hive的数据模型包括:database、table、partition和bucket。
Hive 的架构设计与运行流程,及其各模块的主要作用,请画出架构图
Hive 支持的文件格式和压缩格式,及其各自的特点
Hive 内外表的区分方法,及内外表的差异点
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
Hive 视图如何创建,视图有什么特点,及其应用场景
视图逻辑存在,只存在于元数据库中,只读,View内可能包含ORDER BY/LIMIT语句,Hive支持迭代视图。
hive> drop view if exists v_custname;
OK
Time taken: 40.215 seconds
hive> create view v_custname as select age,custname from customers where sex=1 order by age;
OK
age custname
Time taken: 1.158 seconds
scala> import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.hive.HiveContext
scala> val hcon=new HiveContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
hcon: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@37c5be11
scala> hcon.sql("select * from gamedw.v_custname")
res138: org.apache.spark.sql.DataFrame = [age: int, custname: string]
scala> hcon.sql("select * from gamedw.v_custname").show
+---+---------------+
|age| custname|
+---+---------------+
| 5| nihao|
| 5| nihao|
| 5| nihao|
| 5| nihao|
| 20| zhangsan|
| 20| zhangsan|
| 20| zhangsan|
| 20| zhangsan|
| 20| zhangsan|
| 20| zhangsan|
| 20| zhangsan|
| 32| liuyang|
| 32| liuyang|
| 32| liuyang|
| 32| liuyang|
| 32| liuyang|
| 32| liuyang|
| 32| liuyang|
| 50|tianyt_touch100|
| 50|tianyt_touch100|
+---+---------------+
only showing top 20 rows
Hive 常用的 12 个命令,及其作用
hive> create database if not exists GameDW;
OK Time taken: 0.013 seconds
或者
hive> create schema if not exists GameDW;
OK Time taken: 0.007 seconds
hive> create database if not exists GameDW;
OK Time taken: 0.013 seconds
或者
hive> create schema if not exists GameDW;
OK Time taken: 0.007 seconds
查看数据库属性
hive> describe database gamedw;
删除数据库
hive 不允许删除含有表的库,只有先删除表,才能删掉数据库;后面加上CASCADE(级联),就会在删除数据库前,先删除库里面的表
;不用CASCADE,使用restrict和默认删除一样 ,不能删除存在表的数据库;
hive> drop database if exists aaa CASCADE; OK
查看数据库属性
hive> describe database gamedw;
OK gamedw
hdfs://localhost:9000/user/hive/warehouse/gamedw.db root USER Time taken: 0.009 seconds, Fetched: 1 row(s)
hive> describe database extended gamedw;
OK
gamedw hdfs://localhost:9000/user/hive/warehouse/gamedw.db root USER {creator=tianyongtaao} Time taken: 0.011 seconds, Fetched: 1 row(s)
hive> desc extended v_custname;
OK
col_name data_type comment
age int
custname string
Detailed Table Information Table(tableName:v_custname, dbName:gamedw, owner:root, createTime:1535009983, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:age, type:int, comment:null), FieldSchema(name:custname, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:null, parameters:{}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{transient_lastDdlTime=1535009983}, viewOriginalText:select age,custname from customers where sex=1 order by age, viewExpandedText:select `customers`.`age`,`customers`.`custname` from `gamedw`.`customers` where `customers`.`sex`=1 order by age, tableType:VIRTUAL_VIEW)
Time taken: 0.357 seconds, Fetched: 4 row(s)
desc formatted v_cust; 可以获得更加详细信息
select
alter table
alter database
create table
create database
desc tablename
load data local inpath 'path’ into table aa partition(statdate=20170403)
alter table aa change col2 name string;
alter table aa add columns(col3 string);
alter table aa rename to aa_test;
show partitions aa;
alter table aa partition(statdate=20170404) rename to partition(statdate=20170405);alter table bb partition(statdate=20170404) set location '/user/gaofei.lu/aa.txt';alter table aa drop if exists partition(statdate=20170404);set hive.execution.engine=spark
hive> desc database gamedw;
OK
db_name comment location owner_name owner_type parameters
gamedw hdfs://localhost:9000/user/hive/warehouse/gamedw.db root USER
Time taken: 0.15 seconds, Fetched: 1 row(s)
Hive 常用的 10 个系统函数,及其作用
sum max concat avg count round floor ceil abs cast unix_timestamp() date_diff year month hour case when isnull instr length trim
请简述 udf/udaf/udtf 是什么,各自解决的问题,及典型代表应用场景。
UDF(User-Defined-Function),用户自定义函数对数据进行处理。UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容。
UDAF(User- Defined Aggregation Funcation)用户定义聚合函数,可对多行数据产生作用;等同与SQL中常用的SUM(),AVG(),也是聚合函数;
UDTF:User-Defined Table-Generating Functions,用户定义表生成函数,用来解决输入一行输出多行;继承GenericUDTF类,重写initialize(返回输出行信息:列个数,类型), process, close三方法;
udaf 的实现步骤,及其包含的主要方法,及每个方法要解决的问题,并写代码自实现聚合函数 max 函数?
hive 设置参数的方法有哪些?并列举 8 个常用的参数设置?
HIVE 数据倾斜的可能原因有哪些?主要解决方法有哪些?
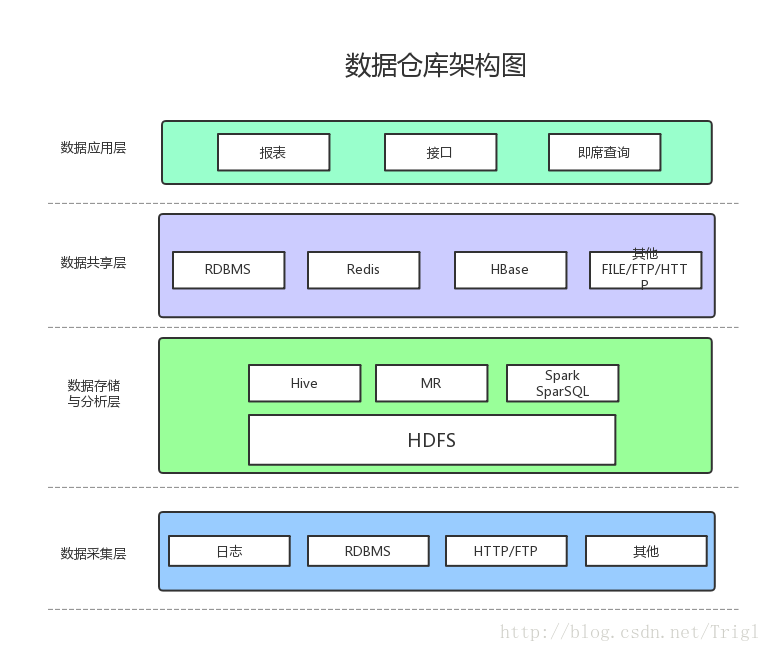
数据仓库之数据架构设计图,及每个模块的主要作用?