1 mycat简介
1.1 各类数据库中间件
中间件种类很多种,如下图:
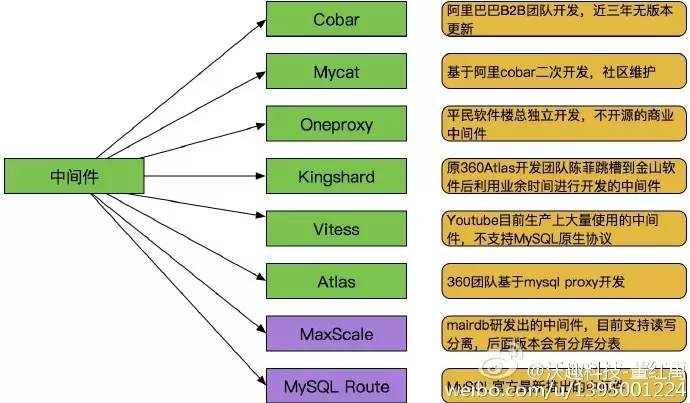
- Cobar: 阿里巴巴B2B开发的关系型分布式系统,管理将近3000个MySQL实例。 在阿里经受住了考验,后面由于作者的走开的原因cobar没有人维护 了,阿里也开发了tddl替代cobar。
- MyCAT: 社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,目前已经有一些公司在使用MyCAT
- OneProxy: 数据库界大牛,前支付宝数据库团队领导楼总开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件,专注在性能和稳定性上。
- Vitess: 这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要使用他提供语言的API接口。
- Kingshard: Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间用go语言开发的,目前在不断完善。
- Atlas: 360团队基于mysql proxy 把lua用C改写。原有版本是支持分表, 目前已经放出了分库分表版本。
- MaxScale与MySQL Route: MaxScale是mariadb 研发的,目前版本不支持分库分表。MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。
1.2 Mycat是什么
MyCat是一个数据库中间件,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
我们的应用只需要一台数据库服务器的时候我们并不需要Mycat,而如果你需要分库甚至分表,这时候应用要面对很多个数据库的时候,这个时候就需要对数据库层做一个抽象,来管理这些数据库,而最上面的应用只需要面对一个数据库层的抽象或者说数据库中间件就好了,这就是Mycat的核心作用。
1.3 Mycat原理
Mycat的原理中最重要的一个动词是"拦截",它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。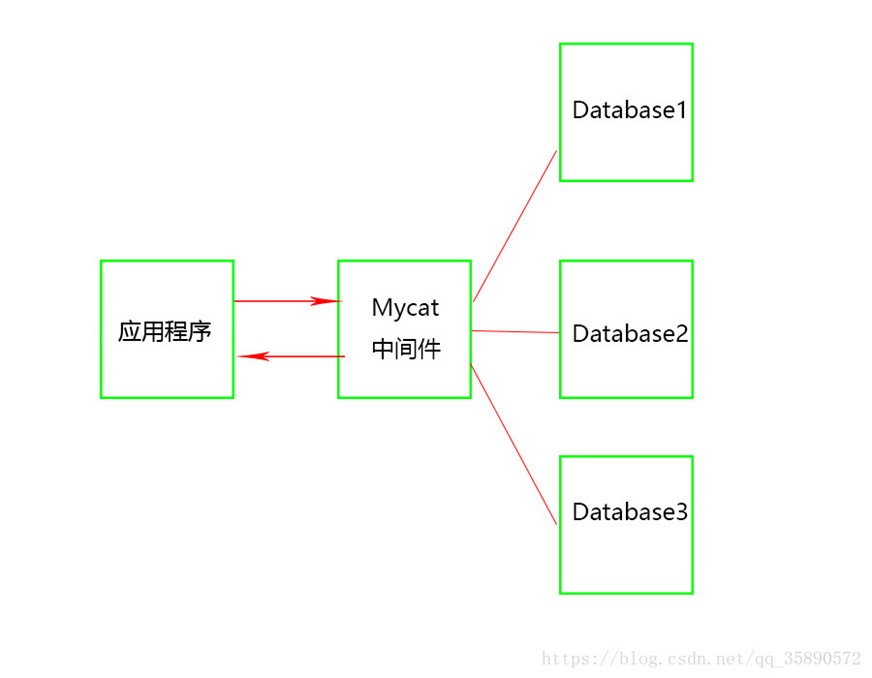
上述图片里,应用程序不再直接访问数据库,而是访问Mycat,由Mycat与数据库交互,数据库数据返回给Mycat,Mycat再返回给应用程序。三个Database才是真正的数据库,又称为三个节点,也称为三个分片。
总结:Mycat作为一个中间件,应用程序直接访问它,不用再去管真实的数据库,而由Mycat来与真实的数据库进行交互,真实的数据库可能有多个,这就是分布式架构,即多节点(多分片)
1.4 相关概念
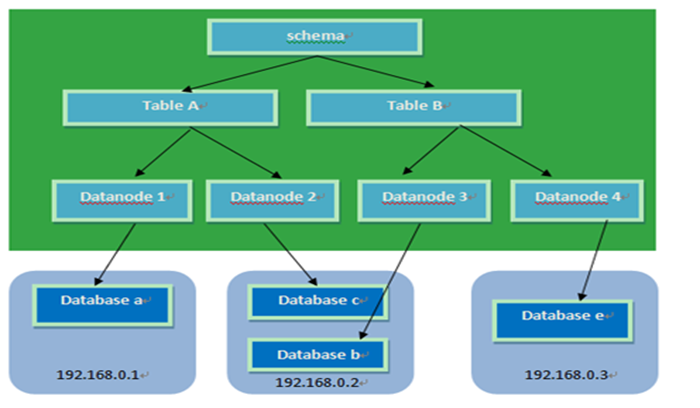
schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的"子表(childTable)",子表的分片依赖于与"父表"的具体分片地址,简单的说,就是属于父表里某一条记录A的子表的所有记录都与A存储在同一个分片上。
分片规则:是一个字段与函数的捆绑定义,根据这个字段的取值来返回所在存储的分片(DataNode)的序号,每个表格可以定义一个分片规则,分片规则可以灵活扩展,默认提供了基于数字的分片规则,字符串的分片规则等。
dataNode: MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置两个DataSource,一主一从,当主节点宕机,系统自动切换到从节点。
dataHost:定义某个物理库的访问地址,用于捆绑到dataNode上。
关系图:
2 mycat安装
简单环境如下:
192.168.100.161 mycat
192.168.100.162 mysql
192.168.100.163 mysql

2.1 首先安装mysql、并创建真实库
- 162和163上安装mysql
#不再叙述
- 分别在两台mysql上创建测试库
192.168.100.162:
drop database if exists TEST_DB;
create database TEST_DB;
use TEST_DB;
create table user(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
insert into user(id,username,password,address,birthday,department_id) values(1200,'张三','123456','四川成都','2018-06-01',2);
insert into user(id,username,password,address,birthday,department_id) values(1201,'李四','982352','成都大学','2015-04-03',3);
192.168.100.163:
drop database if exists TEST_DB;
create database TEST_DB;
use TEST_DB;
create table user(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
insert into user(id,username,password,address,birthday,department_id) values(3,'王五','982352','四川绵阳','1996-08-26',2);
2.2 安装mycat
#mycat依赖java环境
192.168.100.161:
mkdir /usr/java
tar xf jdk-8u151-linux-x64.tar.gz
mv jdk1.8.0_151/ /usr/java/jdk1.8
echo 'export JAVA_HOME=/usr/java/jdk1.8
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH' >>/etc/profile
source /etc/profile
java -version
#mycat解压后即可使用
tar xf Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz -C /usr/local/
2.3 修改配置
MyCAT主要通过三个配置文件来定义逻辑库和相关配置:
schema.xml中定义逻辑库,表、分片节点等内容;
conf/rule.xml中定义分片规则;
server.xml中定义用户以及系统相关变量,如端口等。
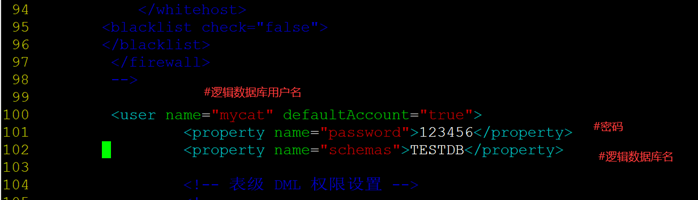
- 修改server.xml文件
- 修改schema.xml文件
cp schema.xml schema.xml.bak
> schema.xml #怕改错,清空复制即可

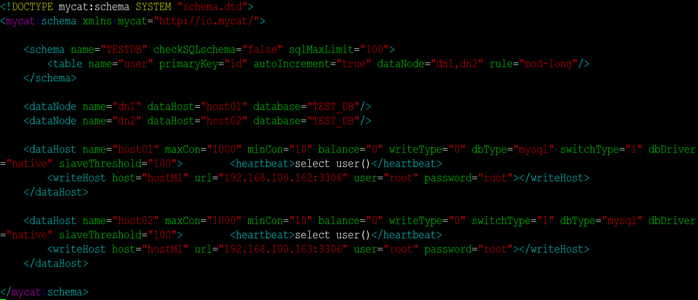
- 最后配置rule.xml
我们在schema.xml中使用了mod-long规则,由于是两个节点来提供服务,这里我就将其设置为均分:比如插入时,一个一库,轮流进行
cp rule.xml rule.xml.bak
vim rule.xml

2.4 启动程序
vim /usr/local/mycat/conf/wrapper.conf
wrapper.java.additional.3=-XX:MaxPermSize=64M #使用java1.8版本,需要把这行注释掉,否则启动失败
wrapper.java.additional.10=-Xmx1G #设置合适的内存
wrapper.java.additional.11=-Xms1G #设置合适的内存
启动:
①控制台启动 :去 mycat/bin 目录下执行 ./mycat console
②后台启动 :去 mycat/bin目录下 ./mycat start
为了能第一时间看到启动日志,方便定位问题,我们先选择①控制台启动,如没报错再选择用②启动
2.5 测试mycat
Mycat的默认端口是:8066,对于应用程序来说,数据库名为Mycat的中间件逻辑数据库名,不再是某个真实的数据库名
mysql -umycat -p123456 -P8066 -h 192.168.100.162
为了方便我这里使用的是Navicat
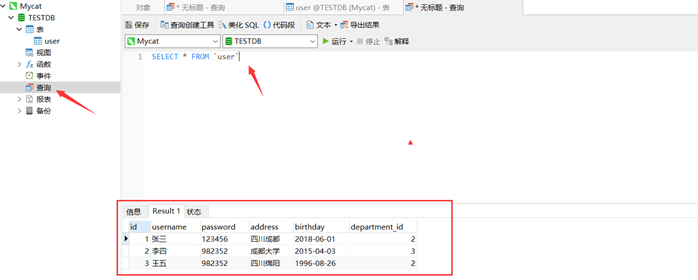
insert into user(id,username,password,address,birthday,department_id) values(4,'美女1','123456','四川成都','2018-06-01',2);
insert into user(id,username,password,address,birthday,department_id) values(5,'美女2','123456','四川成都','2018-06-01',2);

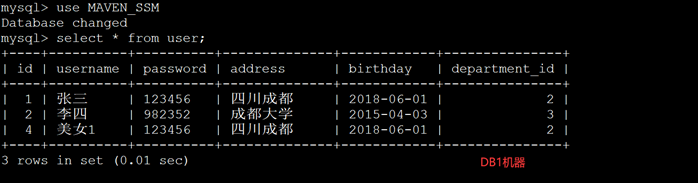
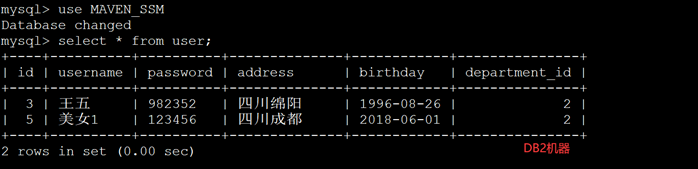
这时候两台mysql数据库,各插了一条,均匀分配。进入Mysql进行验证:
2.6 mycat配置主从同步和读写分离
新架构如下,再增加两台机器164和165作为从机
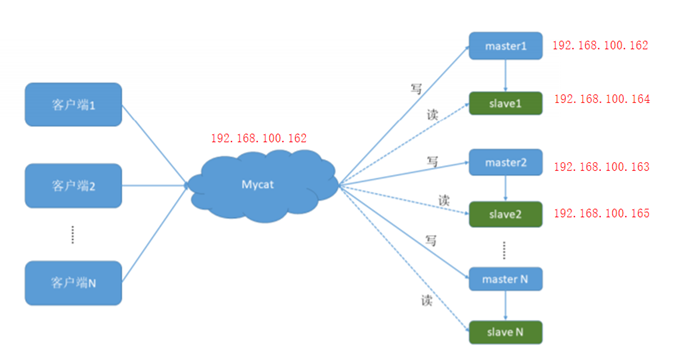
- 164和165安装mysql、配置主从
- mycat配置读写分离
[root@node02 conf]# cat schema.xml
#修改的balance属性,通过此属性配置读写分离的类型,并添加slave主机
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/>
</schema>
<dataNode name="dn1" dataHost="host01" database="TEST_DB"/>
<dataNode name="dn2" dataHost="host02" database="TEST_DB"/>
#balance改为3
<dataHost name="host01" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.100.162:3306" user="root" password="root">
<readHost host="hostS1" url="192.168.100.164:3306" user="root" password="root"/> #新增
</writeHost>
</dataHost>
<dataHost name="host02" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.100.163:3306" user="root" password="root">
<readHost host="hostS1" url="192.168.100.165:3306" user="root" password="root"/> #新增
</writeHost>
</dataHost>
</mycat:schema>
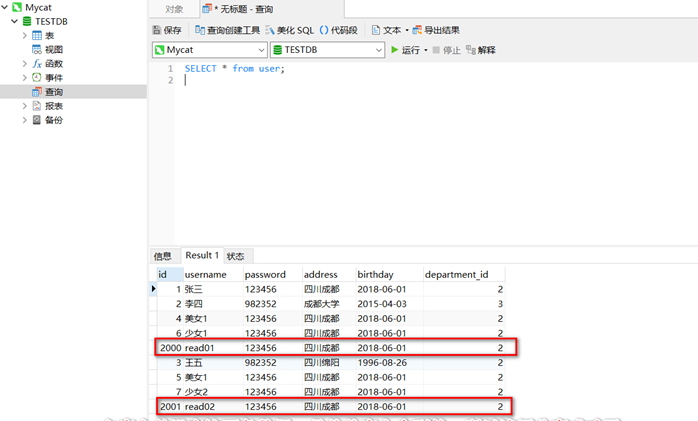
- 配置好读写分离以后,我们可以直接去两台从库上插入数据,插入后主库和从库数据就会不一致,然后通过mycat去读取数据,读到的数据应该和从库是一致的
#登录164
mysql -uroot -proot
use TEST_DB;
insert into user(id,username,password,address,birthday,department_id) values(2000,'read01','123456','四川成
都','2018-06-01',2);
#登录165
mysql -uroot -proot
use TEST_DB;
insert into user(id,username,password,address,birthday,department_id) values(2001,'read02','123456','四川成
都','2018-06-01',2);
#然后去mycat去查
#可以看到,查到的数据就是从库上的数据,读写分离已经生效了
3 mycat配置文件详解
3.1 server.xml
server.xml 几乎保存了所有 mycat 需要的系统配置信息。
system 标签:
该标签内嵌套的所有 property 标签都与系统配置有关。
<system>
<property name="charset">utf8</property>
</system>
charset 属性:
该属性用于字符集设置。
defaultSqlParser 属性:
该属性用来指定默认的解析器。目前的可用的取值有:druidparser 和 fdbparser。使用的时候可以选择其中的一种,目前一般都使用 druidparser。1.3 解析器默认为 fdbparser,1.4 默认为 druidparser,1.4 以后 fdbparser 作废。
processors 属性:
该属性主要用于指定系统可用的线程数,默认值为机器 CPU 核心线程数。主要影响 processorBufferPool、 processorBufferLocalPercent、 processorExecutor 属性。NIOProcessor 的个数也是由这个属性定义的,所以调优的时候可以适当的调高这个属性。
processorBufferChunk 属性:
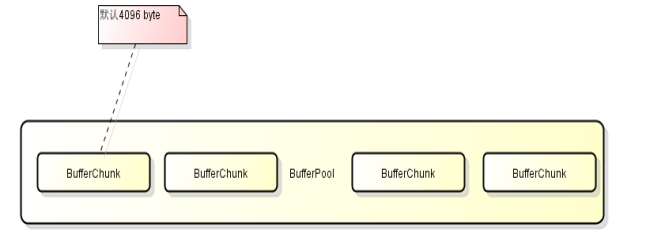
该属性指定每次分配 Socket Direct Buffer 的大小,默认是 4096 个字节。这个属性也影响 buffer pool 的长度。如果一次性获取的数过大 buffer 不够用会经常出现警告,此时可以适当调大。
processorBufferPool 属性:
该属性指定 bufferPool 计算比例值。由于每次执行 NIO 读、写操作都需要使用到 buffer,系统初始化的时候会建立一定长度的 buffer 池来加快读、写的效率,减少建立 buffer 的时间。Mycat 中有两个主要的 buffer 池:
BufferPool:BufferPool 由 ThreadLocalPool 组合而成,每次从 BufferPool 中获取 buffer 都会优先获取ThreadLocalPool 中的 buffer,未命中之后才会去获取 BufferPool 中的 buffer。也就是说 ThreadLocalPool 是作为 BufferPool 的二级缓存,每个线程内部自己使用的。BufferPool 上的 buffer 则是每个 NIOProcessor 都共享的。
这个属性的默认值为: 默认bufferChunkSize(4096) * processors属性 * 1000
BufferPool 的总长度 = bufferPool / bufferChunk。
若 bufferPool 不是 bufferChunk 的整数倍,则总长度为前面计算得出的商 + 1
假设系统线程数为 4,其他都为属性的默认值,则:
bufferPool = 4096 * 4 * 1000
BufferPool 的总长度 : 4000 = 16384000 / 4096
processorBufferLocalPercent 属性:
前面提到了 ThreadLocalPool。这个属性就是用来控制分配这个 pool 的大小用的,这个属性默认值为 100。
线程缓存百分比 = bufferLocalPercent / processors 属性。
例如,系统可以同时运行 4 个线程,使用默认值,则根据公式每个线程的百分比为 25。最后根据这个百分比来计算出具体的 ThreadLocalPool 的长度公式如下:
ThreadLocalPool 的长度 = 线程缓存百分比 * BufferPool 长度 / 100
假设 BufferPool 的长度为 4000,其他保持默认值。
那么最后每个线程建立上的 ThreadLocalPool 的长度为: 1000 = 25 * 4000 / 100
processorExecutor 属性:
这个属性主要用于指定 NIOProcessor 上共享的 businessExecutor 固定线程池大小。 mycat 在需要处理一些异步逻辑的时候会把任务提交到这个线程池中。新版本中这个连接池的使用频率不是很大了,可以设置一个较小的值。
sequnceHandlerType 属性:
指定使用 Mycat 全局序列的类型。 0 为本地文件方式,1 为数据库方式,2 为时间戳序列方式,3 为分布式ZK ID 生成器,4 为 zk 递增 id 生成。
TCP 连接相关属性:
StandardSocketOptions.SO_RCVBUF
StandardSocketOptions.SO_SNDBUF
StandardSocketOptions.TCP_NODELAY
以上这三个属性,分别由:
frontSocketSoRcvbuf 默认值: 1024 * 1024
frontSocketSoSndbuf 默认值: 4 * 1024 * 1024
frontSocketNoDelay 默认值: 1
backSocketSoRcvbuf 默认值: 4 * 1024 * 1024
backSocketSoSndbuf 默认值: 1024 * 1024
backSocketNoDelay 默认值: 1
各自设置前后端 TCP 连接参数。 Mycat 在每次建立前、后端连接的时候都会使用这些参数初始化连接。可以按系统要求适当的调整这些 buffer 的大小。
其他涉及属性:
1.1、心跳属性
mycat 中有几个周期性的任务来异步的处理一些我需要的工作。这些属性就在系统调优的过程中也是比不可少的。
processorCheckPeriod :
清理 NIOProcessor 上前后端空闲、超时和关闭连接的间隔时间。默认是 1 秒,单位毫秒。
dataNodeIdleCheckPeriod :
对后端连接进行空闲、超时检查的时间间隔,默认是 300 秒,单位毫秒。
dataNodeHeartbeatPeriod :
对后端所有读、写库发起心跳的间隔时间,默认是 10 秒,单位毫秒。
1.2、服务相关属性
这里介绍一个与服务相关的属性,主要会影响外部系统对 myact 的感知。
bindIp :
mycat 服务监听的 IP 地址,默认值为 0.0.0.0。
serverPort :
定义 mycat 的使用端口,默认值为 8066。
managerPort :
定义 mycat 的管理端口,默认值为 9066。
1.3、Mysql 连接相关属性
初始化 mysql 前后端连接所涉及到的一些属性:
packetHeaderSize :
指定 Mysql 协议中的报文头长度。默认 4。
maxPacketSize :
指定 Mysql 协议可以携带的数据最大长度。默认 16M。
idleTimeout :
指定连接的空闲超时时间。某连接在发起空闲检查下,发现距离上次使用超过了空闲时间,那么这个连接会被回收,就是被直接的关闭掉。默认 30 分钟,单位毫秒。
charset :
连接的初始化字符集。默认为 utf8。
txIsolation :
前端连接的初始化事务隔离级别,只在初始化的时候使用,后续会根据客户端传递过来的属性对后端数据库连接进行同步。默认为 REPEATED_READ,设置值为数字默认 3。
READ_UNCOMMITTED = 1;
READ_COMMITTED = 2;
REPEATED_READ = 3;
SERIALIZABLE = 4;
sqlExecuteTimeout :
SQL 执行超时的时间,Mycat 会检查连接上最后一次执行 SQL 的时间,若超过这个时间则会直接关闭这连接。默认时间为 300 秒,单位秒。
2、user 标签
<user name="test">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="benchmark">111111</property>
<proerty name="usingDecrypt">1</property>
<privileges check="false">
<schema name="TESTDB" dml="0010" showTables="custome/mysql">
<table name="tb_user" dml="0110"></table>
<table name="tb_dynamic dml="1111"></table>
</schema>
</privileges>
</user>
该标签主要用于定义登录 mycat 的用户和权限。示例定义了一个用户,用户名为 test、密码为123456,可访问的 schema 也只有 TESTDB 一个。
property属性 :
声明具体的属性值,例如修改schemas内的文本来控制用户可访问的 schema,同时访问多个 schema 的话使用,隔开,例如:
<property name="schemas">TESTDB,db1,db2<property>
Benchmark 属性:
用于mycat连接服务降级处理:benchmark基准,当前端的整体connection数达到基准值时,对来自该账户的请求开始拒绝连接,0或不设表示不限制。
usingDecrypt 属性:
是否对密码加密。默认0表示不开启,1表示开启密码加密,同时使用加密程序对密码加密。
privileges 属性:
对用户的 schema 及下级的 table 进行精细化的 DML 权限控制。
check 属性是用于标识是否开启 DML 权限检查, 默认 false 标识不检查。由于 Mycat 一个用户的 schemas 属性可配置多个 schema ,所以 privileges 的下级节点 schema 节点同样可配置多个,对多库多表进行细粒度的 DML 权限控制。
Schema/Table 上的 dml 属性:

3.2 schema.xml
1、介绍
schema.xml 作为 MyCat 中重要的配置文件之一,管理着 MyCat 的逻辑库、表、分片规则、 DataNode 以及 DataSource。
2、schema相关标签
schema标签用于定义mycat实例中的逻辑库,mycat可以有多个逻辑库,每个逻辑库可以有自己的相关配置,如果不配置schema标签,所有表配置会属于同一个默认的逻辑库。
示例如下:
<schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100" datanode="dn3,dn4">
<table name="tb_user" dataNode="dn1,dn2" rule="auto-sharing-long"></table>
</schema>
<schema name="ORDERDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_order" dataNode="dn3,dn4" rule="auto-sharing-long"></table>
</schema>
上面示例是配置了两个逻辑库,就如同在mysql中定义了两个数据库。查询数据是切换到对应的逻辑库进行。
2.1 schema标签:

name属性:
逻辑数据库的名称。
checkSQLschema属性:
该字段就是用户执行sql语句时,是否检查表明的schema,当该值设置为 true 时,如果我们执行语句(select * from USERDB.tb_user)则 MyCat 会把语句修改为(select * from tb_user)。即把表示 schema 的name去掉,避免发送到后端数据库执行时报错。建议将该字段设置为false。
sqlMaxLimit属性:
当该值设置为某个数值时。每条执行的 SQL 语句,如果没有加上 limit 语句,MyCat 也会自动的加上所对应的值。例如设置值为 100,执行select * from USERDB.tb_user;等效执行select * from USERDB.tb_user limit 100;
如果没有设置该值的话,MyCat 默认会把查询到的信息全部都展示出来。在正常使用中,还是建议加上一个值,用于减少过多的数据返回。当如果SQL 语句中也显式的指定 limit 的大小,不受该属性的约束。
2.2 table标签:
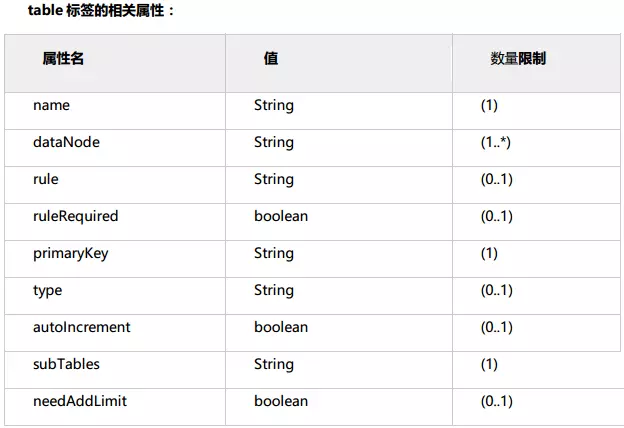
name属性:
定义逻辑表的表名,就如mysql中的table名称,同个schema中定义的必须唯一。
dataNode属性:
定义当前逻辑表所属dataNode,dataNode指定了逻辑数据库对应的物理数据库节点,该属性的值需要和 dataNode 标签中 name 属性的值相互对应。如果需要定义的 dn 过多可以使用如下的方法减少配置:
<table name="tb_user" dataNode="Dn$0-99,Dn2$100-199" rule="auto-shardinglong" >
<!--数据节点配置-->
<dataNode name="Dn" dataHost="localhost1" database="db$0-99" >
<dataNode name="Dn2" dataHost="localhost1" database=" db$0-199" >
上面的例子中,需要在mysql上建立名称为 dbs0 到 dbs99 的 database。
rule 属性:
该属性用于指定逻辑表要使用的规则名字,规则名字在 rule.xml 中定义,必须与 tableRule 标签中 name 属性属性值一一对应。
ruleRequired 属性:
该属性用于指定表是否绑定分片规则,如果配置为 true,但没有配置具体rule的话程序将会报错。
primaryKey 属性:
该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的 DN 上,如果使用该属性配置真实表的主键。那么 MyCat 会缓存主键与具体 DN 的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的 DN,但是尽管配置该属性,如果缓存并没有命中的话,还是会发送语句给所有的 DN来获得数据。
type 属性:
该属性定义了逻辑表的类型,目前逻辑表只有"全局表"和"普通表"两种类型。对应的配置:
全局表:global
普通表:不指定该值为 globla 的所有表。
autoIncrement 属性:
mycat 目前提供了自增长主键功能,但是如果对应的 mysql 节点上数据表,没有定义 auto_increment,那么在 mycat 层调用 last_insert_id()也是不会返回结果的。由于 insert 操作的时候没有带入分片键,mycat 会先取下这个表对应的全局序列,然后赋值给分片键。这样才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的分片键值。该属性默认是禁用的。
subTables属性:
使用方式添加 subTables="t_order$1-2,t_order3",目前分表 1.6 版本以后开始支持,并且 dataNode 在分表条件下只能配置一个,分表条件下不支持各种条件的join 语句。
needAddLimit 属性:
指定表是否需要自动的在每个语句后面加上 limit 限制。由于使用了分库分表,数据量有时会特别巨大。mycat 就自动的为我们加上LIMIT 100。如果语句中有 limit,就不会加上。该属性默认为 true,你也可以设置成 "false"来禁用掉。
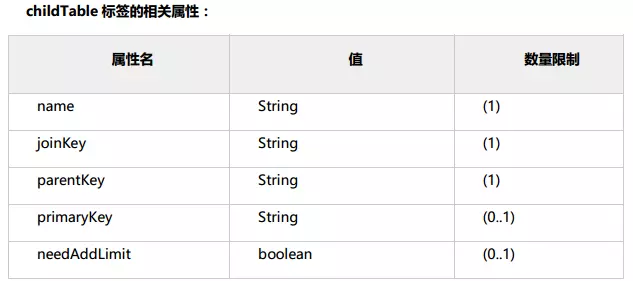
2.3 childTable 标签
childTable 标签用于定义 E-R 分片的子表。通过标签上的属性与父表进行关联
示例:
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" primaryKey="ID" joinKey="order_id" parentKey="id" />
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
name 属性:
定义子表的表名;
joinKey 属性:
插入子表的时候会使用这个列的值查找父表存储的数据节点。
parentKey 属性:
该属性指定的值一般为与父表建立关联关系的列名。程序首先获取 joinkey 的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上,从而确定子表存储的位置。
primaryKey 属性:
同 table 标签所描述的。
needAddLimit 属性:
同 table 标签所描述的。
2.4 dataNode 标签:
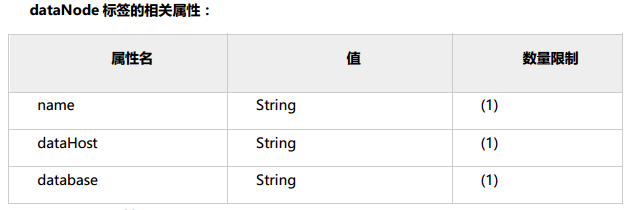
dataNode标签定义了 MyCat 中的数据节点,也就是我们通常说所的数据分片。一个dataNode标签就是一个独立的数据分片。
<dataNode name="dn1" dataHost="localhost1" database="db1" />
示例使用名字为localhost1数据库实例上的db1物理数据库,这就组成一个数据分片,使用名字dn1 识这个分片。
name 属性:
定义数据节点的名字,这个名字需要是唯一的,我们需要在 table 标签上应用这个名字,来建立逻辑表与分片对应的关系。
dataHost 属性:
该属性用于定义该分片属于哪个数据库实例的,属性值是引用 dataHost 标签上定义的 name 属性。
database 属性:
该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个维度来定义分片:实例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。
2.5 dataHost 标签:
作为 schema.xml 中最后的一个标签,该标签在 mycat 逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。

<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456" />
<readHost host="hostS2" url="localhost:3306" user="root" password="123456"/>
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root" password="123456" />
</dataHost>

name 属性:
唯一标识 dataHost 标签,供dataNode标签使用。
maxCon 属性:
指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的 writeHost、 readHost 标签都会使用这个属性的值来实例化出连接池的最大连接数。
minCon 属性:
指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance 属性:
负载均衡类型,具体有以下4种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
2. balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
3. balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。
4. balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有。
writeType 属性:
负载均衡写操作类型,目前的取值有 2 种:
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后以切换后的为准,切换记录在配置文中:dnindex.properties。
2. writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
dbType 属性:
指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如:mongodb、 oracle、 spark 等
dbDriver 属性:
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
从 1.6 版本开始支持 postgresql 的 native 原始协议如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到 MYCATlib 目录下,并检查驱动 JAR 包中包括如下目录结构的文件:META-INFservicesjava.sql.Driver。在这个文件内写上具体的 Driver 类名,例如:com.mysql.jdbc.Driver
switchType 属性:
-1 表示不自动切换
1 默认值,自动切换
2 基于 MySQL 主从同步的状态决定是否切换 ,心跳语句为 show slave status
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1),心跳语句为 show status like 'wsrep%'.
tempReadHostAvailable 属性:
如果配置了这个属性 writeHost 下面的 readHost 仍旧可用,默认 0 可配置(0、 1)
2.6 heartbeat 标签
该标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL 可以使用 select user(),Oracle 可以使用 select 1 from dual 等。
2.7 writeHost 标签、 readHost 标签
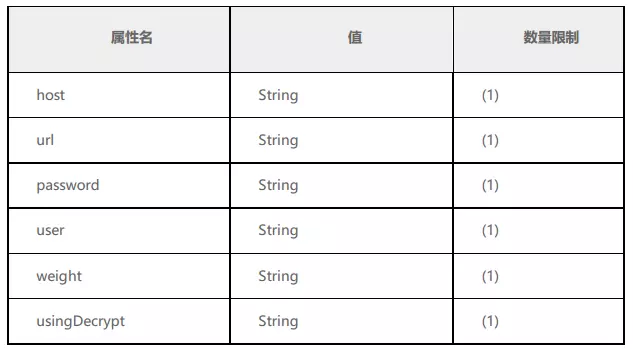
这两个标签都指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同的是,writeHost 指定写实例、 readHost 指定读实例,通过这些读写实例来满足系统的需求。
在一个 dataHost 内可以定义多个 writeHost 和 readHost。但是,如果 writeHost 指定的后端数据库宕机,那么这个 writeHost 绑定的所有 readHost 都将不可用。另一方面,由于这个 writeHost 宕机系统会自动的检测到,并切换到备用的 writeHost 上去。
host 属性:
用于标识不同实例,一般 writeHost 我们使用*M1,readHost 我们用*S1。
url 属性:
后端实例连接地址,如果是使用 native 的 dbDriver,则一般为 address:port 这种形式。用 JDBC 或其他的dbDriver,则需要特殊指定。当使用 JDBC 时则可以这么写:jdbc:mysql://localhost:3306/。
user 属性:
后端存储实例需要的用户名字。
password 属性:
后端存储实例需要的密码。
weight 属性:
权重配置,在 readhost 中作为读节点的权重(1.4 以后)
usingDecrypt 属性:
是否对密码加密默认。0表示不开启。1表示开启,同时使用加密程序对密码加密。
3.3 rule.xml
rule.xml配置文件定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。
该文件里面主要有tableRule和function这两个标签。
- tableRule 标签
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
- name 属性:
指定唯一的名字,用于标识不同的表规则。
- rule标签:
指定对物理表中的哪一列进行拆分和使用什么路由算法。
columns 指定要拆分的列名字。
algorithm 使用function标签中的name属性,连接表规则和具体路由算法。
- function标签
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
name属性:
指定算法的名字。
class属性:
指定路由算法具体的类名字。
property属性:
为具体算法需要用到的一些属性。
3、常用的分片规则
3.1、枚举法
<tableRule name="sharding-by-intfile">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>

partition-hash-int.txt 配置:
10000=0
10010=1
上面columns 标识将要分片的表字段,algorithm 分片函数,其中分片函数配置中,mapFile标识配置文件名称,type默认值为0,0表示Integer,非零表示String,所有的节点配置都是从0开始,0代表节点1。
defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点,结点为指定的值,默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点,如果不配置默认节点(defaultNode值小于0表示不配置默认节点),碰到不识别的枚举值就会报错,like this:can't find datanode for sharding column:column_nameval:ffffffff 。
3.2、固定分片hash算法

<tableRule name="rule1">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
上面columns 标识将要分片的表字段,algorithm 分片函数,partitionCount 分片个数列表,partitionLength 分片范围列表。分区长度:默认为最大2^n=1024 ,即最大支持1024分区。
约束 :count,length两个数组的长度必须是一致的。1024 = sum((count[i]*length[i])). count和length两个向量的点积恒等于1024。
示例:

@Test
public void testPartition() {
// 本例的分区策略:希望将数据水平分成3份,前两份各占25%,第三份占50%。(故本例非均匀分区)
// |<---------------------1024------------------------>|
// |<----256--->|<----256--->|<----------512---------->|
// | partition0 | partition1 | partition2 |
// | 共2份,故count[0]=2 | 共1份,故count[1]=1 |
int[] count = new int[] { 2, 1 };
int[] length = new int[] { 256, 512 };
PartitionUtil pu = new PartitionUtil(count, length);
// 下面代码演示分别以offerId字段或memberId字段根据上述分区策略拆分的分配结果
int DEFAULT_STR_HEAD_LEN = 8; // cobar默认会配置为此值
long offerId = 12345;
String memberId = "qiushuo";
// 若根据offerId分配,partNo1将等于0,即按照上述分区策略,offerId为12345时将会被分配到partition0中
int partNo1 = pu.partition(offerId);
// 若根据memberId分配,partNo2将等于2,即按照上述分区策略,memberId为qiushuo时将会被分到partition2中
int partNo2 = pu.partition(memberId, 0, DEFAULT_STR_HEAD_LEN);
Assert.assertEquals(0, partNo1);
Assert.assertEquals(2, partNo2);
}

如果需要平均分配设置:平均分为4分片,partitionCount*partitionLength=1024
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
3.3、范围约定

<tableRule name="auto-sharding-long">
<rule>
<columns>user_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>

autopartition-long.txt文件:

# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1

columns 标识将要分片的表字段,algorithm 分片函数,rang-long 函数中mapFile代表配置文件路径,所有的节点配置都是从0开始,及0代表节点1,此配置非常简单,即预先制定可能的id范围到某个分片。
3.4、求模法

<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>

columns 标识将要分片的表字段,algorithm 分片函数,此种配置非常明确即根据id与count(你的结点数)进行求模预算,相比方式1,此种在批量插入时需要切换数据源,id不连续。
3.5、日期列分区法

<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function..PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sPartionDay">10</property>
</function>

columns 标识将要分片的表字段,algorithm 分片函数,配置中配置了开始日期,分区天数,即默认从开始日期算起,分隔10天一个分区。
3.6、通配取模

<tableRule name="sharding-by-pattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern">
<property name="patternValue">256</property>
<property name="defaultNode">2</property>
<property name="mapFile">partition-pattern.txt</property>
</function>

partition-pattern.txt

# id partition range start-end ,data node index
###### first host configuration
1-32=0
33-64=1
65-96=2
97-128=3
######## second host configuration
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7

columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,defaoultNode 默认节点,如果不配置了默认,则默认是0即第一个结点。mapFile 配置文件路径
,配置文件中,1-32 即代表id%256后分布的范围,如果在1-32则在分区1,其他类推,如果id非数字数据,则会分配在defaoultNode 默认节点。代码示例:
String idVal = "0";
Assert.assertEquals(true, 7 == autoPartition.calculate(idVal));
idVal = "45a";
Assert.assertEquals(true, 2 == autoPartition.calculate(idVal));
3.7、ASCII码求模通配

<tableRule name="sharding-by-prefixpattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="patternValue">256</property>
<property name="prefixLength">5</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
partition-pattern.txt
# range start-end ,data node index
# ASCII
# 48-57=0-9
# 64、65-90=@、A-Z
# 97-122=a-z
###### first host configuration
1-4=0
5-8=1
9-12=2
13-16=3
###### second host configuration
17-20=4
21-24=5
25-28=6
29-32=7
0-0=7
columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,prefixLength ASCII 截取的位数。mapFile 配置文件路径,配置文件中,1-32 即代表id%256后分布的范围,如果在1-32则在分区1,其他类推。
此种方式类似方式6只不过采取的是将列种获取前prefixLength位列所有ASCII码的和进行求模sum%patternValue ,获取的值,在通配范围内的分片数,
/**
* ASCII编码:
* 48-57=0-9阿拉伯数字
* 64、65-90=@、A-Z
* 97-122=a-z
*
*/
String idVal="gf89f9a";
Assert.assertEquals(true, 0 == autoPartition.calculate(idVal));
idVal="8df99a";
Assert.assertEquals(true, 4 == autoPartition.calculate(idVal));
idVal="8dhdf99a";
Assert.assertEquals(true, 3 == autoPartition.calculate(idVal));
3.8、编程指定
<tableRule name="sharding-by-substring">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">8</property>
<property name="defaultPartition">0</property>
</function>
columns 标识将要分片的表字段,algorithm 分片函数,此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。
例如id=05-100000002,在此配置中代表根据id中从startIndex=0开始,截取size=2位数字即05,05就是获取的分区,如果没传默认分配到defaultPartition。
3.9、字符串拆分hash解析

<tableRule name="sharding-by-stringhash">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionByString">
<property name="length">512</property> <!-- zero-based -->
<property name="count">2</property>
<property name="hashSlice">0:2</property>
</function>
columns 标识将要分片的表字段,algorithm 分片函数 ,函数中length代表字符串hash求模基数,count分区数,hashSlice hash预算位,即根据子字符串 hash运算,
hashSlice : 0 means str.length(), -1 means str.length()-1
/**
* "2" -> (0,2)<br/>
* "1:2" -> (1,2)<br/>
* "1:" -> (1,0)<br/>
* "-1:" -> (-1,0)<br/>
* ":-1" -> (0,-1)<br/>
* ":" -> (0,0)<br/>
*/
public class PartitionByStringTest {
@Test
public void test() {
PartitionByString rule = new PartitionByString();
String idVal=null;
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
rule.setHashSlice("0:2");
// idVal = "0";
// Assert.assertEquals(true, 0 == rule.calculate(idVal));
// idVal = "45a";
//Assert.assertEquals(true, 1 == rule.calculate(idVal));
//last 4
rule = new PartitionByString();
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
//last 4 characters
rule.setHashSlice("-4:0");
idVal = "aaaabbb0000";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
idVal = "aaaabbb2359";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
}
}
3.10、一致性hash
<tableRule name="sharding-by-murmur">
<rule>
<columns>user_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0-->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍-->
<!--
<property name="weightMapFile">weightMapFile</property>
节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!--
<property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
一致性hash预算有效解决了分布式数据的扩容问题,前1-9中id规则都多少存在数据扩容难题,而10规则解决了数据扩容难点。
4 关于分片sharding
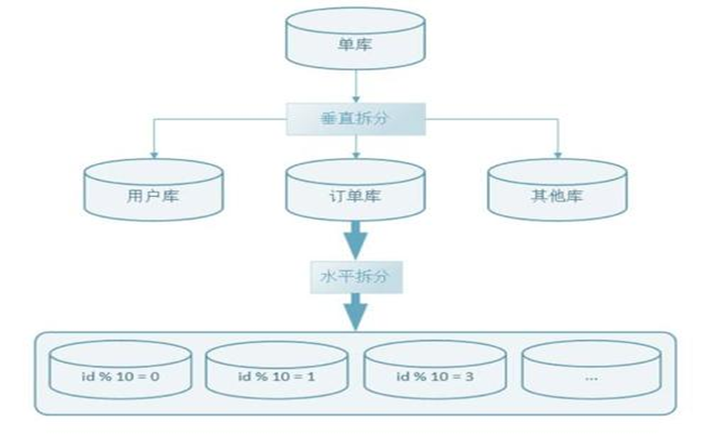
分库:以表的视角,将表分配到不同的数据库中
分表:以数据的视角,根据规则将数据分配到不同的数据库中
4.1 垂直分库
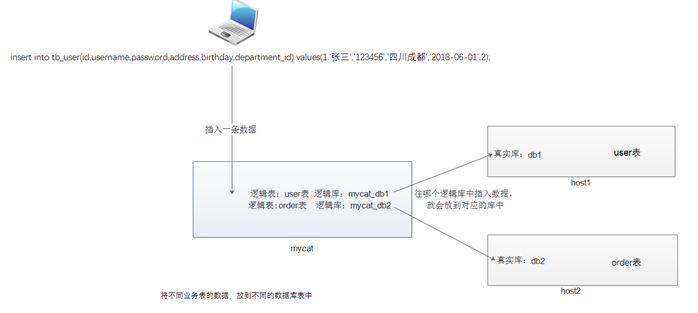 垂直分库:将不同业务的表放到不同的数据库中。
垂直分库:将不同业务的表放到不同的数据库中。
- schema.xml文件
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema逻辑数据库 -->
<schema name="mycat_db1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" />
<schema name="mycat_db2" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn2" />
<!--使用dataNode将实际数据库和逻辑数据库映射-->
<dataNode name="dn1" dataHost="host1" database="db1" />
<dataNode name="dn2" dataHost="host2" database="db2" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!--写上数据库链接信息-->
<writeHost host="hostM1" url="192.168.100.162:3306" user="root" password="root" />
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!--写上数据库链接信息-->
<writeHost host="hostM2" url="192.168.100.163:3306" user="root" password="root" />
</dataHost>
</mycat:schema>
- server.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<!--帐号密码以及所链接的逻辑库-->
<user name="mycat">
<property name="password">test</property>
<property name="schemas">mycat_db1,mycat_db2</property>
</user>
<!--只读的用户信息-->
<user name="user">
<property name="password">user</property>
<property name="schemas">mycat_db1,mycat_db2</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
- 在mysql创建真实数据库 (逻辑库要真实对应的数据库)
162机器:create database db1;
163机器:create database db2;
- 登录mycat,创建表
#user表会放在了162mysql中
mysql -umycat -p123456 -P8066 -h 192.168.100.161
use mycat_db1;
create table user(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
insert into user(id,username,password,address,birthday,department_id) values(1,'张三','123456','四川成都','2018-06-01',2);
insert into user(id,username,password,address,birthday,department_id) values(2,'李四','123456','四川成都','2
018-06-01',2);
select * from user;
#order表会放到163mysql中
use mycat_db2;
create table orders(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
insert into orders(id,username,password,address,birthday,department_id) values(1,'订单1','123456','四川成都','2018-06-01',2);
insert into orders(id,username,password,address,birthday,department_id) values(2,'订单2','123456','四川成都','2018-06-01',2);
以上配置是将mycat_db1,mycat_db2数据库分别放在ip1,ip2对应的数据库实例中。
优点:
拆分后业务清晰,拆分规则明确;
系统之间整合或扩展容易;
数据维护简单。
缺点:
部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度;
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高;
事务处理复杂。
4.2 水平分表
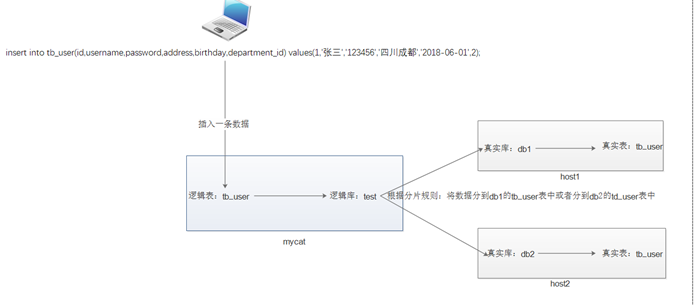
水平分表是对数据量很大的表进行拆分,把这些表按照某种规则将数据存放到不同的数据库中。示例:
- schema.xml文件
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- tb_class和tb_student有外键关联关系,可以测试join -->
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="tb_user" dataNode="dn1,dn2" rule="rule1" primaryKey="id"/>
</schema>
<dataNode name="dn1" dataHost="host1" database="db1" />
<dataNode name="dn2" dataHost="host2" database="db2" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.100.162:3306" user="root" password="root" />
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.100.163:3306" user="root" password="root" />
</dataHost>
</mycat:schema>
- server.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<!--帐号密码以及所链接的逻辑库-->
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">test</property>
</user>
<!--只读的用户信息-->
<user name="user">
<property name="password">123456</property>
<property name="schemas">test</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
- rule.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://org.opencloudb/">
<tableRule name="rule1">
<!-按照id规则,将id除于1024然后取余,如果余数落在0~512就将数据写到第一个数据库,如果是在512~1024就放到第二个数据库-->
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<!--分成两片,每片的区间是512,两个相乘必须是1024-->
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">2</property>
<property name="partitionLength">512</property>
</function>
</mycat:rule>
- 在mysql创建真实数据库和表(分表就是,逻辑库和逻辑表要在mysql有真实的对应)
162机器:
create database db1;
use db1;
create table tb_user(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
163机器:
create database db2;
use db2;
create table tb_user(
id int not null auto_increment,
username char(20) not null,
password char(33) not null,
address char(8) not null,
birthday date,
department_id int not null,
primary key (id)
);
- 登录mycat,创建表
mysql -umycat -p123456 -P8066 -h 192.168.100.161
use test;
insert into tb_user(id,username,password,address,birthday,department_id) values(1,'张三','123456','四川成都','2018-06-01',2);
insert into tb_user(id,username,password,address,birthday,department_id) values(513,'李四','123456','四川成都','2018-06-01',2);
#根据分片规则,第一条数据会放到db1数据库上,第二条数据会放到db2数据库上,
以上配置是把id在0~512的数据放在ip1对应的数据库mycat1中的tb_user表中,512~1024的数据放在ip2对应的数据库mycat2中的tb_user表中, 以此类推
优点 :
拆分规则抽象好,join 操作基本可以数据库做;
不存在单库大数据,高并发的性能瓶颈;
应用端改造较少;
提高了系统的稳定性跟负载能力。
缺点 :
拆分规则难以抽象;
分片事务一致性难以解决;
数据多次扩展难度跟维护量极大;
跨库 join 性能较差
4.2 更多分片算法
取模mod-long: 你一条我一条,2.3就是用的该算法
https://www.cnblogs.com/alan319/p/10556979.html