摘自mailinator,链接:https://mailinator.blogspot.com/2009/06/beautiful-race-condition.html
I recently gave a keynote at the ICIS 2009 conference in Shanghai. The topic was why multithreaded programming seemed so easy, yet turned out to be so hard. The fun part was I investigated (per my last post and this one) several old, personal concurrency demons I knew existed but wanted to know more about.
One of those was, indeed, my favorite race condition. It doesn't escape me that its probably wholly unhealthy to even *have* a favorite race condition (akin to having a favorite pimple or something) - but nonetheless, the elegance of this one still makes my heart aflutter.
The scenario of this race is that we assume, not terribly inaccurately, that race conditions at times, can cause corrupted data. However, what if we have a situation where we sort of don't mind some corrupted data? A "good enough" application as it were.
The dangerous part of all this is if we assume (without digging in) what kind of data corruption can happen. As you'll see, you might just not get the type of data corruption you were hoping for (which is one of the sillier sentences I've ever written).
The particular instance of this kind of happy racing I've encountered is where someone uses a java.util.HashMap as a cache. I've never done such a thing myself, but I heard about this race and thus this analysis. They may use it with a linked-list or maybe just raw, but the baseline is that they figure a synchronized HashMap will be expensive - and in their case, a race condition inside the HashMap will just lose (or double up on) an entry now and then.
That is - a race condition between two (or more) threads might accidentally drop an entry causing an extra cache miss - no biggie. Or, it may cause one thread to re-cache an entry that didn't need it. Also no biggie. In other words, a slightly imprecise, yet very fast cache is ok by them. (of course, this assumption is dead wrong - don't do that - read on for why!)
So they setup a HashMap in some global manner, and allow any number of nefarious threads bang away on it. Let them put and get to their hearts content.
Now if you happen to know how HashMap works, if the size of the map exceeds a given threshold, it will act to resize the map. It does that by creating a new bucket array of twice the previous size, and then putting every old element into that new bucket array.
Here's the core of the loop that does that resize:
1: // Transfer method in java.util.HashMap -
2: // called to resize the hashmap
3:
4: for (int j = 0; j < src.length; j++) {
5: Entry<k,v> e = src[j];
6: if (e != null) {
7: src[j] = null;
8: do {
9: Entry<k,v> next = e.next;
10: int i = indexFor(e.hash, newCapacity);
11: e.next = newTable[i];
12: newTable[i] = e;
13: e = next;
14: } while (e != null);
15: }
16: }
Simply, after line 9, variable e points to a node that is about to be put into the new (double-wide) bucket array. Variable
next holds a reference to the next node in the existing table (because in line 11, we'll destroy that relation).
The goal is that nodes in the new table get scattered around a bit. There's no care to keep any ordering within a bucket (nor should there be). HashMap's don't care about ordering, they care about constant time access.
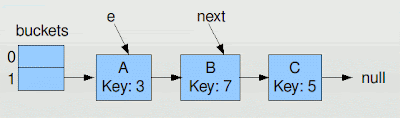
Graphically, let's say we start with the HashMap below. This one only has 2 buckets (the default of java.util.HashMap is 16) which will suffice for explanatory purposes (and save room).
As our loop starts, we assign e and next to A and B, respectively. The A node is about to be moved, the B node is next.
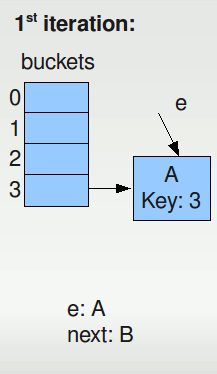
We have created a double-sized bucket array (in this case size=4) and migrate node A in iteration 1.
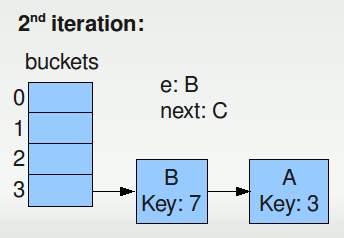
Iteration 2 moves node B and Iteration 3 moves node C. Note that next=null is the ending condition of our while loop for migrating any given bucket (read that again, its important to the end of the story).
Also important to the story, note that the migration inverted the order of Node's A and B. This was incidental to the smart idea of inserting new nodes at the top of the list instead of traversing to find the end each time and plunking them there. A normal put operation would still have to check that its inserting (and not replacing) but given a resize can't replace, this saves us a lot of "find the end" traversals.
Finally, after iteration 3, our new HashMap looks like this:

Our resize accomplished precisely the mission it set out to. It took our 3-deep bucket and morphed it into a 2-deep and 1-deep one.
Now, that's all well and good, but this article isn't about HashMap resizing (exactly), its about a race condition.
So, let's assume that in our original happy HashMap (the one above with just 2 buckets) we have two threads. And both of those threads enter the map for some operation. And both of those threads simultaneously realize the map needs a resize. So, simultaneously they both go try to do that.
As an aside, the fact that this HashMap is unsynchronized opens it up to a scary array of unimaginable visibility issues but that's another story. I'm sure that using an unsynchronized HashMap in this fashion can wrack evil in ways unlike man has ever seen, I'm just addressing one possible race in one possible scenario.
Ok.. back to the story.
So two threads, which we'll cleverly name Thread1 and Thread2 are off to do a resize. Let's say Thread1 beats Thread2 by a moment. And let's say Thread1 (by the way, the fun part about analyzing race conditions is that nearly anything can happen - so you can say "Let's say" all darn day long and you'll probably be right!) gets to line 10 and stops. Thats right, after executing line 9, Thread1 gets kicked out of the (proverbial) CPU.
1: // Transfer method in java.util.HashMap -
2: // called to resize the hashmap
3:
4: for (int j = 0; j < src.length; j++) {
5: Entry<k,v> e = src[j];
6: if (e != null) {
7: src[j] = null;
8: do {
9: Entry<k,v> next = e.next;
// Thread1 STOPS RIGHT HERE
10: int i = indexFor(e.hash, newCapacity);
11: e.next = newTable[i];
12: newTable[i] = e;
13: e = next;
14: } while (e != null);
15: }
16: }
Since it passed line 9, Thread1 did get to set its e and next variables. The situation looks like this (I've renamed e and next to e1 and next1 to keep them straight between the two threads as both threads have their own e and next).
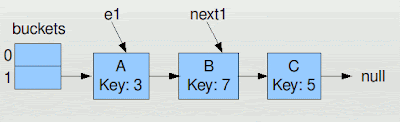
Again, Thread1 didn't actually get to move any nodes (by this time in the code, it did allocate a new bucket array).
What happens next? Thread2, that's what. Luckily, what Thread2 does is simple - let's say it runs through the full resize. All the way. It completes.
We get this:

Note that e1 and next1 still point to the same nodes. But those nodes got shuffled around. And most importantly the next relation got reversed.
That is, when Thread1 started, it had node A with its next as node B. Now, its the opposite, node B has its next as node A.
Sadly (and paramount to the plot of this story) is that Thread1 doesn't know that. If you're thinking that the invertedness of Thread1's e1 and next1 are important, you're right.
Here's Thread1's next few iterations. We start with Thread2's bucket picture because thats really the correct "next" relations for our nodes now.

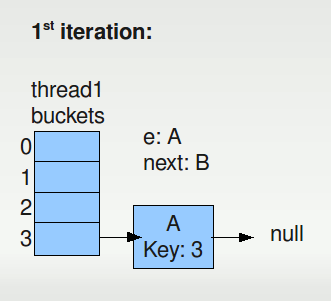

Everything sort of looking ok.. except for our e and next at this point. The next iteration will plunk A into the front of the bucket 3 list (it is after all, next). And will assign its next to whatever happens to already be there - that is, node B.
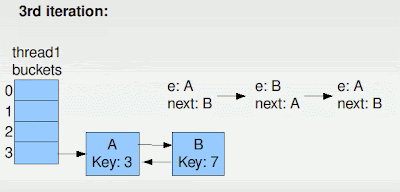
Woah. Thar she blows.
So right about now Thread1 goes into, what we like to call in the biz, an "infinite loop". Any subsequent get operations that hit this bucket start searching down the list and, go into, yep - an infinite loop. Any put operation that first needs to scan the nodes to see if its going to do a replace, will, you guessed it, go into an infinite loop. Basically, this map is a pit of infinite loopeness.
If you remember we noted that race conditions cause data corruption. Well, yeah, thats what we have here - just very unlucky data corruption on pointer structures. I'm the first to admit this stuff is tricky - if you found errors in my analysis I'll happily fix this post.
Now I had the happy fortune for a time of sharing an office with Josh Bloch who wrote java.util.HashMap. When I innocently mentioned he had a bug in his code given this behavior, he did indeed (to use Josh's word's) go non-linear on me.
And he was right. This is not a bug. HashMap is built specifically for its purpose and this implementation is not intended as threadsafe. There's a gaggle of ways to make it threadsafe, but in plain, vanilla, (and very fast) form - its not. And needless to say, you shouldn't be using it that way.
Race conditions are nothing to mess with and the worst ones are the ones that don't crash your program but let it wander down some unintended path. Synchronization isn't just for fun you know.
And nefarious uses of HashMap aside, I still attest - this is, indeed, a beautiful race.
Addendum: I've been yelled at a few times for calling any race condition "beautiful". I'll defend myself by our apparently human nature to generally call intricate complexity beautiful (i.e. waves crashing on a shore, nature in general).
Most races end up being about data-corruption. This one is data-corruption that manifests as control-flow-corruption. And it does so fantastically without an error (infinite loops notwithstanding).
As the evolution analogy goes, if you drive a needle into a pocket watch - chances are you'll simply destroy it. But there's a tiny chance you'll actually make it a better watch (clearly, not the case here). And another tiny chance you'll simply make it something "different" - but still, per se, functioning.
Again, my use of "beautiful" might be more appropriate as "a complex mutation with surprising non-destruction" :)
One of those was, indeed, my favorite race condition. It doesn't escape me that its probably wholly unhealthy to even *have* a favorite race condition (akin to having a favorite pimple or something) - but nonetheless, the elegance of this one still makes my heart aflutter.
The scenario of this race is that we assume, not terribly inaccurately, that race conditions at times, can cause corrupted data. However, what if we have a situation where we sort of don't mind some corrupted data? A "good enough" application as it were.
The dangerous part of all this is if we assume (without digging in) what kind of data corruption can happen. As you'll see, you might just not get the type of data corruption you were hoping for (which is one of the sillier sentences I've ever written).
The particular instance of this kind of happy racing I've encountered is where someone uses a java.util.HashMap as a cache. I've never done such a thing myself, but I heard about this race and thus this analysis. They may use it with a linked-list or maybe just raw, but the baseline is that they figure a synchronized HashMap will be expensive - and in their case, a race condition inside the HashMap will just lose (or double up on) an entry now and then.
That is - a race condition between two (or more) threads might accidentally drop an entry causing an extra cache miss - no biggie. Or, it may cause one thread to re-cache an entry that didn't need it. Also no biggie. In other words, a slightly imprecise, yet very fast cache is ok by them. (of course, this assumption is dead wrong - don't do that - read on for why!)
So they setup a HashMap in some global manner, and allow any number of nefarious threads bang away on it. Let them put and get to their hearts content.
Now if you happen to know how HashMap works, if the size of the map exceeds a given threshold, it will act to resize the map. It does that by creating a new bucket array of twice the previous size, and then putting every old element into that new bucket array.
Here's the core of the loop that does that resize:
1: // Transfer method in java.util.HashMap -
2: // called to resize the hashmap
3:
4: for (int j = 0; j < src.length; j++) {
5: Entry<k,v> e = src[j];
6: if (e != null) {
7: src[j] = null;
8: do {
9: Entry<k,v> next = e.next;
10: int i = indexFor(e.hash, newCapacity);
11: e.next = newTable[i];
12: newTable[i] = e;
13: e = next;
14: } while (e != null);
15: }
16: }
Simply, after line 9, variable e points to a node that is about to be put into the new (double-wide) bucket array. Variable
next holds a reference to the next node in the existing table (because in line 11, we'll destroy that relation).
The goal is that nodes in the new table get scattered around a bit. There's no care to keep any ordering within a bucket (nor should there be). HashMap's don't care about ordering, they care about constant time access.
Graphically, let's say we start with the HashMap below. This one only has 2 buckets (the default of java.util.HashMap is 16) which will suffice for explanatory purposes (and save room).
As our loop starts, we assign e and next to A and B, respectively. The A node is about to be moved, the B node is next.

We have created a double-sized bucket array (in this case size=4) and migrate node A in iteration 1.

Iteration 2 moves node B and Iteration 3 moves node C. Note that next=null is the ending condition of our while loop for migrating any given bucket (read that again, its important to the end of the story).

Also important to the story, note that the migration inverted the order of Node's A and B. This was incidental to the smart idea of inserting new nodes at the top of the list instead of traversing to find the end each time and plunking them there. A normal put operation would still have to check that its inserting (and not replacing) but given a resize can't replace, this saves us a lot of "find the end" traversals.
Finally, after iteration 3, our new HashMap looks like this:

Our resize accomplished precisely the mission it set out to. It took our 3-deep bucket and morphed it into a 2-deep and 1-deep one.
Now, that's all well and good, but this article isn't about HashMap resizing (exactly), its about a race condition.
So, let's assume that in our original happy HashMap (the one above with just 2 buckets) we have two threads. And both of those threads enter the map for some operation. And both of those threads simultaneously realize the map needs a resize. So, simultaneously they both go try to do that.
As an aside, the fact that this HashMap is unsynchronized opens it up to a scary array of unimaginable visibility issues but that's another story. I'm sure that using an unsynchronized HashMap in this fashion can wrack evil in ways unlike man has ever seen, I'm just addressing one possible race in one possible scenario.
Ok.. back to the story.
So two threads, which we'll cleverly name Thread1 and Thread2 are off to do a resize. Let's say Thread1 beats Thread2 by a moment. And let's say Thread1 (by the way, the fun part about analyzing race conditions is that nearly anything can happen - so you can say "Let's say" all darn day long and you'll probably be right!) gets to line 10 and stops. Thats right, after executing line 9, Thread1 gets kicked out of the (proverbial) CPU.
1: // Transfer method in java.util.HashMap -
2: // called to resize the hashmap
3:
4: for (int j = 0; j < src.length; j++) {
5: Entry<k,v> e = src[j];
6: if (e != null) {
7: src[j] = null;
8: do {
9: Entry<k,v> next = e.next;
// Thread1 STOPS RIGHT HERE
10: int i = indexFor(e.hash, newCapacity);
11: e.next = newTable[i];
12: newTable[i] = e;
13: e = next;
14: } while (e != null);
15: }
16: }
Since it passed line 9, Thread1 did get to set its e and next variables. The situation looks like this (I've renamed e and next to e1 and next1 to keep them straight between the two threads as both threads have their own e and next).

Again, Thread1 didn't actually get to move any nodes (by this time in the code, it did allocate a new bucket array).
What happens next? Thread2, that's what. Luckily, what Thread2 does is simple - let's say it runs through the full resize. All the way. It completes.
We get this:

Note that e1 and next1 still point to the same nodes. But those nodes got shuffled around. And most importantly the next relation got reversed.
That is, when Thread1 started, it had node A with its next as node B. Now, its the opposite, node B has its next as node A.
Sadly (and paramount to the plot of this story) is that Thread1 doesn't know that. If you're thinking that the invertedness of Thread1's e1 and next1 are important, you're right.
Here's Thread1's next few iterations. We start with Thread2's bucket picture because thats really the correct "next" relations for our nodes now.



Everything sort of looking ok.. except for our e and next at this point. The next iteration will plunk A into the front of the bucket 3 list (it is after all, next). And will assign its next to whatever happens to already be there - that is, node B.

Woah. Thar she blows.
So right about now Thread1 goes into, what we like to call in the biz, an "infinite loop". Any subsequent get operations that hit this bucket start searching down the list and, go into, yep - an infinite loop. Any put operation that first needs to scan the nodes to see if its going to do a replace, will, you guessed it, go into an infinite loop. Basically, this map is a pit of infinite loopeness.
If you remember we noted that race conditions cause data corruption. Well, yeah, thats what we have here - just very unlucky data corruption on pointer structures. I'm the first to admit this stuff is tricky - if you found errors in my analysis I'll happily fix this post.
Now I had the happy fortune for a time of sharing an office with Josh Bloch who wrote java.util.HashMap. When I innocently mentioned he had a bug in his code given this behavior, he did indeed (to use Josh's word's) go non-linear on me.
And he was right. This is not a bug. HashMap is built specifically for its purpose and this implementation is not intended as threadsafe. There's a gaggle of ways to make it threadsafe, but in plain, vanilla, (and very fast) form - its not. And needless to say, you shouldn't be using it that way.
Race conditions are nothing to mess with and the worst ones are the ones that don't crash your program but let it wander down some unintended path. Synchronization isn't just for fun you know.
And nefarious uses of HashMap aside, I still attest - this is, indeed, a beautiful race.
Addendum: I've been yelled at a few times for calling any race condition "beautiful". I'll defend myself by our apparently human nature to generally call intricate complexity beautiful (i.e. waves crashing on a shore, nature in general).
Most races end up being about data-corruption. This one is data-corruption that manifests as control-flow-corruption. And it does so fantastically without an error (infinite loops notwithstanding).
As the evolution analogy goes, if you drive a needle into a pocket watch - chances are you'll simply destroy it. But there's a tiny chance you'll actually make it a better watch (clearly, not the case here). And another tiny chance you'll simply make it something "different" - but still, per se, functioning.
Again, my use of "beautiful" might be more appropriate as "a complex mutation with surprising non-destruction" :)