今天要写的是爬取百度图片
一、分析过程
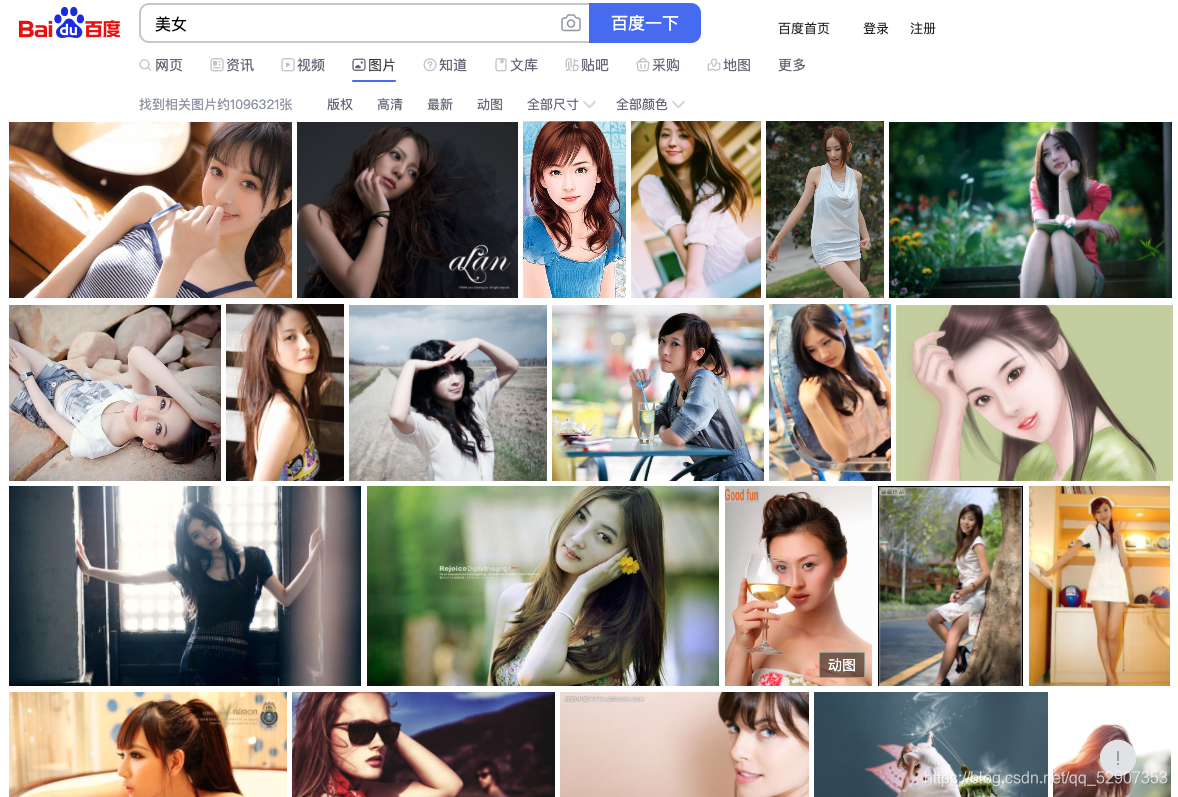
1.首先,打开百度,然后打开我们的抓包工具 然后搜索一个内容,点击图片
2.之前用鼠标滚轮往下滑的过程中,发现图片是动态加载出来的,也就说明这是一个ajax请求。
有了这些思路,打开我们的抓包工具
3.选择XHR选项
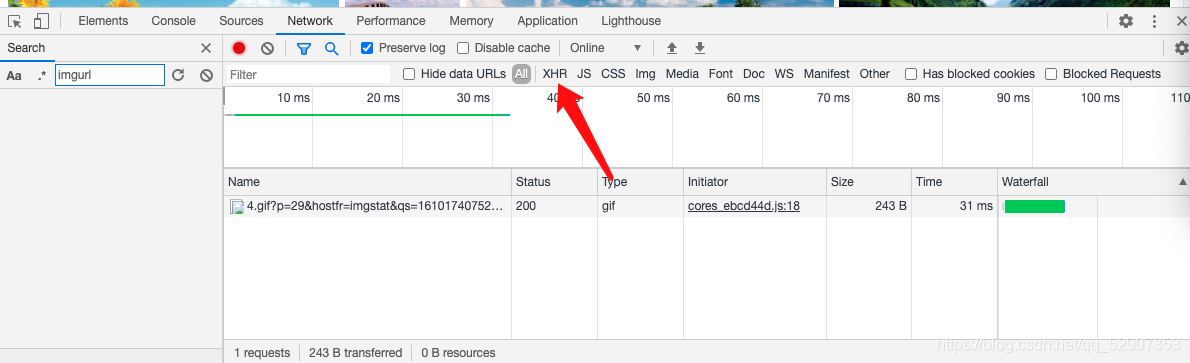
4.然后鼠标滚轮往下拖动,我们会发现一个数据包。

5.复制这个数据包的URL请求
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8222346496549682679&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%BE%8E%E5%A5%B3&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E7%BE%8E%E5%A5%B3&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=girl&pn=30&rn=30&gsm=1e&1610176483429=
6.点开这个URL看到其携带的参数
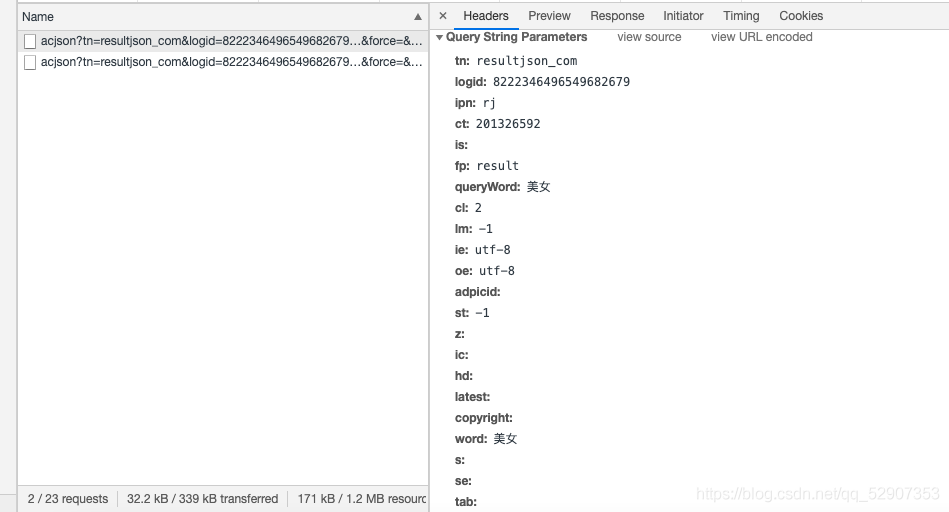
然后也复制一下
开始编写相关代码
二、编写代码
1.首先引入我们所需要的模块
import requests
2.开始代码编写
#进行UA伪装
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '美女',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z':'' ,
'ic':'' ,
'hd': '',
'latest': '',
'copyright': '',
'word': '美女',
's':'' ,
'se':'' ,
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': '1',
'rn': '30',
'gsm': '1e',
}
#将编码形式转换为utf-8
page_text = requests.get(url=url,headers=header,params=param)
page_text.encoding = 'utf-8'
page_text = page_text.text
print(page_text)
到了这一步,我们先访问一下,看看能不能取得到页面返回的数据
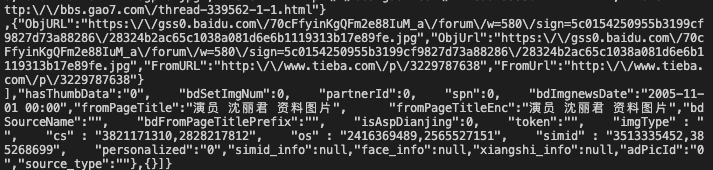
我们成功取得了返回数据
之后我们返回到网页中,查看数据包,查看他的返回数据
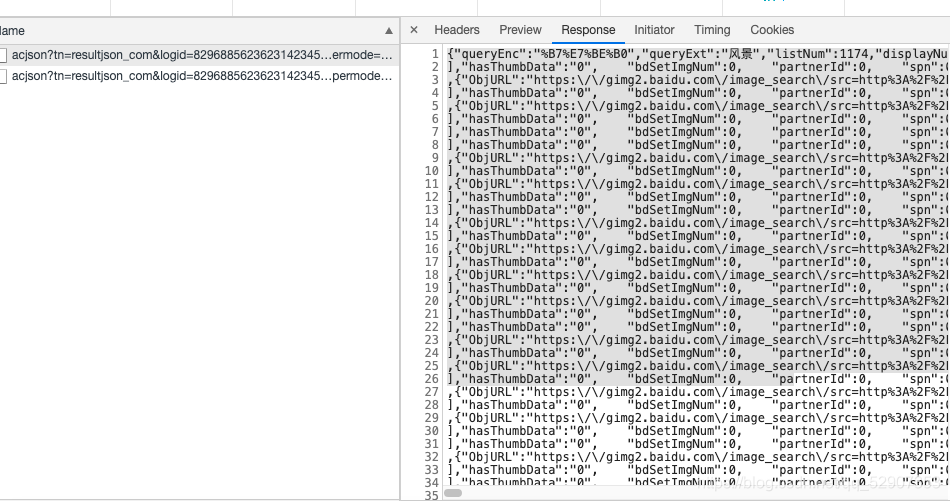
然后将其放入json在线解析工具中发现了图片所对应的地址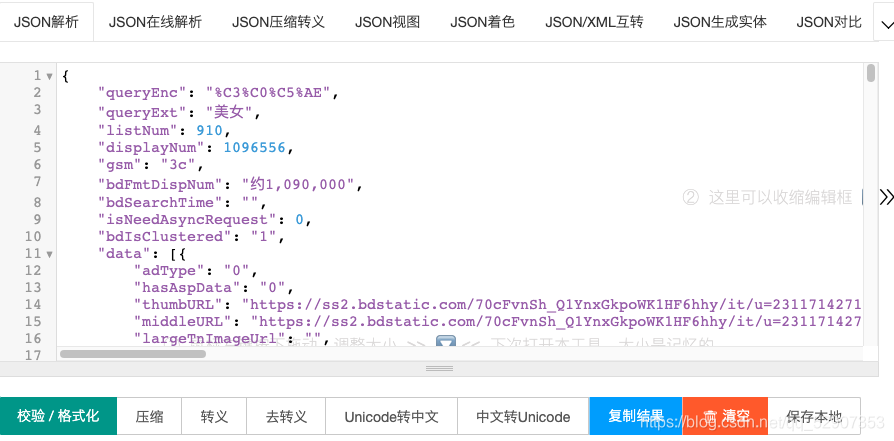
之后继续编写代码
将返回数据转换为json格式,而且发现数据全部储存在一个字典当中,并且图片的地址也在一个字典当中
然后将链接地址取出
page_text = page_text.json()
#先取出所有链接所在的字典,并将其存储在一个列表当中
info_list = page_text['data']
#由于利用此方式取出的字典最后一个为空,所以删除列表中最后一个元素
del info_list[-1]
#定义一个存储图片地址的列表
img_path_list = []
for info in info_list:
img_path_list.append(info['thumbURL'])
#再将所有的图片地址取出,进行下载
#n将作为图片的名字
n = 0
for img_path in img_path_list:
img_data = requests.get(url=img_path,headers=header).content
img_path = './' + str(n) + '.jpg'
with open(img_path,'wb') as fp:
fp.write(img_data)
n += 1
在完成这些以后,我们还想要实现百度图片下载多页,经过分析,我发现在我们提交的参数里,pn代表的是从第几张图片开始加载,顺着这个思路我们可以给上面的代码套一个大循环,即第一次下载从第1张开始,下载三十张,第二次从第31张开始下载。
OK!思路已经明确,开始修改上面的代码
import requests
from lxml import etree
page = input('请输入要爬取多少页:')
page = int(page) + 1
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
n = 0
pn = 1
#pn是从第几张图片获取 百度图片下滑时默认一次性显示30张
for m in range(1,page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '美女',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z':'' ,
'ic':'' ,
'hd': '',
'latest': '',
'copyright': '',
'word': '美女',
's':'' ,
'se':'' ,
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': pn,#从第几张图片开始
'rn': '30',
'gsm': '1e',
}
page_text = requests.get(url=url,headers=header,params=param)
page_text.encoding = 'utf-8'
page_text = page_text.json()
info_list = page_text['data']
del info_list[-1]
img_path_list = []
for i in info_list:
img_path_list.append(i['thumbURL'])
for img_path in img_path_list:
img_data = requests.get(url=img_path,headers=header).content
img_path = './' + str(n) + '.jpg'
with open(img_path,'wb') as fp:
fp.write(img_data)
n = n + 1
pn += 29
如果感觉我写的还可以就请点个赞把,如果有错误希望指出,我会积极改正!
