逃离数学焦虑、算法选择,思考做好机器学习项目的3个核心问题 - 机器学习算法与Python学习
- https://mp.weixin.qq.com/s/qNC-KEOQLxAqBO3-oUfM2g
- 当我们做一个机器学习项目时,不纠结于各个模型算法的内部细节,从整体的角度看具体问题该如何更可靠更高效得出结论,才不至于浪费更多的时间。从对数学的焦虑中,众多算法的选择中抽身出来, 去思考以下几个问题:
- 我们如何在项目中选择更为合适的算法?
- 选择算法之后,如何知道我们的模型是更有用的或更好的?
- 如何进一步优化模型以达到更理想的效果?
- 选择合适的算法
- 针对具体的问题选择不同的算法。
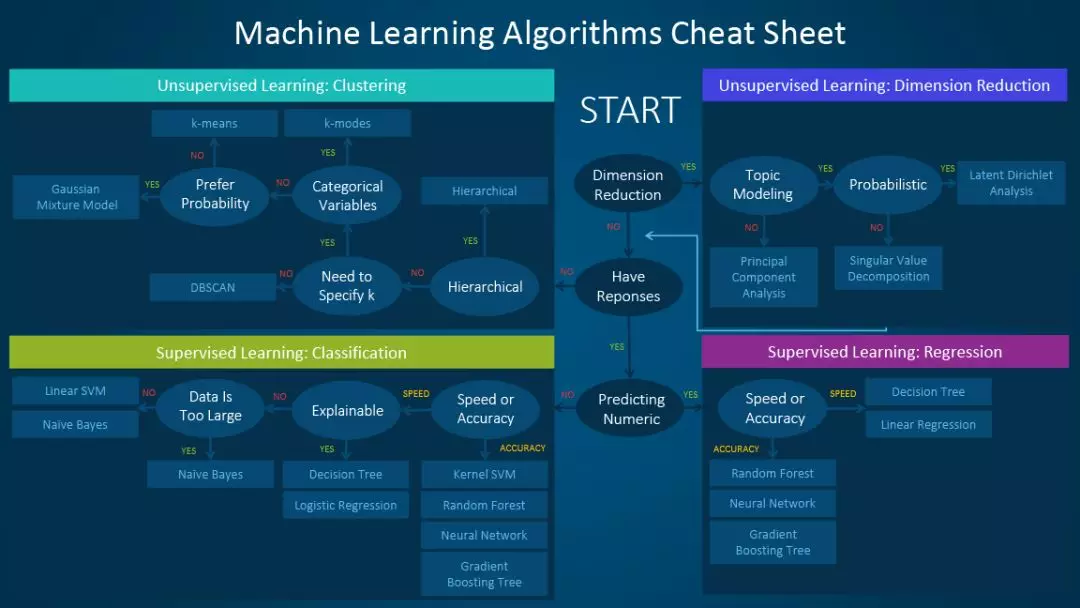
- 第一步,明确具体问题
- 有监督学习主要有回归和分类任务:
- 回归是研究因变量与自变量之间关系的方法。
- 分类将数据集按照不同的特点分为不同的类别。
- 无监督学习主要有聚类和降维任务:
- 聚类将数据集分为多个类似的对象组成的多个类。
- 降维的基本原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而降低了原数据集的维度,同时又能尽量减少数据信息的丢失。
- 有监督学习主要有回归和分类任务:
- 第二步,选择算法
- 你可以很快速的浏览每个算法的核心及应用,在面对实际问题时做出大致的判断。
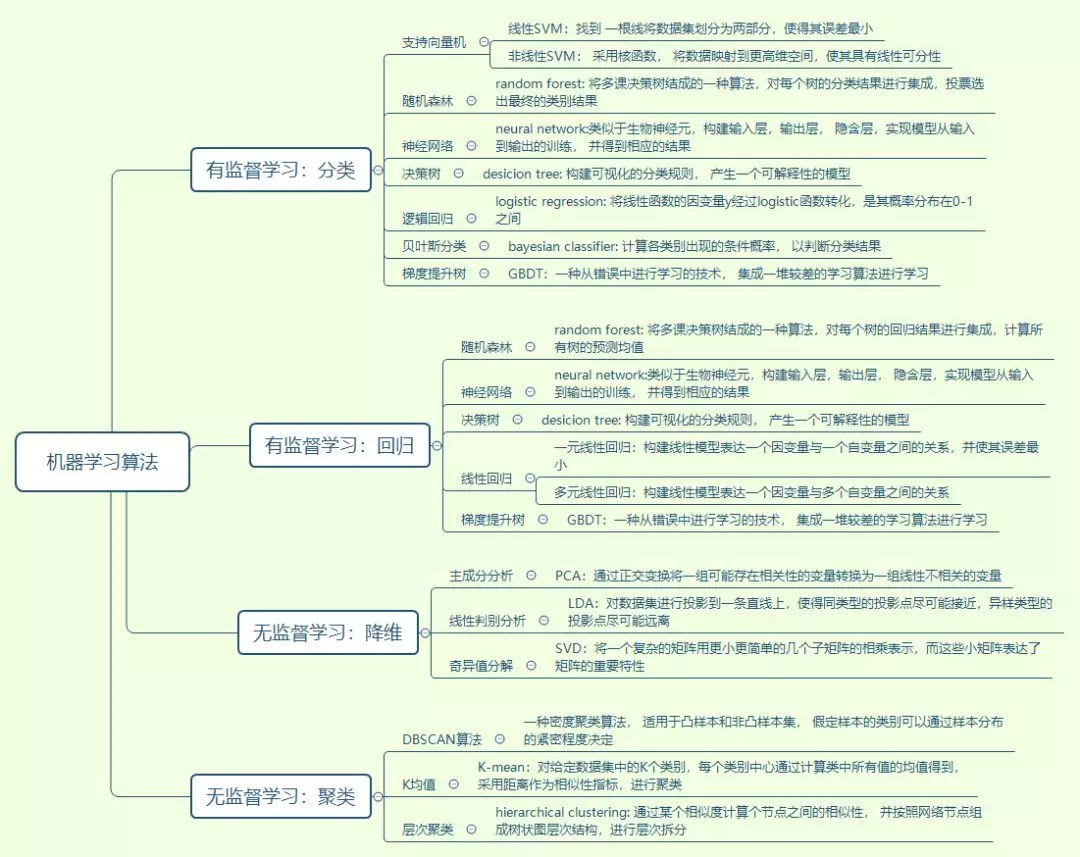
- 但需要注意的是,我们已经针对算法模型有一个初步的定位,在实践过程中仍然需要将实际数据与模型结合考虑。
- 模型评估
- 过拟合与欠拟合
- 欠拟合和过拟合都是模型泛化能力不高的表现。
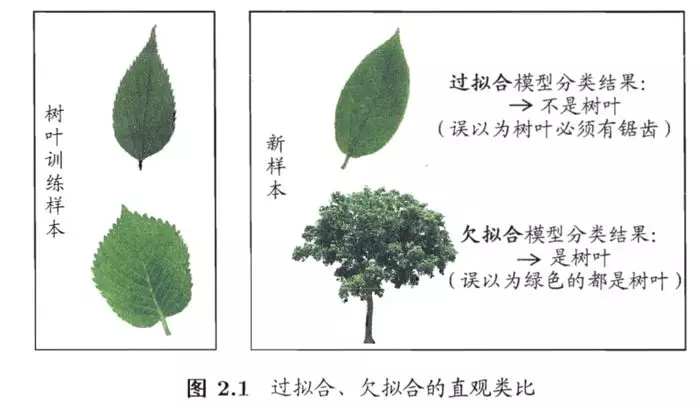
- 由此,需要构建评估模型来评估模型的泛化能力,这是检验一个模型是否更为有效的方法。
- 评估方法
- 常见的模型评估方法有留出法,k折交叉验证法和自助法:

- 过拟合与欠拟合
- 优化模型
- 评估模型的泛化能力评估,当模型的应用不理想时,我们应该如何优化模型?
- 学习曲线
- 考虑使用学习曲线来判断模型的过拟合问题。

- 优化模型
- 基于上文,当模型出现过拟合或欠拟合时,可从以下几个方面考虑:
- 1. 数据量的多少。较少的数据量更容易过拟合,增大数据量对过拟合是有效的。
- 2. 增加或减少特征量。特征值较少会影响模型对样本数据的认识,导致欠拟合,增加特征值对欠拟合时有效的。
- 3. 增加或减少正则化。正则化的使用对过拟合是有效的。
-

- 基于上文,当模型出现过拟合或欠拟合时,可从以下几个方面考虑: