书接上回,继续分享。
通用报文解析服务,用C#开发,经历了三版更新,支撑起了关区内的绝大多数数据交换业务,截止至今,每日收发报文约20万,数据量约5G,平均延迟在1分钟内。
回想起那些半夜处理积压报文的场景,不胜唏嘘,决定把这个演进过程向大家讲述一下。回顾历史,展望未来,如果能给大家一些启发,是再好不过的了。
(第三版)
三、通用报文解析服务V3.0——分布式,消息队列
上一篇说到了一个问题,引用的程序集由不同的团队负责维护,都引用一套公共组件库,在更新和发布时互相掣肘,导致无法保证有效的更新。其实这就是用的问题。
导致这个问题的根源是程序的架构:
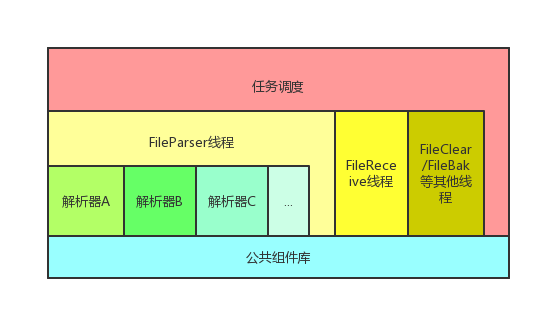
其中公共组件库由专门的小组开发维护,不定期发布新版本。
- 最初的时候,所有的解析器项目源代码都在同一个VisualStudio解决方案中,更新公共组件库代价很低,只需要编译一下,管理方面也不需要逐个测试。就可以更新了。
- 后来有了其他项目的解析器不断加入,他们从开始开发时,就会获取最新的公共组件库版本,从而导致部署时,我需要更新到相应的版本。项目少的时候还好吧,喊一下大家,都更新一下。
- 终于有一天,问题来了。公共组件库中有个方法名称有拼写错误,某次更新给修复了,由于我的大意直接更新到了生产环境,导致很多解析器不工作了,纷纷抱怨“找不到xxx方法”。没办法只能回滚程序,喊大家逐个更新公共组件库,再重新编译。
- 以上还只是前奏,又有一次更新后,有个解析器报错“找不到xxx方法”,但一看代码这个方法还在啊……额只是多了一个可选参数。这里插一句,调用方的c#源码虽然没有变,但是编译后的IL中间代码确改变了,可选参数就是一个语法糖。然后又有人获取的公共组件库版本不对,导致反复更新了好几次才最终消除这个错误。
简而言之,依赖管理从来不是一个简单的问题,我决心彻底改变这个问题。
在一些比较成熟的技术团队中,严格的管理流程能一定程度上预防这个问题,比如组件库更新时,强制每个引用者都更新版本并更新至生产环境;或者组件库更新时,必须检查能否让调用方成功编译,即向后兼容。这些方案都有其代价,而且在我们这种作坊式的小团队中,很难实施。能变的,就只有程序架构本身了。
要解耦,就要把各个解析器的运行时完全分离,即改造为集中-分布式架构。集中点和分布点之间的消息传递,我考虑过两种方案,第一,通过数据库,这其实就是上一篇中已经实现了的所谓分布式架构;第二,主服务提供一个WCF,让其他服务调取,获得待解析的报文;第三,通过MQ等类似中间件传递。
第一种会显著增大数据库压力,尤其是分布点数量多时,放弃。第二种相当于是自己造了一个MQ,还不如直接用现成的,干嘛非要重复发明轮子。在孙老的推荐下,我选择了简单好用轻量级的RabbitMQ。
于是整个架构变成了这样:

我们用了RabbitMQ的Direct方式建立Exchange,文件扩展名作为Route Key传递,就实现了特定的文件扩展名报文发送至特定的Queue。
我又多了一项工作,维护RabbitMQ(苦笑),但是好处也是明显的。首先,每个项目各自的解析服务独立运行,分头维护,我的运维压力减轻。其次,各自更新互不干扰,唯一耦合的就是RabbitMQ和MessageDB,非常稳定基本不变。
当然,为了不至于大家的Windows服务做的五花八门,我也提供了一套Demo和文档。先期尝试的三个项目,改造只用了一个星期就完成了。
再后来,接触了Docker容器,发现这也是一个极好的工具,而且官方提供了RabbitMQ的镜像。用了Docker的好处是,系统的备份和故障后的恢复变得非常简单快捷,一行命令搞定,而且可靠。
现在唯一遇到的问题就是,RabbitMQ配置好Exchange、Queue等参数后,导出的镜像不含有这些配置信息,完全是初始状态,很让人费解,只好做了一套HttpAPI的命令行备用。如果有知道的朋友,欢迎留言赐教,不胜感激。
好了,到这里基本就介绍完了。以后我打算分享一下我开发实用小工具的经验。具体就是实时监控状态,减轻运维压力,更能第一时间发现问题,灭问题于萌芽,解危机于无声。
感谢各位百忙之中的阅读。