获取html片段可以用来做什么?
可以用来分割,也可以分析HTML文档
beautifulsoup用法?
安装beautifulsoup库: pip install beautifulsoup4
因为bs里面缺省的库对html的兼容性不够,还要安装一个库来实现: pip install html5lib
下面附上bs1.html代码截图:
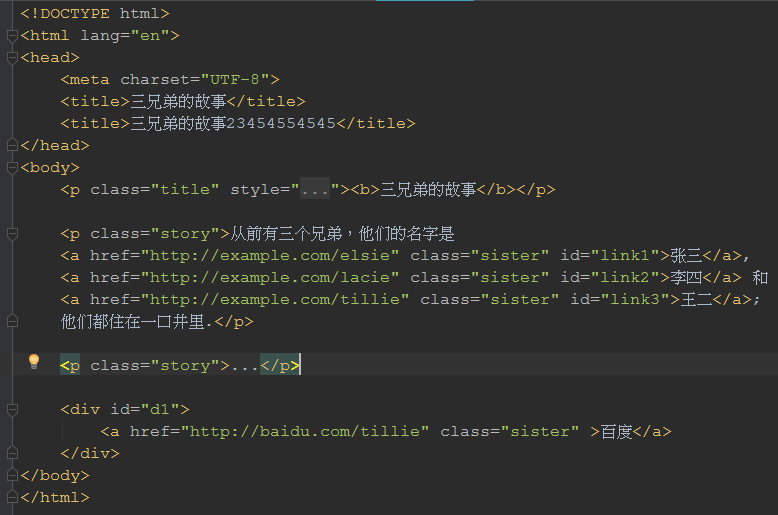
通过代码实现:
# BS操作对象是字符串,假设要对某个html文本作分析,就要先将文本的字符串读出来。
with open('bs.html',encoding='utf8') as f:
html_doc = f.read()
# 导入相关库,html5lib不用导入,BS会自动引用
from bs4 import BeautifulSoup
# 指定用HTML5lib来解析文档
soup = BeautifulSoup(html.doc, 'html5lib') # 第一个参数是要解析的文本,第二个参数指定是用htmllib库来解析的
# print(soup.title) # 打印出第一个title的内容
# print(soup.find('title'))
# print(soup.title.name) # 获取标签名
# 获取tag(标签)文本内容
# print(soup.title.string)
# 也可以:
# print(soup.title.get_text())
# 如果要获取tag的父节点tag
# print(soup.title.parent)
# print(soup.title.parent.name)
# 如果要获取元素的属性值
# print(soup.div['id'])
# print(soup.p['style'])
# print(soup.a) 只找到第一个标签
# print(soup.find_all('a')) 找到所有的a标签
# print(soup.find_all('a')[1]) 找到第二个a标签 根据下标
# print(soup.find('a', id='link1')) 根据id属性来查找相应的a标签
# print(soup.find('a', href='http://example.com/lacie')) # 根据超链接来查找相应的a标签
webdriver提供的八种基本元素定位:
通过id属性选择元素:find_element_by_id()
通过name属性选择元素:find_element_by_name()
通过classs属性选择元素:find_element_by_class_name()
通过tag(标签)属性选择元素:find_element_by_tag_name()
通过link选择元素:find_element_by_link_text()
通过partial_link(模糊匹配的方式)定位:find_element_by_partial_link_text()
通过xpath选择元素:find_element_by_xpath()
通过css选择元素:find_element_by_css_selector()