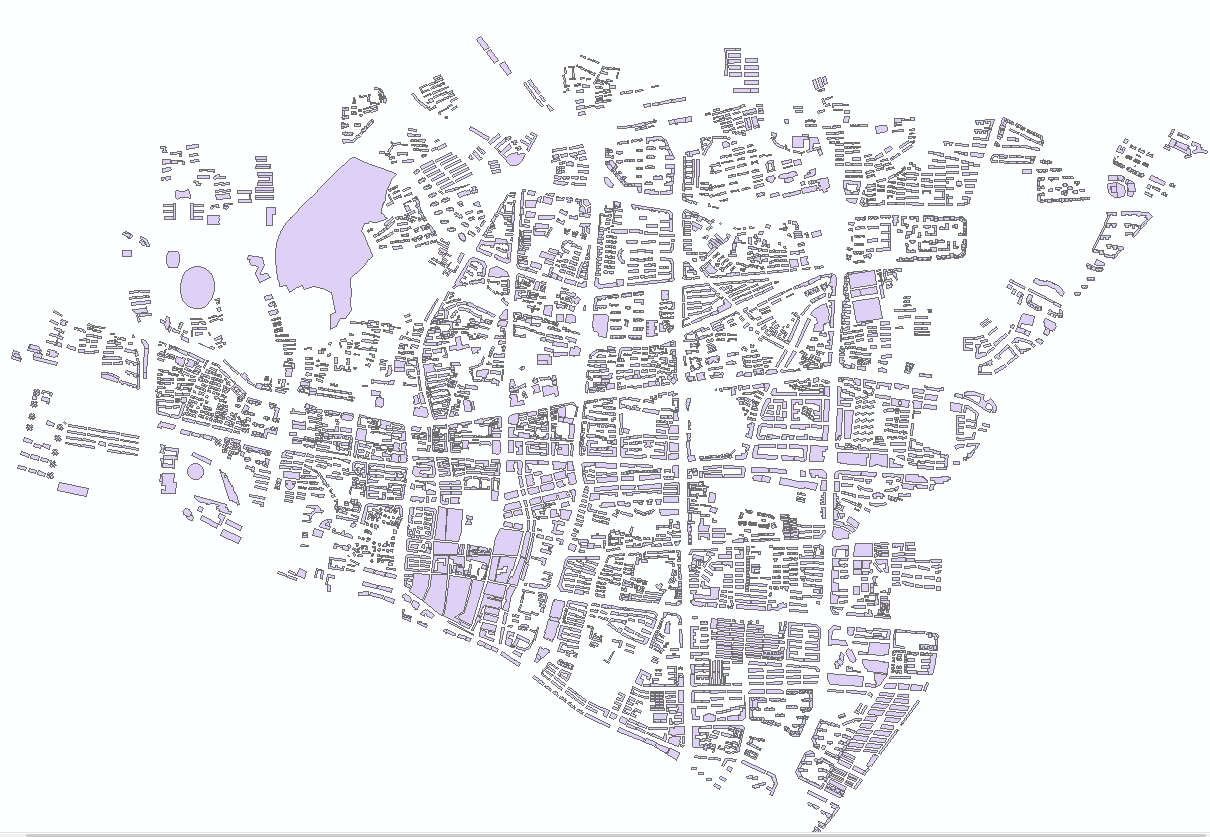
需要加载的数据包括buildings(带有高度信息的建筑数据),area(范围数据),用ArcMap进行添加。如图:
buildings数据显示
area数据显示
2、裁剪
(1)将buildings及area进行备份,存为buildings2、area2,打开编辑器,【开始编辑】,选中所有建筑,【合并】。
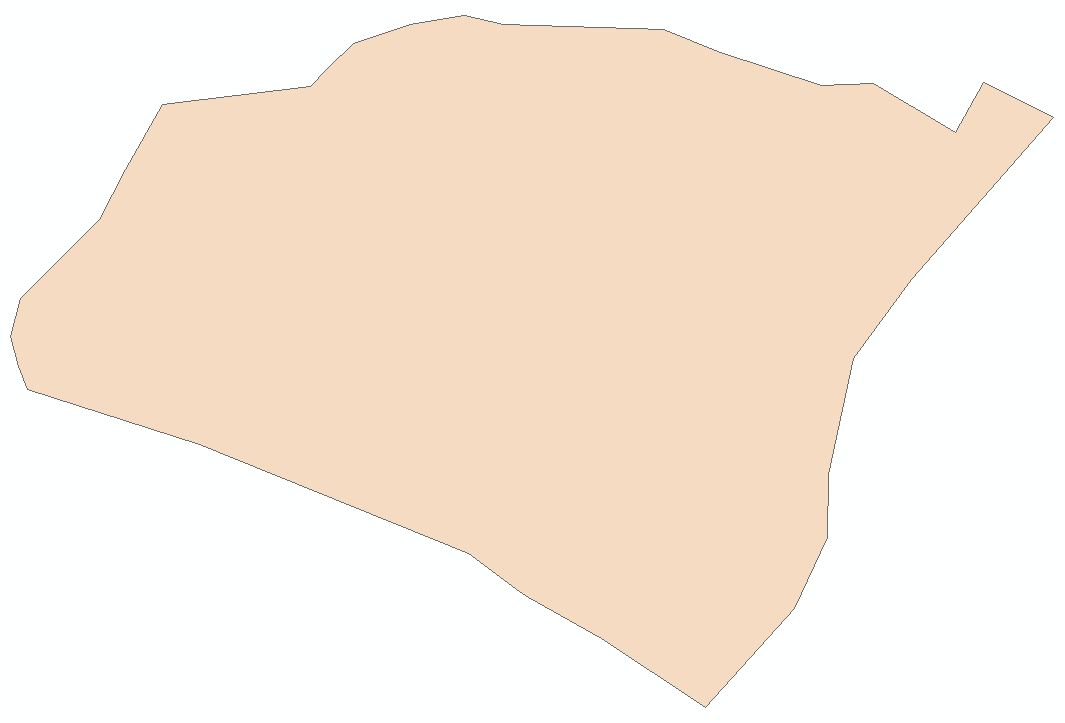
(2)用 【编辑器】中的【裁剪】工具进行裁剪。
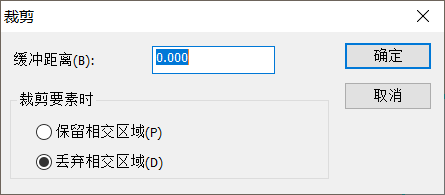
裁剪参数设置
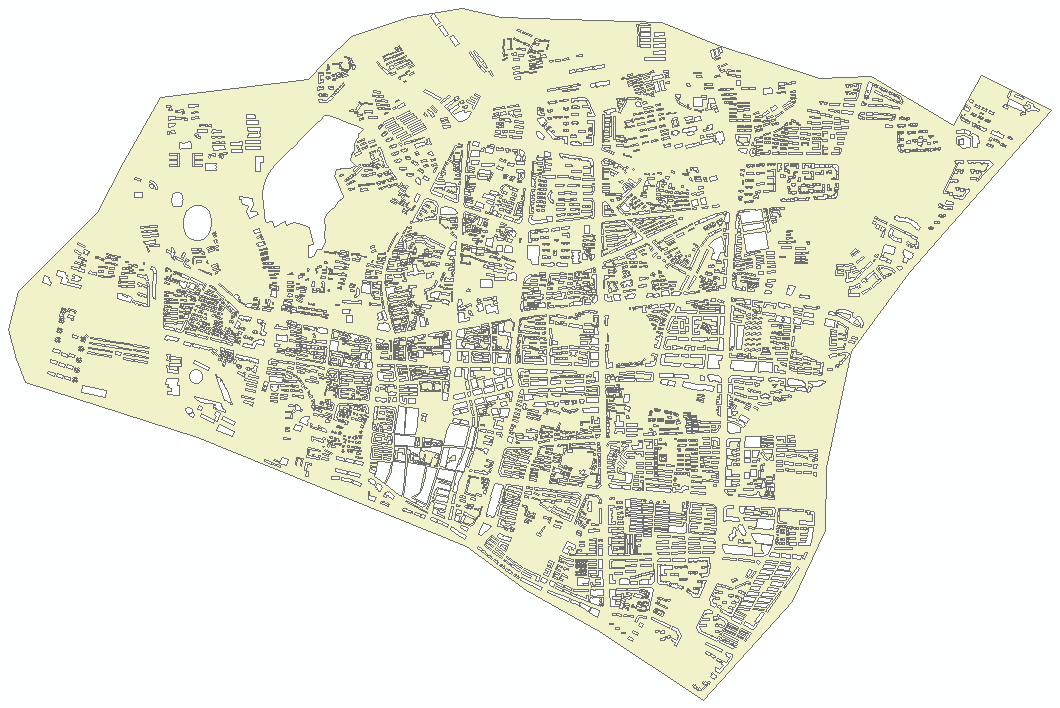
裁剪结果图
3、合并
设置环境,用ArcToolbox中的【合并】工具,对裁剪后的图层与建筑图层(buildings)进行合并。
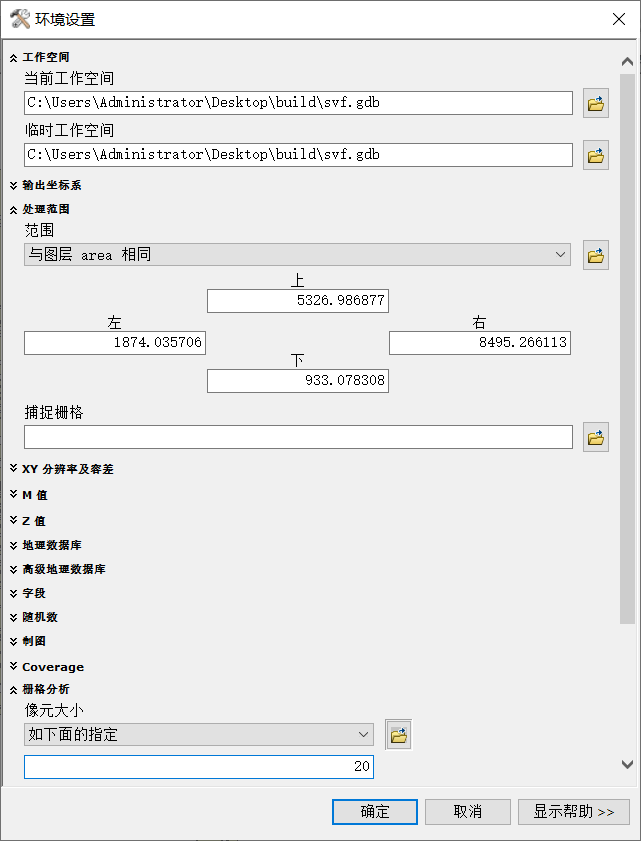
环境设置参数
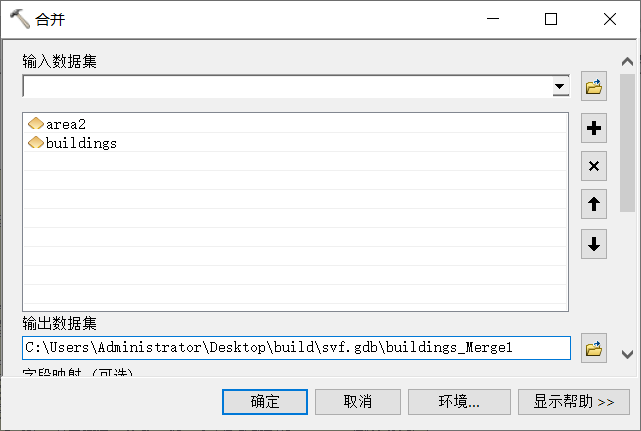
合并参数设置
4、面转栅格
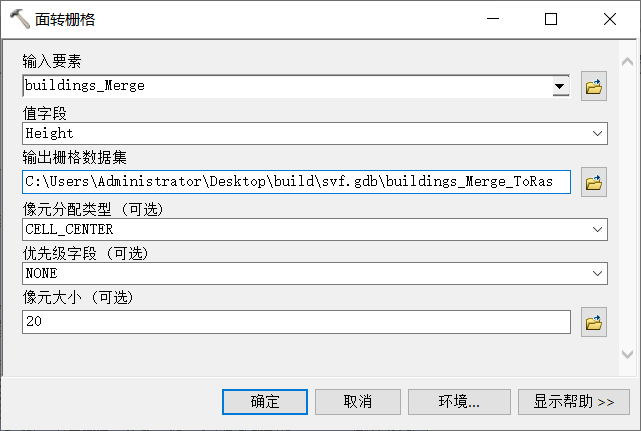
面转栅格参数设置
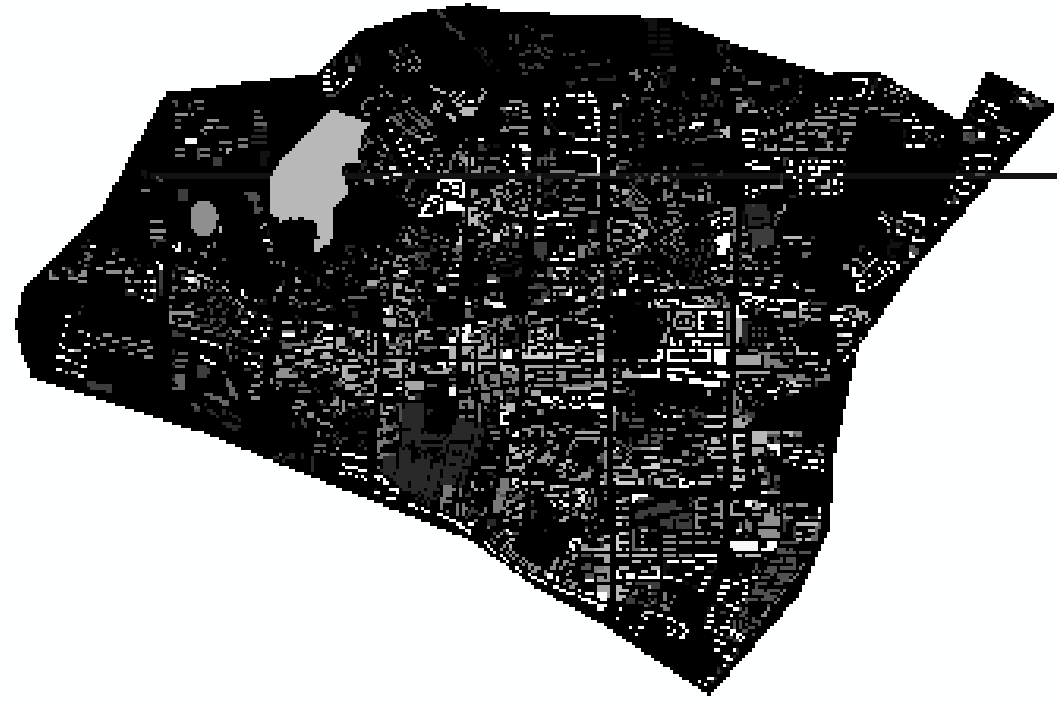
面转栅格结果图
5、栅格转点
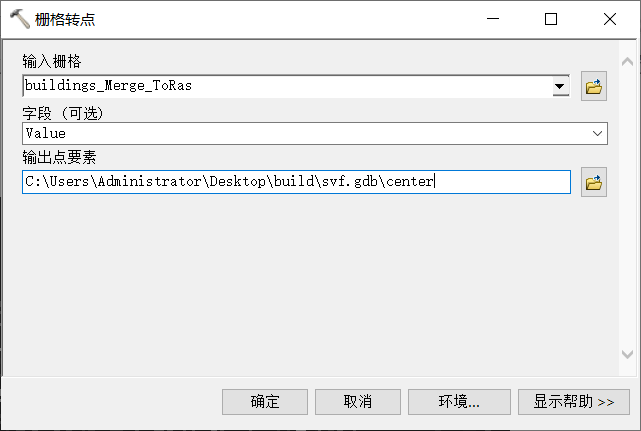
栅格转点参数设置
栅格转点,并对多余部分进行删除。

栅格转点结果图
6、建立缓冲区(推荐使用方法二)
方法一:
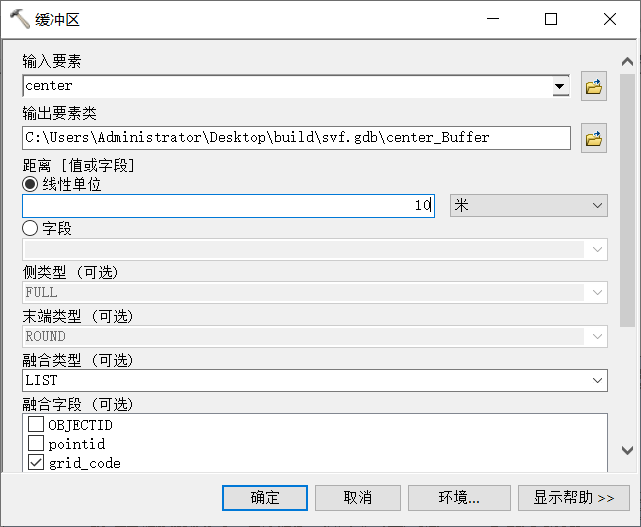
缓冲区参数设置

缓冲区结果局部图
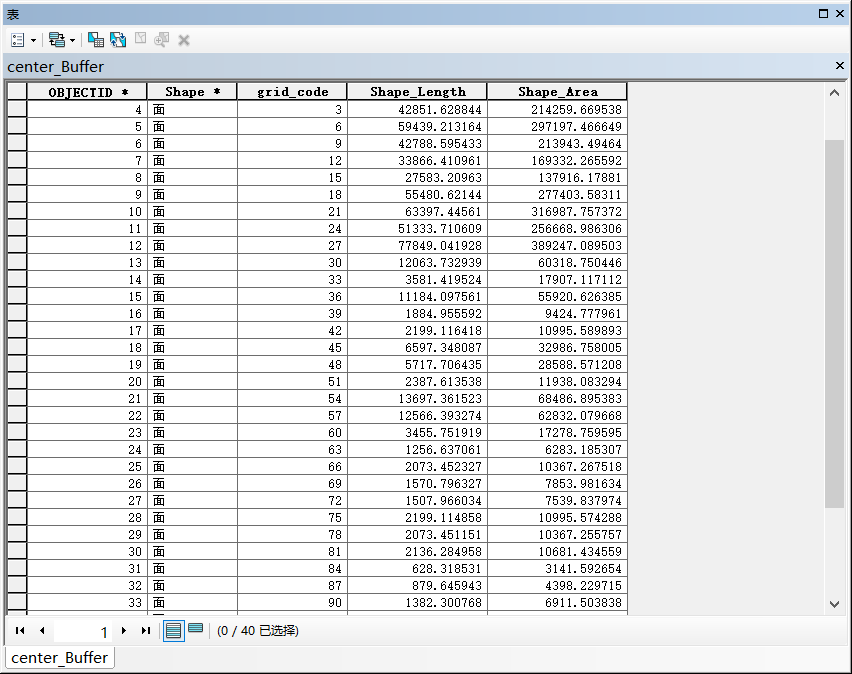
属性表
此时我们可以看到属性表中只有40个要素,原因是grid_code(即为中心点高程数据)相同的为同一要素,需要将多部件转为单部件
(1)【编辑器】【开始编辑】选中所有要素(center_buffer中)。
(2)【高级编辑】【拆分多部件要素】。
(3)【添加字段】,“CID”,作为圆的唯一标识
方法二:
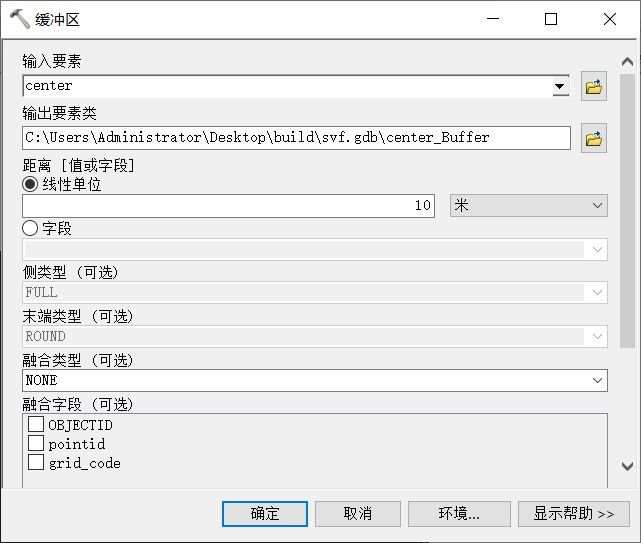
缓冲区分析参数设置
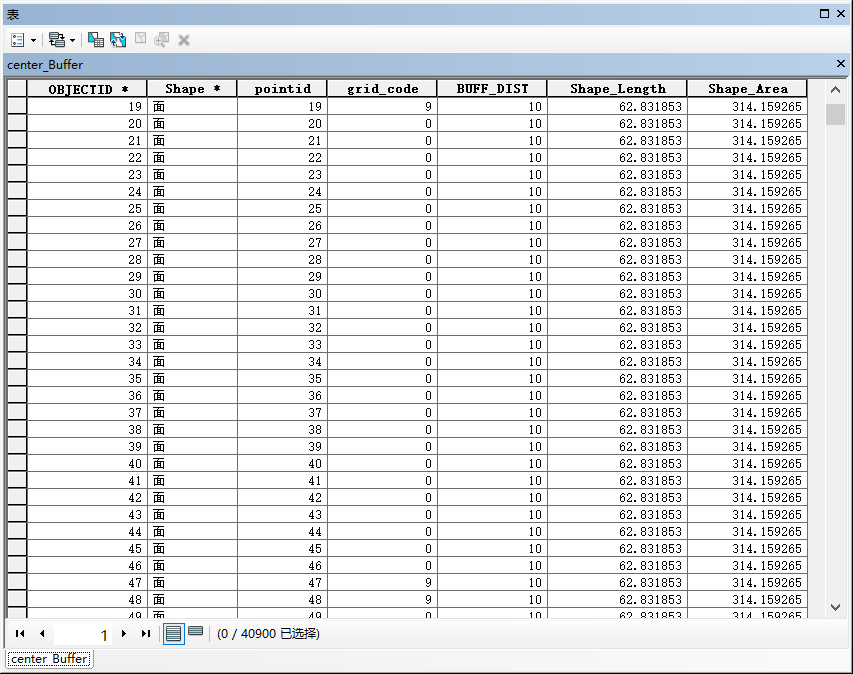
属性表
此时pointid作为标识字段,grid_code仍为2中心点高程
让让你们康康全图吧,但愿没有密集综合征
7、相交
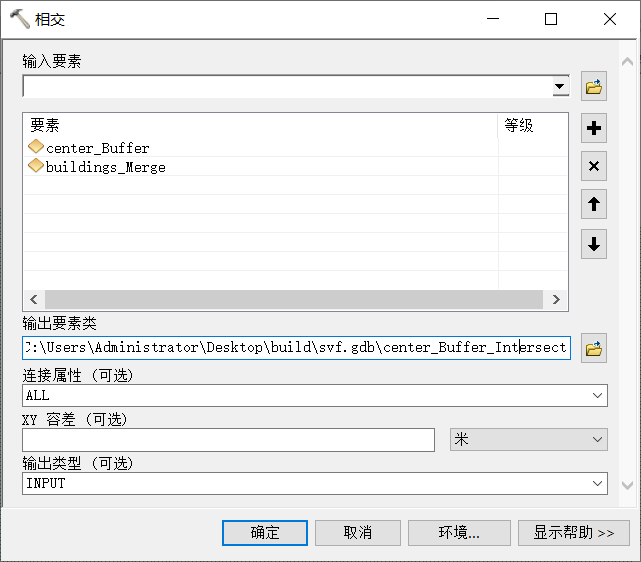
相交参数设置

相交结果(部分)
8、计算SVF
接下来的操作均为表格操作,要熟练使用栅格计算器,若忘记SVF公式,可看文章开头。
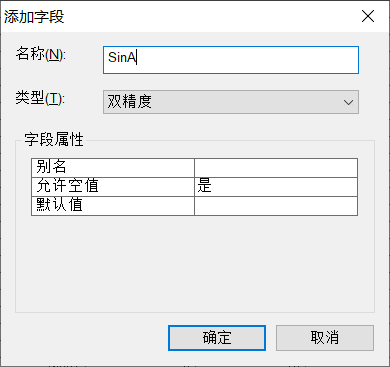
(1)【添加字段】,“SinA”
高差h=([Height]- [grid_code]),
半径r=10m
(2)【字段计算器】,输入公式:“ ([Height]- [grid_code]) / Sqr ( ([Height]- [grid_code]) *([Height]- [grid_code]) +100 )”
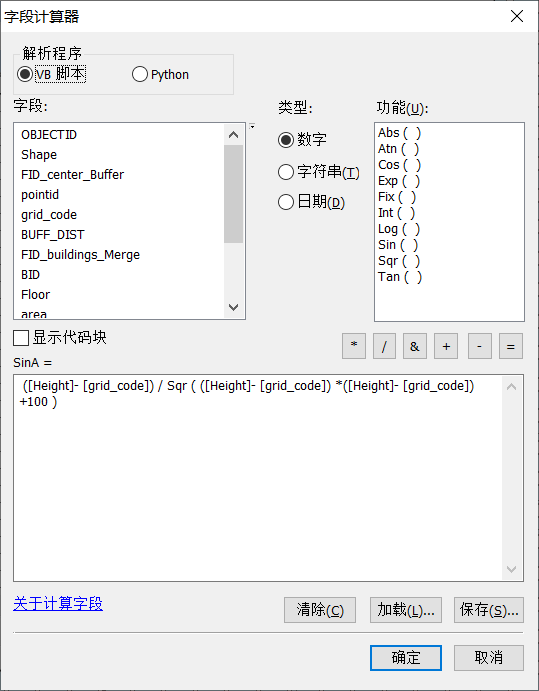
字段计算器参数设置
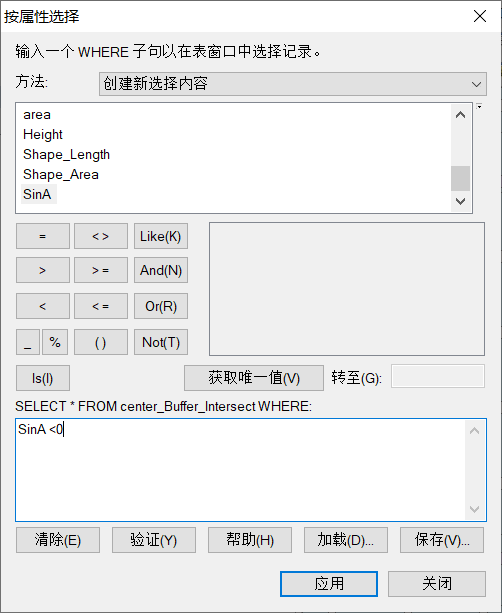
(3)筛选SinA值为负数,归零
一些小伙伴也能要问了,为何会出现负值?原因是相交就很难避免一些高的建筑与低的建筑在同一个圆中,而他的圆心又恰好在高的建筑上,自然就出现的SinA值为负的情况,而SVF为天空开阔度,要计算的自然是高于中心点的角,SinA应为非负,为减小影响,要进行归零处理。(还有一种方法是直接删除,而且此方法更合理,但本例中会出现些许问题)
(当然,如果你只计算地面的天空开阔度就不会有这种烦恼了)
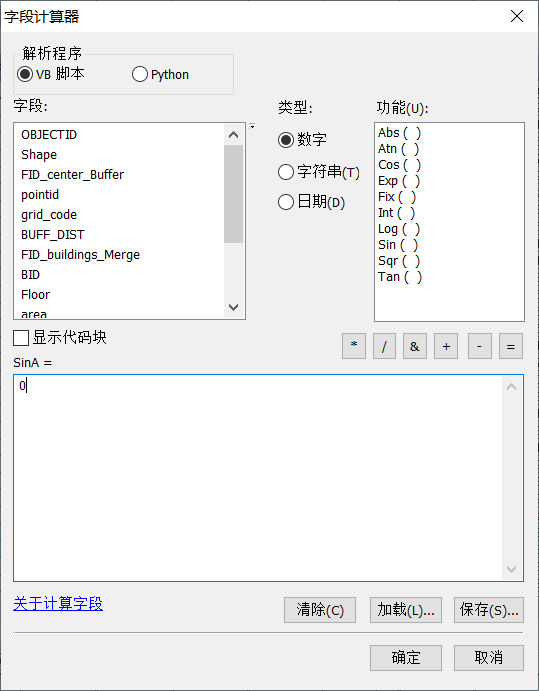
(4)清除所选要素
(5)汇总
计算sinA平均值

(6)计算SVF
center图层,【添加字段】
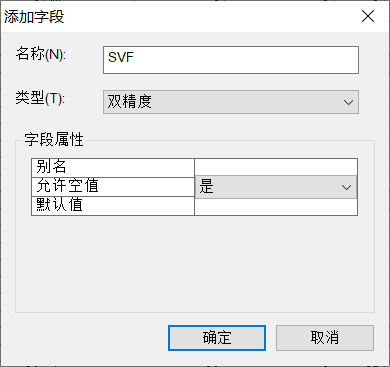
右键,【连接】,【连接数据】
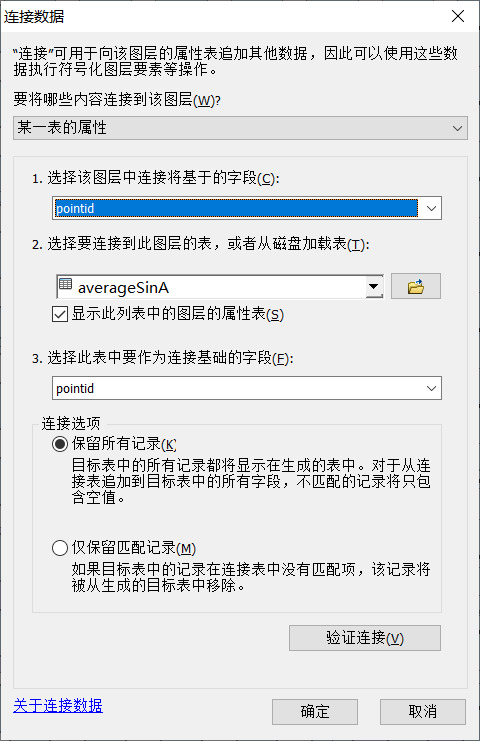
连接数据参数设置
【字段计算器】,输入公式“1- [averageSinA.Ave_SinA]”,移除所有连接。
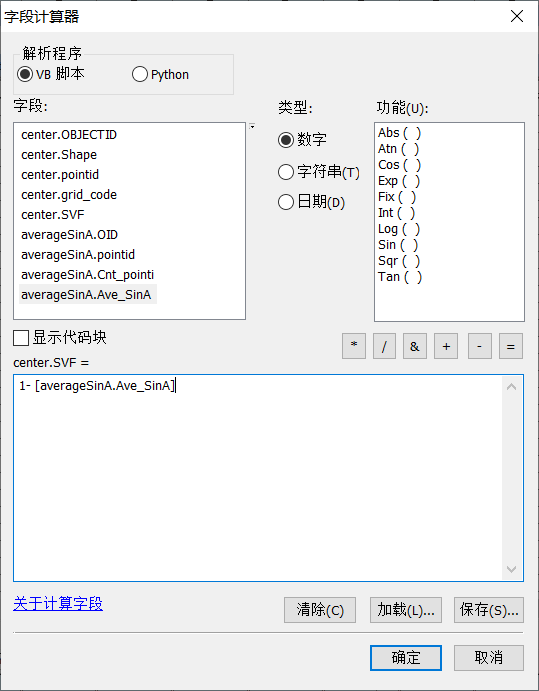
字段计算器参数设置
9、点转栅格
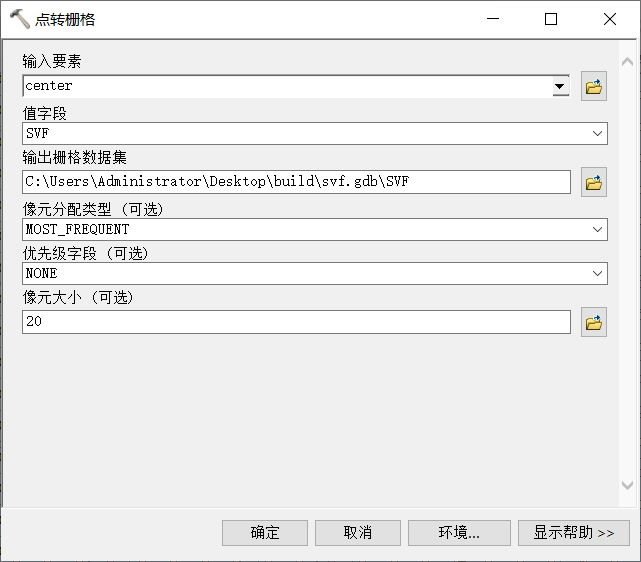
点转栅格参数设置
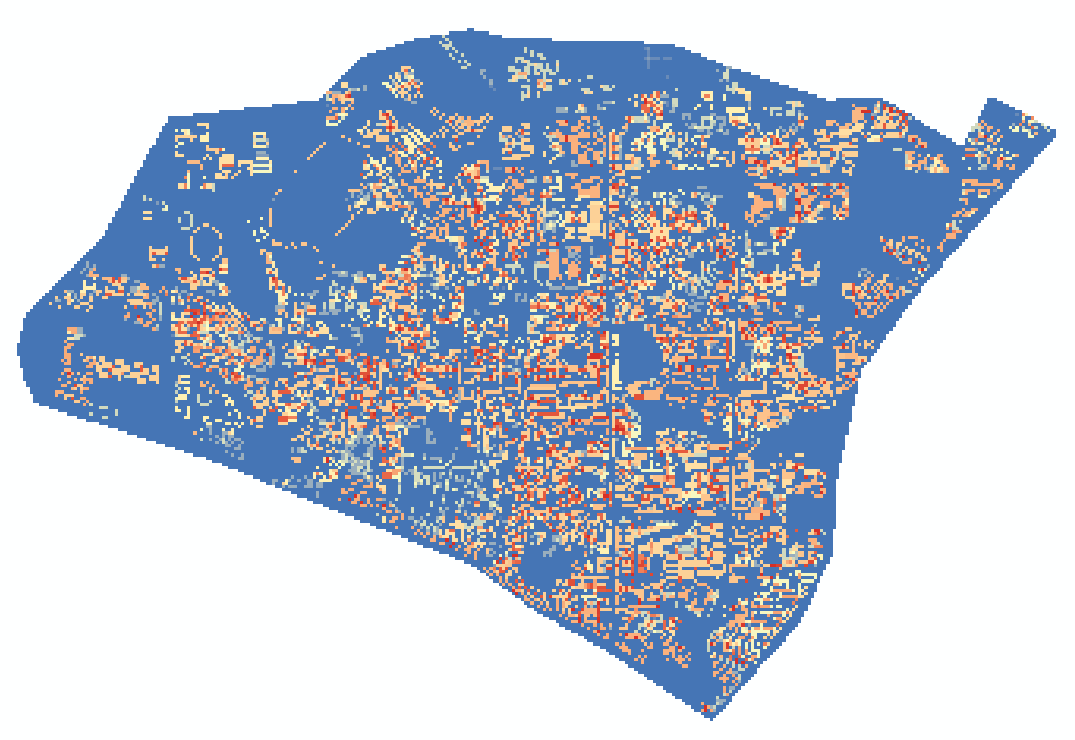

天空开阔度(SVF)结果图
颜色越红,表示天空开阔度越差;颜色越蓝表示天空开阔度越好。
附页:
如果针对地面通风等进行研究,可将5m高度以上建筑,svf设为1,作为成本栅格
具体操作如下:
(1)按属性选择
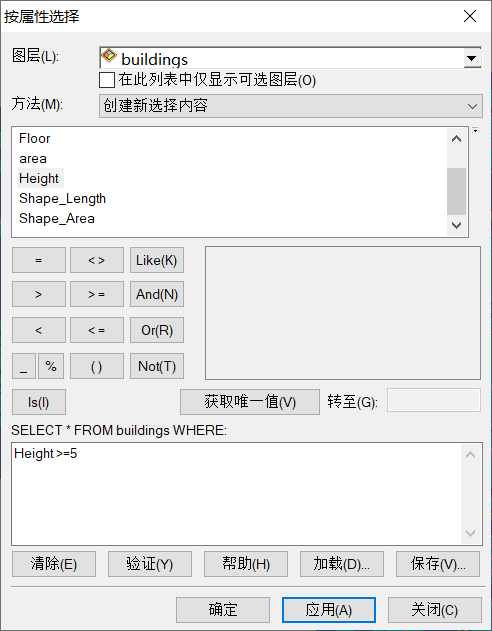
按属性选择参数设置
(2)按位置选择
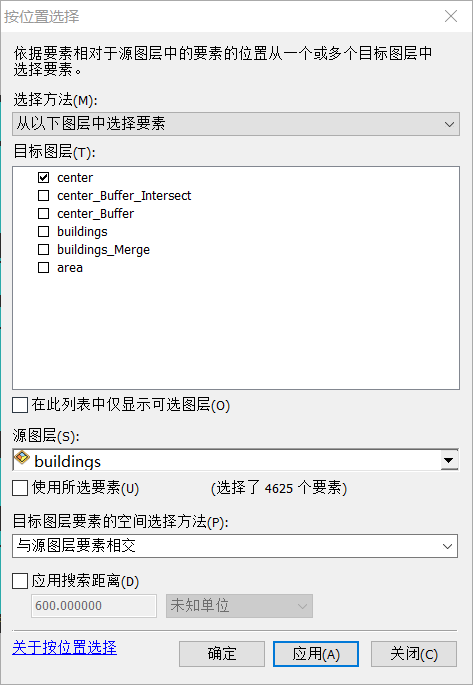
按位置选择参数设置
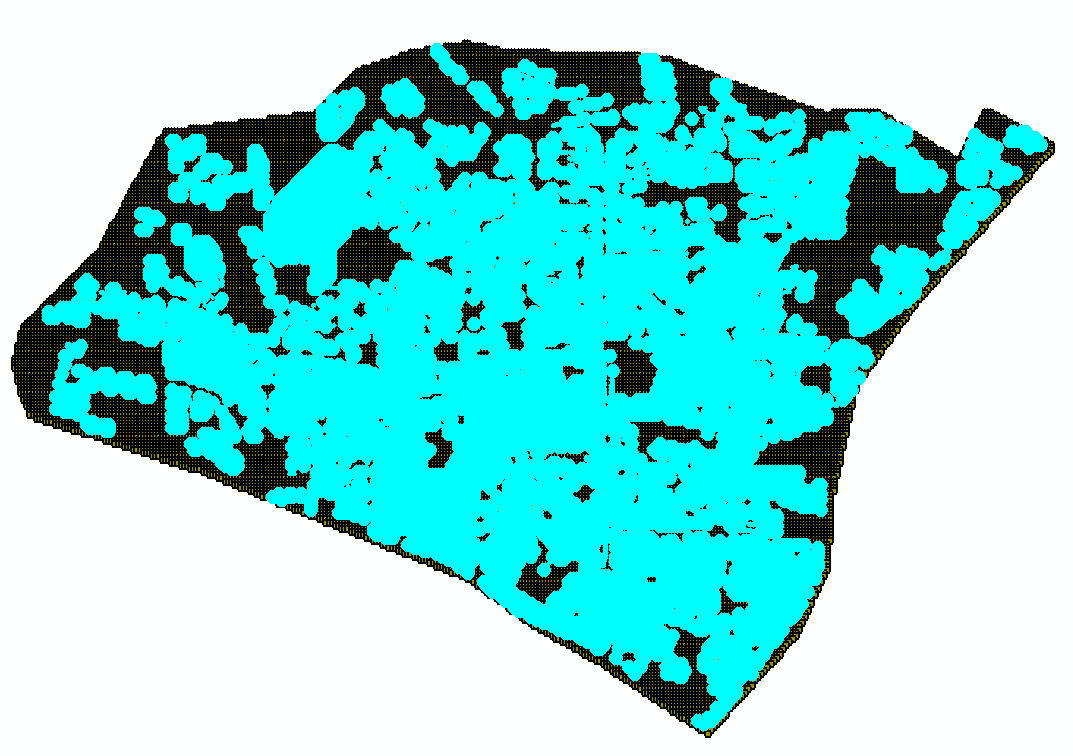
按位置选择结果图
(3)切换选择
【打开属性表】【切换选择】
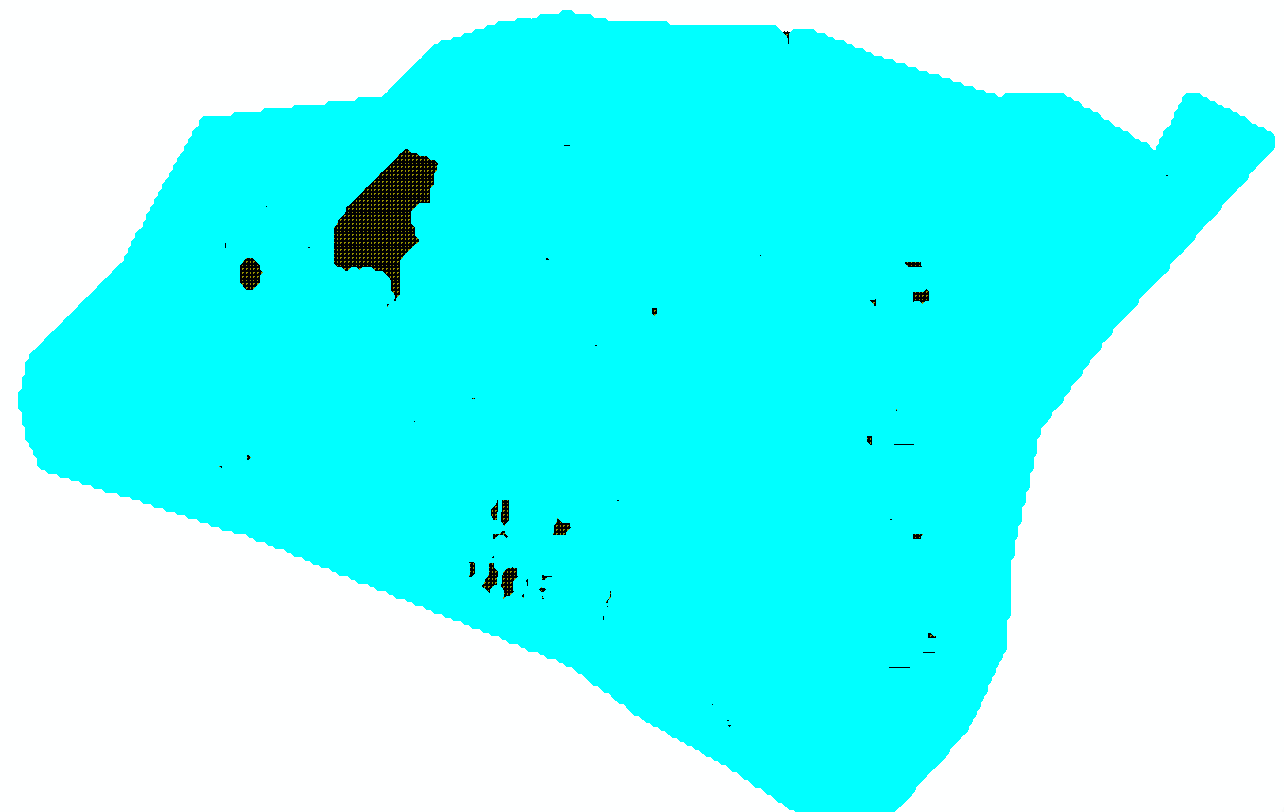
切换选择结果图
(4)点转栅格
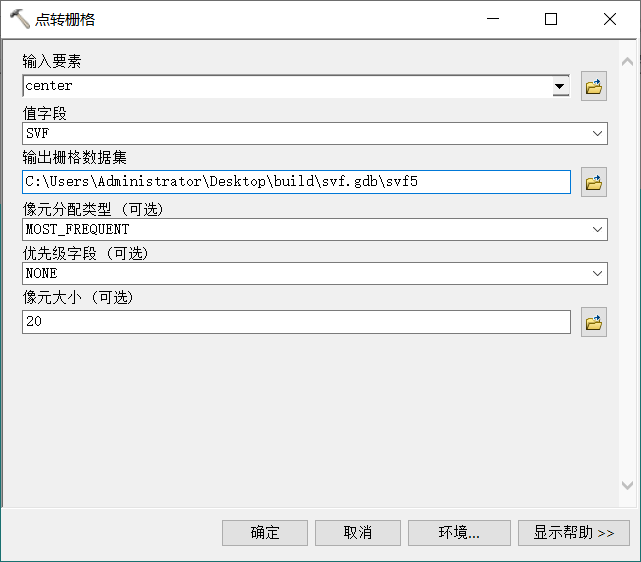
点转栅格参数设置


SVF结果图
知识点补充:
SVM
今日份歌曲推荐:
龙卷风—周杰伦