MongoDB的产生背景是在大数据环境,所谓的大数据实际上也就是进行数据信息的收集汇总。必须要有信息的统计操作,
而这样的拥挤操作就是聚合(分组统计就是一种聚合操作)。
1、取得集合的数据量 :对于聚合的数据浪而言,在MongoDB里面直接使用count()函数就可以完成。
(01)、范例:统计students表中的数据量 => db.students.count();
(02)、范例:模糊查询 => db.students.count({"name":/张/i});
在进行信息查询的时候,不设置条件永远要比设置条件的查询快很多,无论是全部查询还是模糊查询,
实际上都是模糊查询一种(没有设置关键字);
2、group操作
(01)、使用“group”操作可以实现数据的分组操作,在MongoDB里面会将集合一句指定的key的不同进行分组操作,
且每一个组都会产生一个处理的文档结果。
3、MapReduce
(01)、MapReduce是整个大数据的精髓所在(实际中别用),所谓的MapRuduce就是分为两步处理数据
|- Map:将数据分别取出
|- Reduce:负责数据的最后处理
可是要是想在MongoDB里面实现MapReduce处理,那么复杂度相当高。
(02)、范例:建立一组雇员数据
使用MapReduce最终会将处理结果保存一个单独的集合里面。
(03)、范例:按照职位分组,取得每个职位的人名 =>
|- 编写分组定义:
var jobMapFun = function(){ emit(this.job,this.name); }//按照job分组,取出name
//第一组:{key:"CLERK", value:[姓名,姓名....]}
|- 编写reduce操作:
var jobReduceFun = function(key,value){ return {"job":key, "names": value} }
|- 针对MapReduce处理完成的数据实际上也可以执行最后操作;
var jobFinalizeFun = function(key,value){ if(key=="PRESIDENT"){ return {"job":key, "names": value,"info":"公司BOOS"}} return {"job":key, "names": value} }
|- 整合:db.runCommand({"mapreduce":"emps","map":jobMapFun ,"reduce":jobReduceFun ,"out":"t_job_emps","finalize":jobFinalizeFun });
执行之后,所有的处理结果都保存在了“t_job_emps”集合中;
(04)、范例:统计出各性别的人数、平均工资、最低工资、雇员姓名
var sexMapFun = function(){ //定义好了分组的条件,以及每个集合要取出的内容 emit(this.sex, {"ccount": 1,"csvg": this.salary,"cmax": this.salary,"cmin": this.salary,"cnames": this.name}); } var sexReduceFun = function(key, values){ var total = 0 ;//统计 var sum = 0;//计算总工资 var max = values[0].cmax;//假设第一个数据是最高工资 var min = values[0].cmin;//假设第一个数据是最低工资 var names = new Arrary();//定义数组内容 for(var x in values){ //表示循环取出里面的数据 total + values[x].count; //人数增加 sum += values[x].csal; //循环取出所有的工资,累加 if(max < values[x].cmax){ //不是最高工资 max = values[x].cmax; } if(min < values[x].cmin){ //不是最低工资 min = values[x].cmin; } names[x] = values[x].cname;//保存姓名 } var avg = (sum/total).toFixed(2); return {"count": total,"avg": avg,"max": max,"min": min,"names": names}; } db.runCommand({ "mapreduce": "emps", "map":sexMapFun, "reduce":sexReduceFun, "out": "t_sex_emps" });
4、聚合框架 $group
(01)、MapReduce功能强大,但是复杂度高。所以从Mongo 2.x版本之后开始引入了聚合框架并且提供了聚合函数;
(02)、group 主要进行分组的数据操作
范例:实现聚合查询的功能 -- 求出每个职位的雇员人数 => db.emps.aggregate([{"$group": {"_id:"$job", job_count:{"$sum":1}}}]);
这样操作更加复合于传统group by 子句的操作使用;
范例:求出每个职位的总工资 => db.emps.aggregate([{"$group": {"_id:"$job", job_sal:{"$sum":"$salary"}}]);
在整个聚合框架里面要引用每行的数据使用:“$字段名称”
范例:计算出每个职位的平均工资 => db.emps.aggregate([{"$group": {"_id":"$job", "max_sal":{"$max":"$salary"}, "min_sal":{"$min":"$salary"}}}]);
范例:计算出每个职位的工资数据$push(数组显示) => db.emps.aggregate([{"$group": {"_id": "$job", "sal_data": {"$push":"$salary"}}}]);
范例:取消重复数据 =>$addToset db.emps.aggregate([{"$group": {"_id": "$job", "sal_data": {"$addToset":"$name"}}}]);
范例:取出第一个和最后一个数据$frist和$last => db.emps.aggregate([{"$group": {"_id": "$job", "sal_data": {"$frist":"$salary"}}}]);
*注:虽然可以方便的实现分组处理,但是有一点需要注意,所有的分组数据是无序的,并且都在内存中完成,不可能支持大数据量。
5、$project
(01)、控制数据列的显示规则:
|- 普通列({成员:1|true}):表示要显示的内容;
|- “_id”列({"_id"}: 0|false):表示id是否显示
|- 条件过滤列({成员:表达式}):满足表达式之后的数据可以进行显示。
(02)、范例:只显示name、job列,不显示"_id"列 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1}}]);//0不显示,1显示
起别名 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "职位": "$job", "salary": 1}}]);
此时只有设置进去的列才可以被显示出来,而其他的列不显示。实际上就是数据库的投影机制。
*实际上在进行数据投影的过程里面也支持四则运算:加($add)、减($subtract)、乘($multiply)、除($divide)
(03)、范例:计算年薪 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "job": "$job", "salary": {"年薪": {"$multiply": ["$salary", 12]}}}}]);
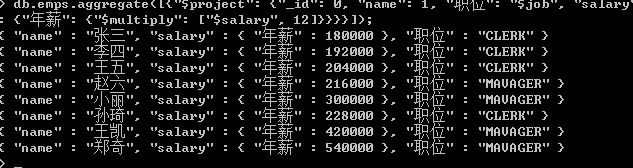
(04)、除了四则运算也还支持各种运算符:
|- 关系运算:大小比较($cmp)、等于($eq)、大于($gt)、大于等于($gte)、小于($lt)、小于等于($lte)、
不等于($ne)、判断null($ifNull):这些结果返回的都是布尔型数据
|- 逻辑运算:与($and)、或($or)、非($not)
|- 字符串操作:连接($concat)、截取($substr)、转小写($toLower)、转大写($toUpper)、不区分大小写($strcasecmp)
(05)、范例:查询工资大于15000的员工 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "job": "$job", "salary": {"$gt": ["$salary", 15000]}}]);
(06)、范例:使用字符串截取 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "job": "$job", "job": {"$substr": ["$job",0,3]}}}]);
(07)、通过一系列的延时可以总结一点:
|- “$project”:相当于SELECT子句
|- “$match”:相当于WHERE子句
|- “$group”:相当于CROUP BY 子句
6、$sort
(01)、使用“$sort”可以实现排序,设置 1 表示升序, 设置 -1 表示降序
(02)、范例:排序 => db.emps.aggregate([{"$sort": {"age": -1, "salary": 1}}]);
7、分页处理 $limit(负责数据的取出个数)、$skip(数据的跨过个数)
(01)、范例跨过一行取出一行(只能先跨再取)=> db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "job": "$job", "salary": 1},{"$skip": 1},{"$limit": 1}]);
8、$unwind
(01)、在查询数据的时候经常会返回数组信息,但是数组并不方便信息的浏览,所以提供有为独立的字符串的内容。
(02)、范例:添加一些信息
db.detps.insert({"title":"技术部","bus":["研发","生产","培训"]});
db.detps.insert({"title":"财务部","bus":["工资","税收"]});
将信息进行转化 => db.detps.aggregate([{"$project": {"_id": 0, "title": 1, "bus": 1}},{"$unwind": "$bus"}]);

9、$geoNear: 使用$geoNear 可获得附近的坐标点
10、$out
(01)、“$out”:利用此操作可以查询结果输出到指定的集合里面
(02)、范例:将投影的结果输出到集合里 => db.emps.aggregate([{"$project": {"_id": 0, "name": 1, "job": "$job", "salary": 1},{"$out":"emp_infos"}]);