inception发展历程
v1

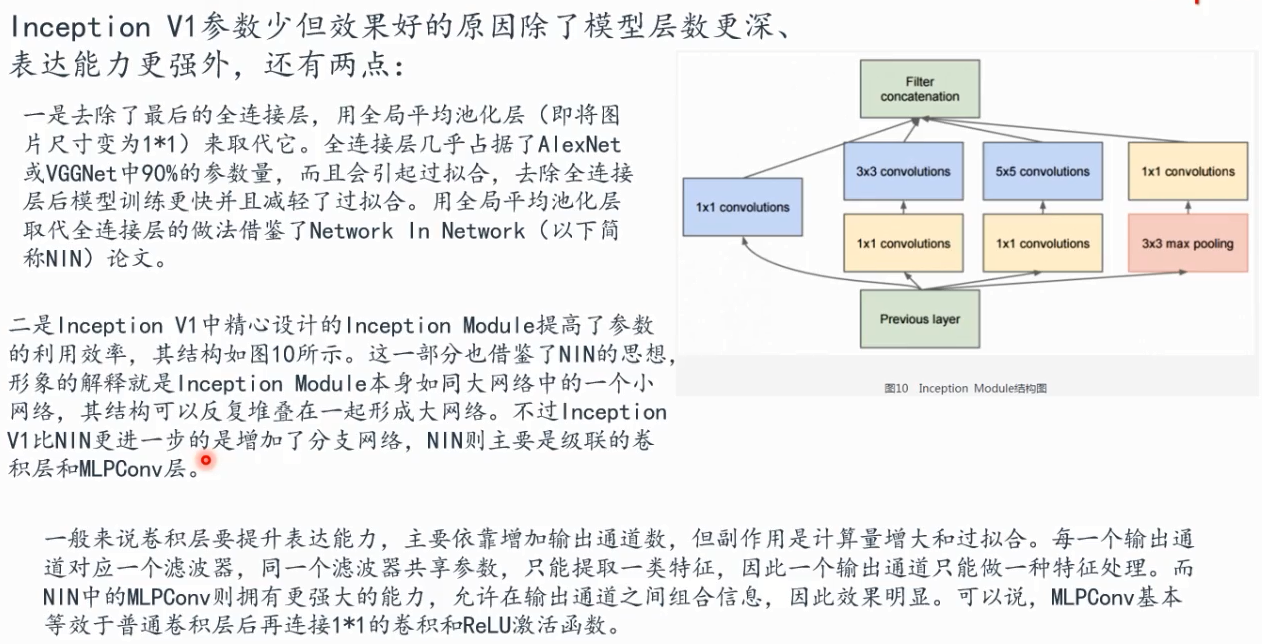
mlp多层感知器层




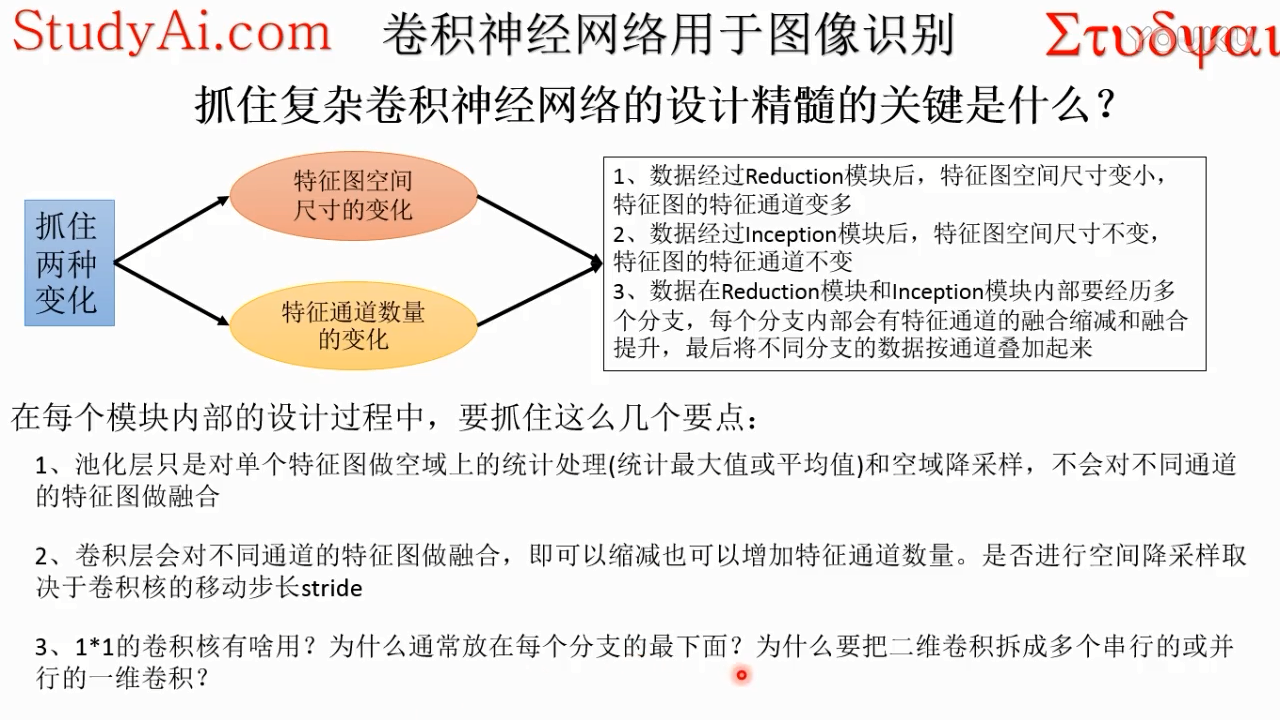
上面两个观看孔径,尺寸不一样,可以抽取不同分辨率,不同尺度的邻域范围的信息作为特征,这样就可以观察到输入数据的不同层次,不同分辨率的特征
因为这个1*1完了之后,就是做完内积以后,就在那一个点上,它是每个通道那一个点上做完内积,把所有通道的内积加起来,之后非线性激活函数,这里的conv里面都包含relu。
1*1卷积所连接的相关性是最高的,因为卷积核扩大以后呢,3*3他在不同通道的位置,可能会变得不一样,相关性就会减弱

v2:

传统的神经网络训练的时候,每一层输入的分布都在变化,就是网络的这个不同输入的分布,在不同的迭代过程中,变化特别剧烈,总是稳定不下来,这样就没法收敛,只能使用比较小的学习率,让他慢慢变化
V3:
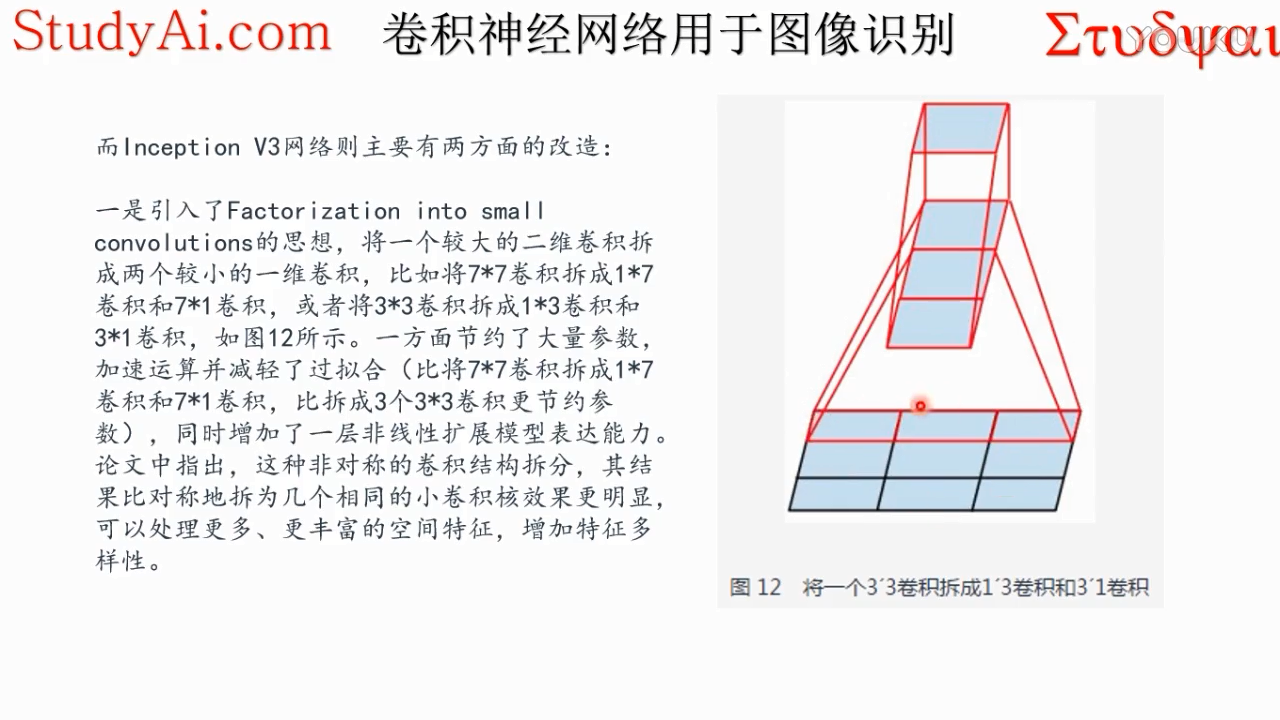
最后用3*1的卷积核与1*3卷积之后的内容进行内积,可以处理更多、更丰富的空间特征,增加特征多样性
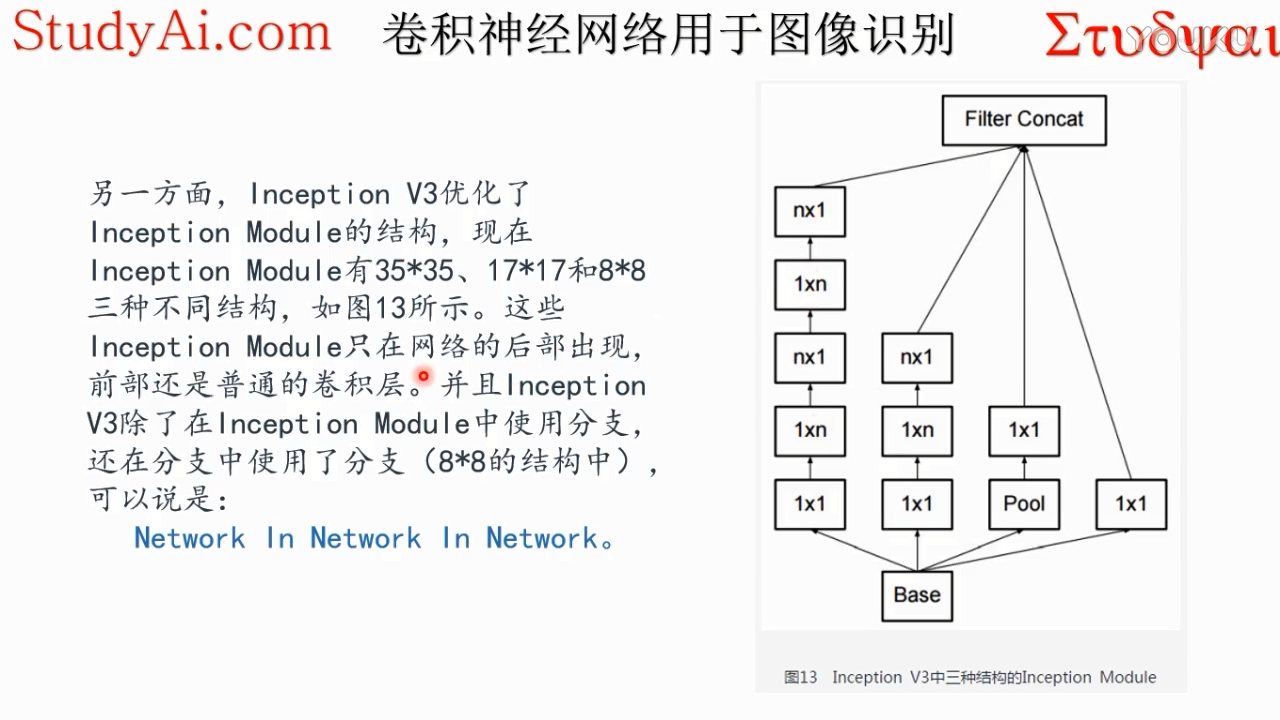
inception v3 详解:
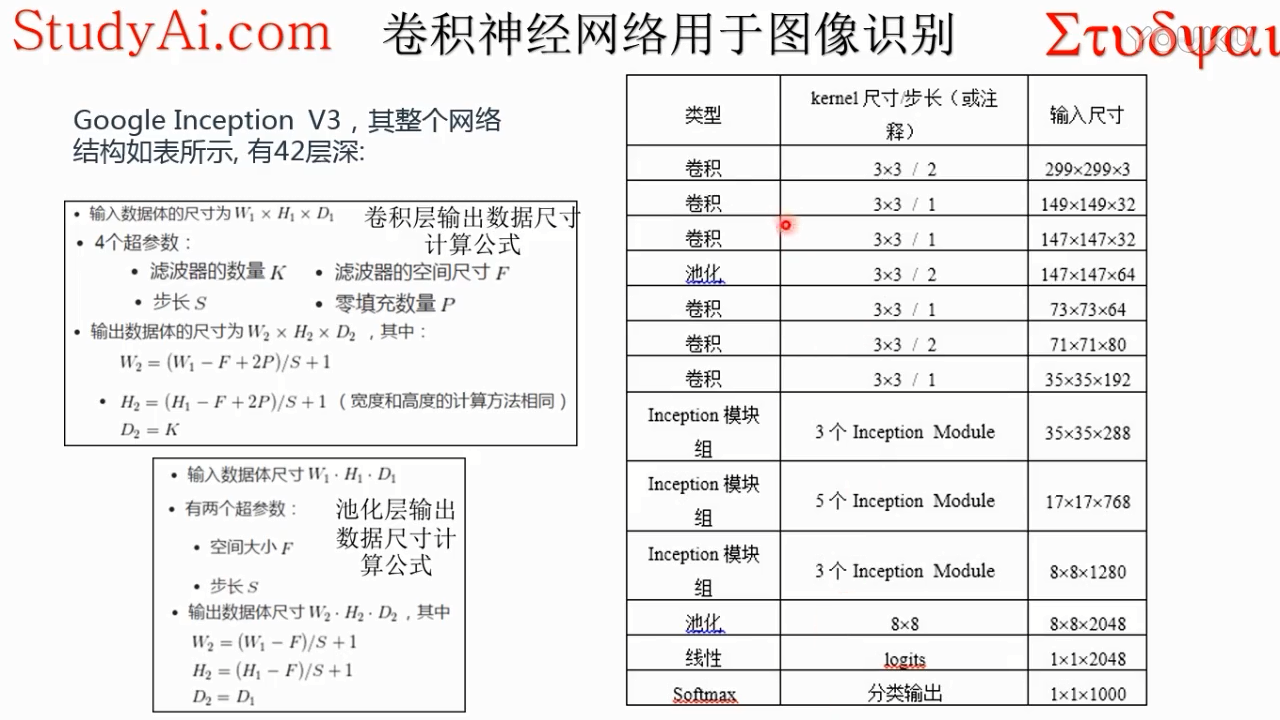

要想卷积不改变空间尺寸(图像大小,不是通道数),必须要pad=kernelsize÷2(去掉余数)!!!
pad=0,卷积后空间尺寸会变小。
最后提取出了2048个特征,输入到线性输出层1000个units(相当于一个分类器,有1000个类),得到它属于1000个类的得分

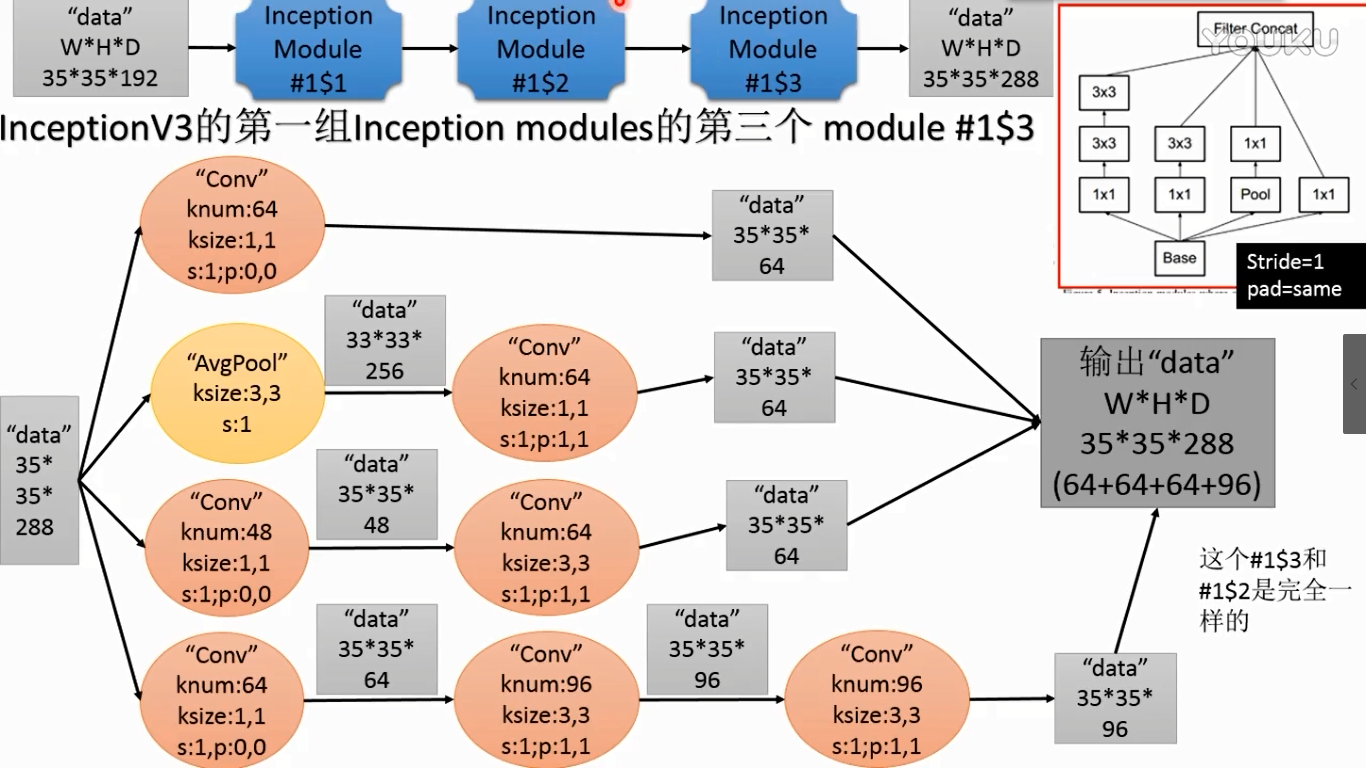
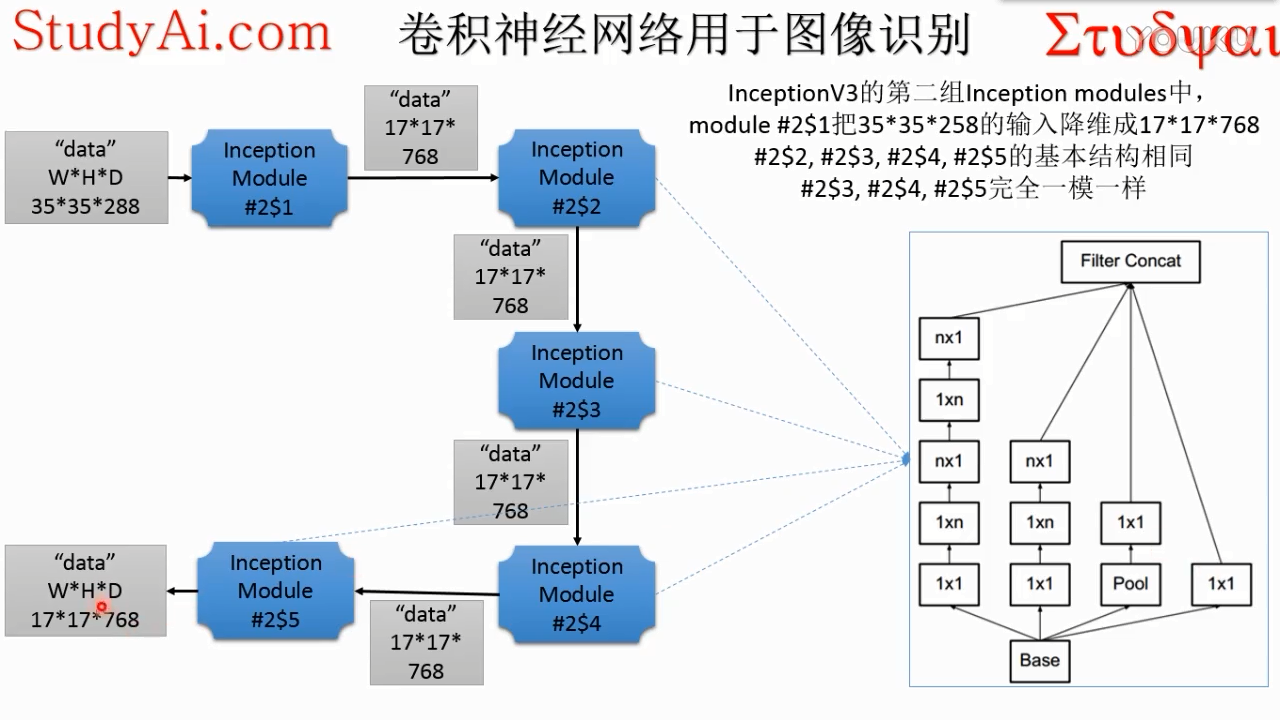
注意第三个inception module 有3个模块,其中第二个和第三个相同。第二个module输出和第三个Module尺寸不一样,所以中间加了一个,所以是三个
线性logits是逻辑回归(线性分类),将这2048个特征进行逻辑回归,得到的是属于每个类的得分,最后soft是归一化概率
inception v3第一组modules
(1)
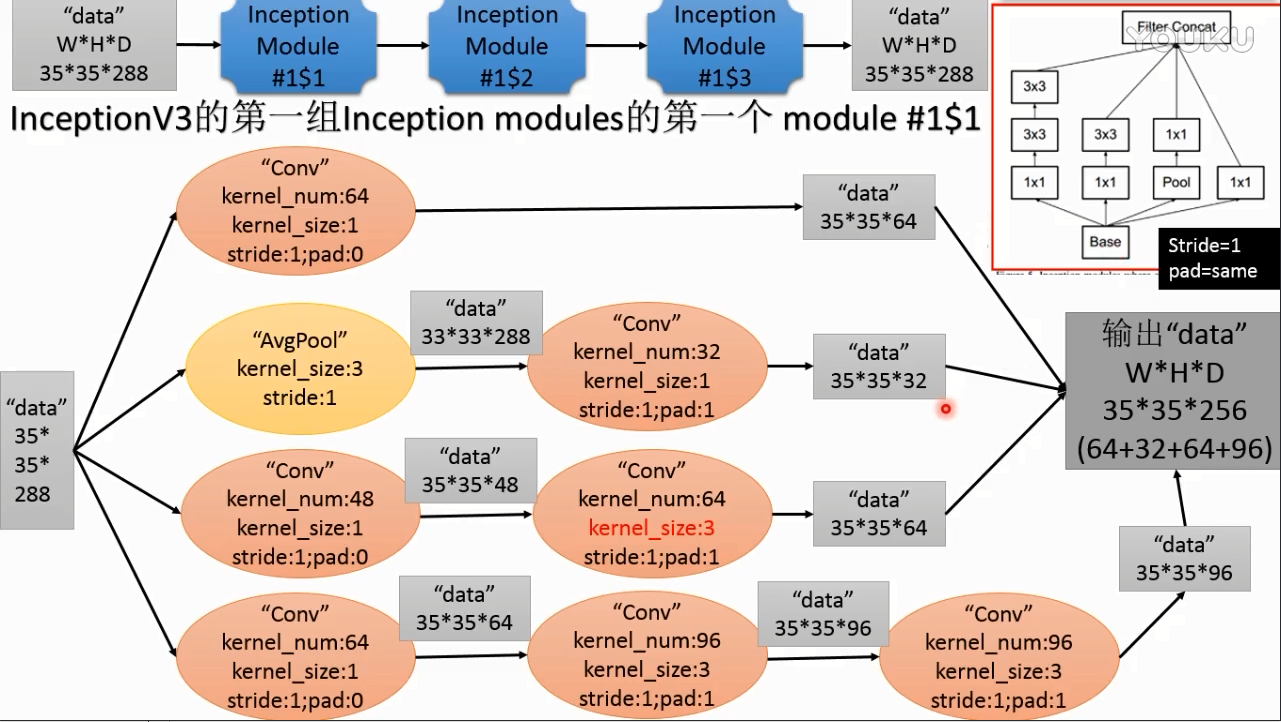
pad=same(在tensorflow中他会自己推导出来得到相同的尺寸,最后摞起来)
5*5替换成了3*3
(2)
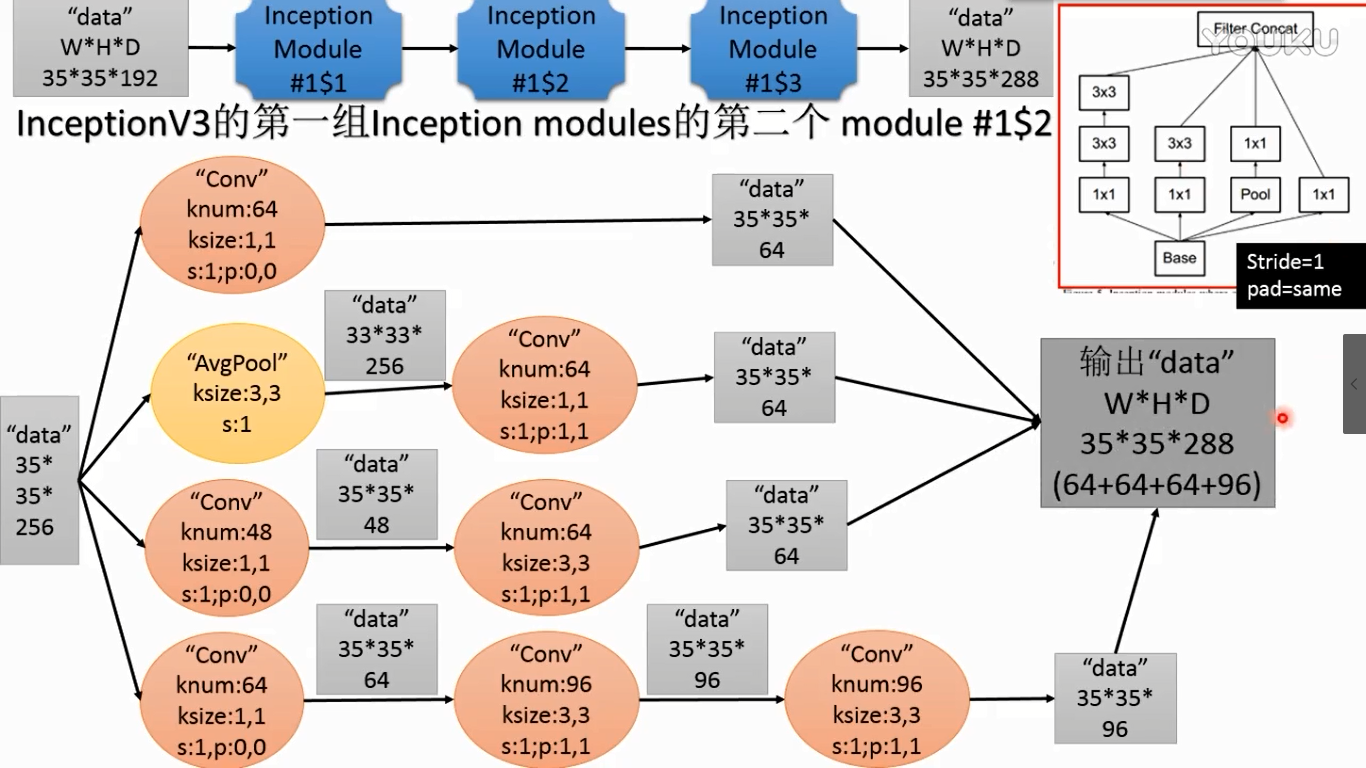
(3)
inception v3第二组modules
(1)
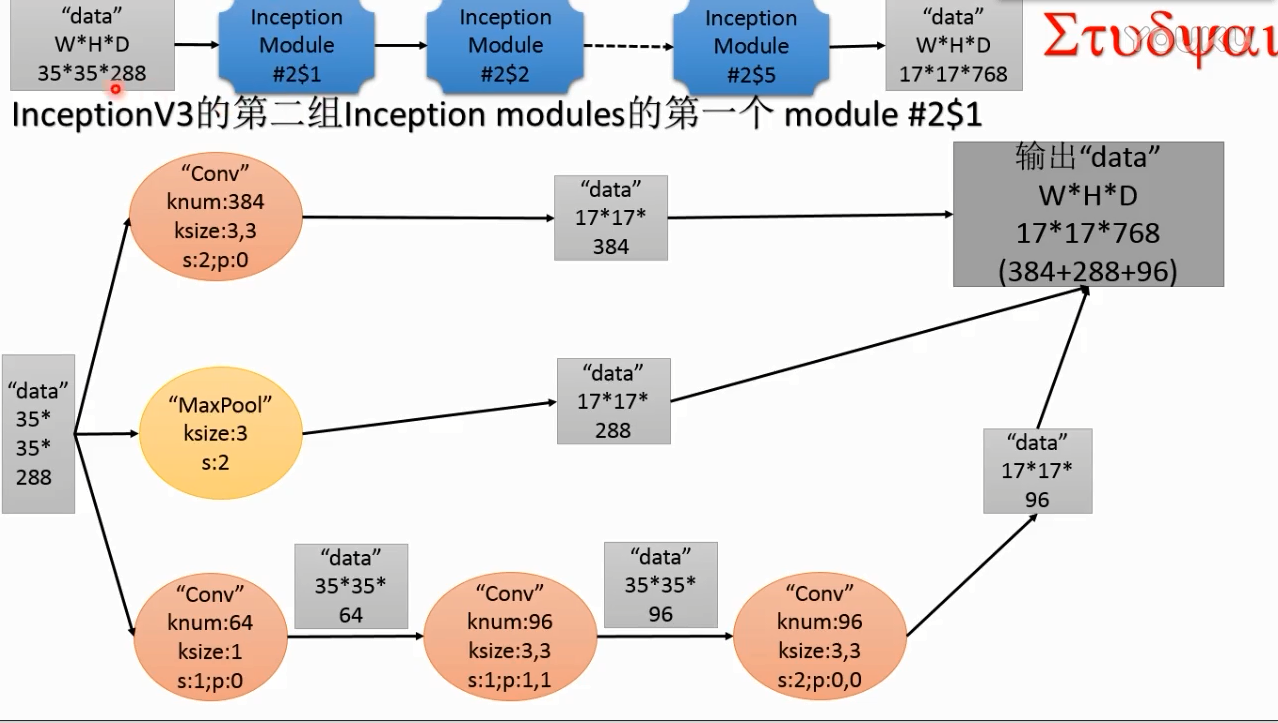
(2)

(3)
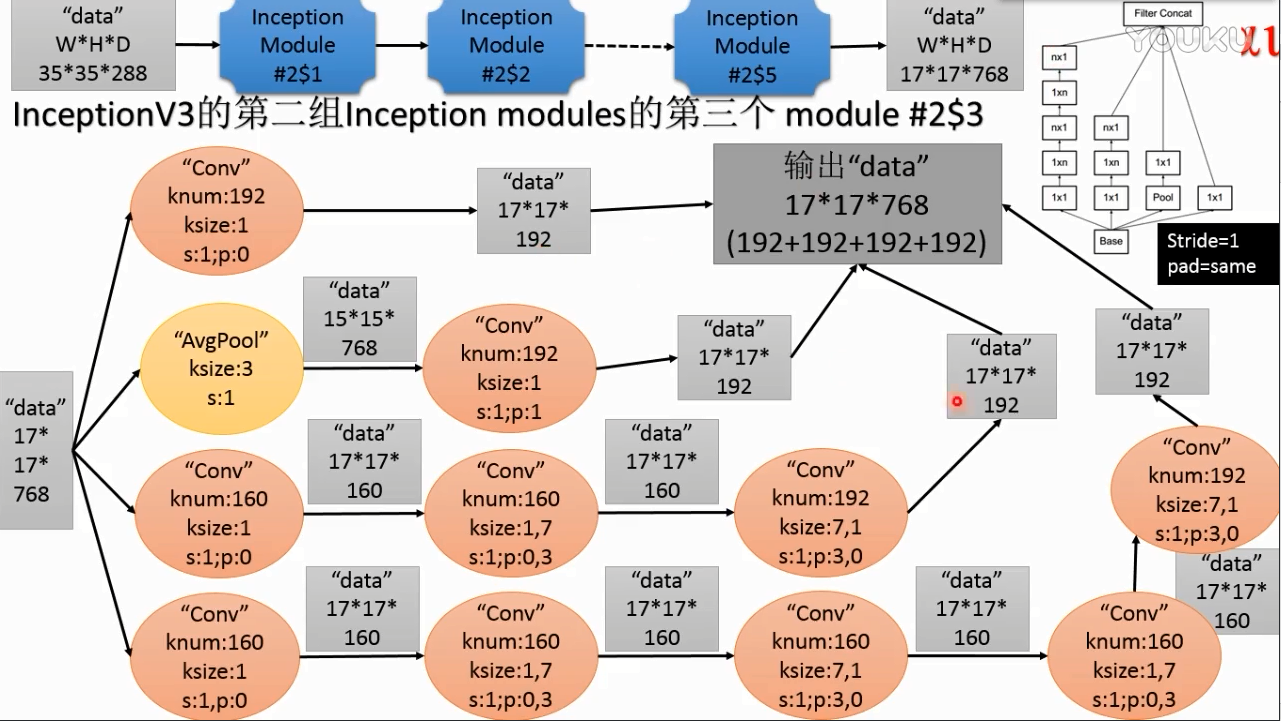
(4)
这个既不改变空间分辨率(空间尺寸),又不改变特征通道数,作用是把不同通道的特征融合起来。
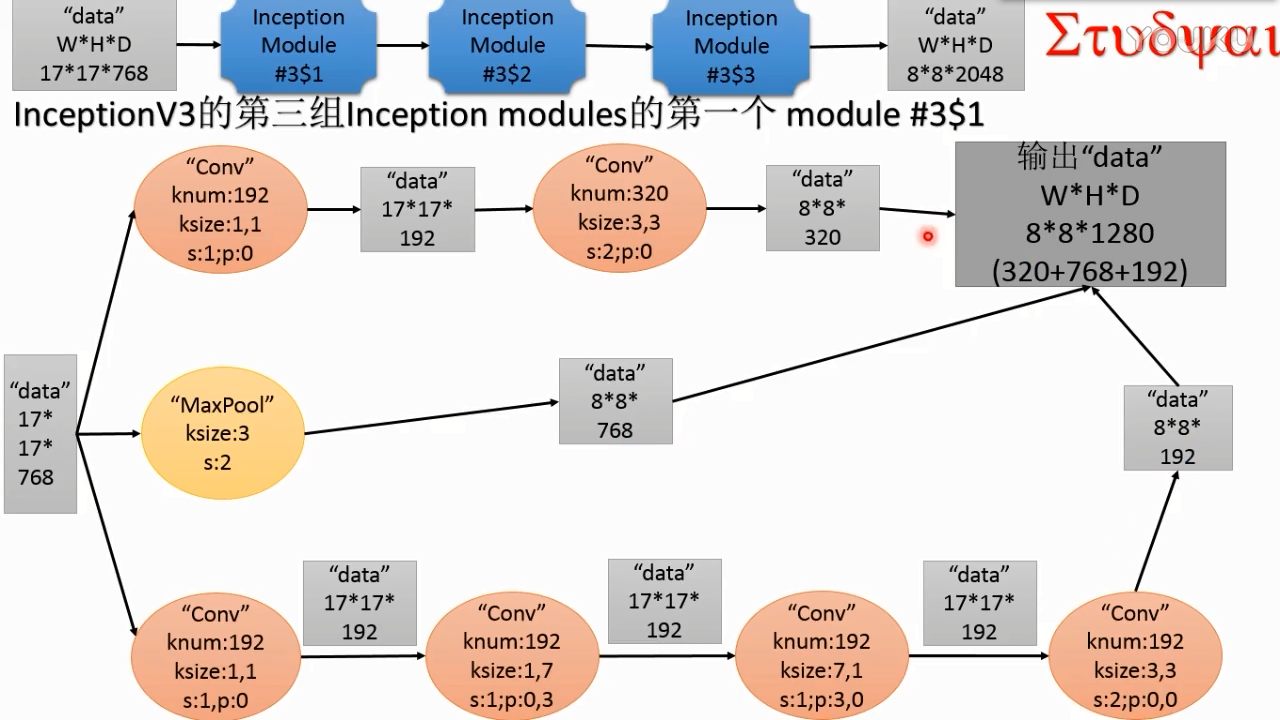
inception v3第三组modules
(1)
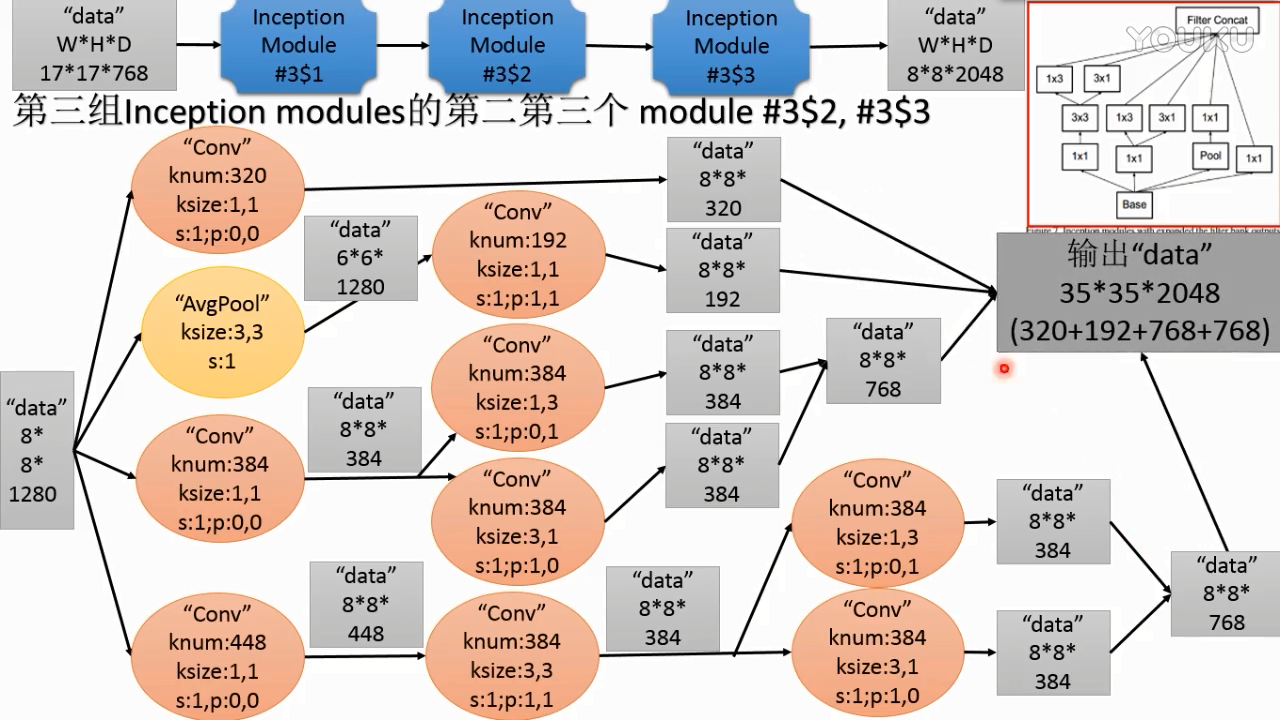
(2)
注:图中输出data 应该是 8*8*2048
inception v4

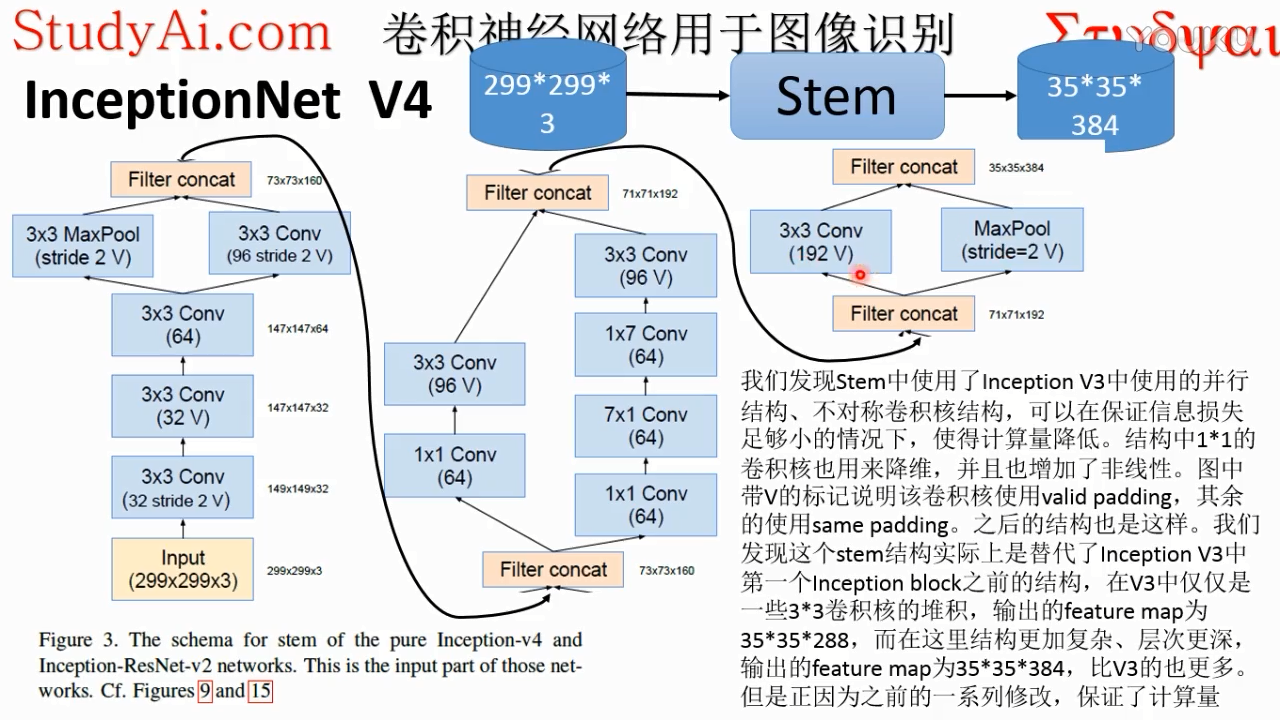
valid padding:pad=0,s默认为1
same padding:保证输入输出图像尺寸不变,默认pad=1,s=1
pool不改变通道数
注:最后的192V = 192,stride=2 V

branch1:
pool只是单独处理每一个通道的特征图,不会对通道之间做相关处理。
avg:相当于对每一个小特征图做一个空间的平均处理,统计平均值,平均滤波,相当于变得模糊了
branch1是再模糊了以后的特征图上做的,模糊了之后会把噪音去掉,模糊了去掉噪声之后
注:这里的conv都默认再带relu
branch2:
branch1模糊了去掉噪音的时候,有可能吧图像的微弱的边缘信息也给去掉了,这样就保留不了图像精确地信息,这时候就折中,模糊不模糊都处理一下。这样既去除了噪音,也保留下来了不同细节的信息特征
branch3:
融合的意思是每一个神经元都会伸向下一个卷积层的不同通道的,不同通道做内积,再加起来

branch1:
保留了原始特征通道的信息
卷积层神经元深度就是kernelsize
每一个分支都是为了保留输入数据不同的信息

branch3 最上面的是 7*1conv

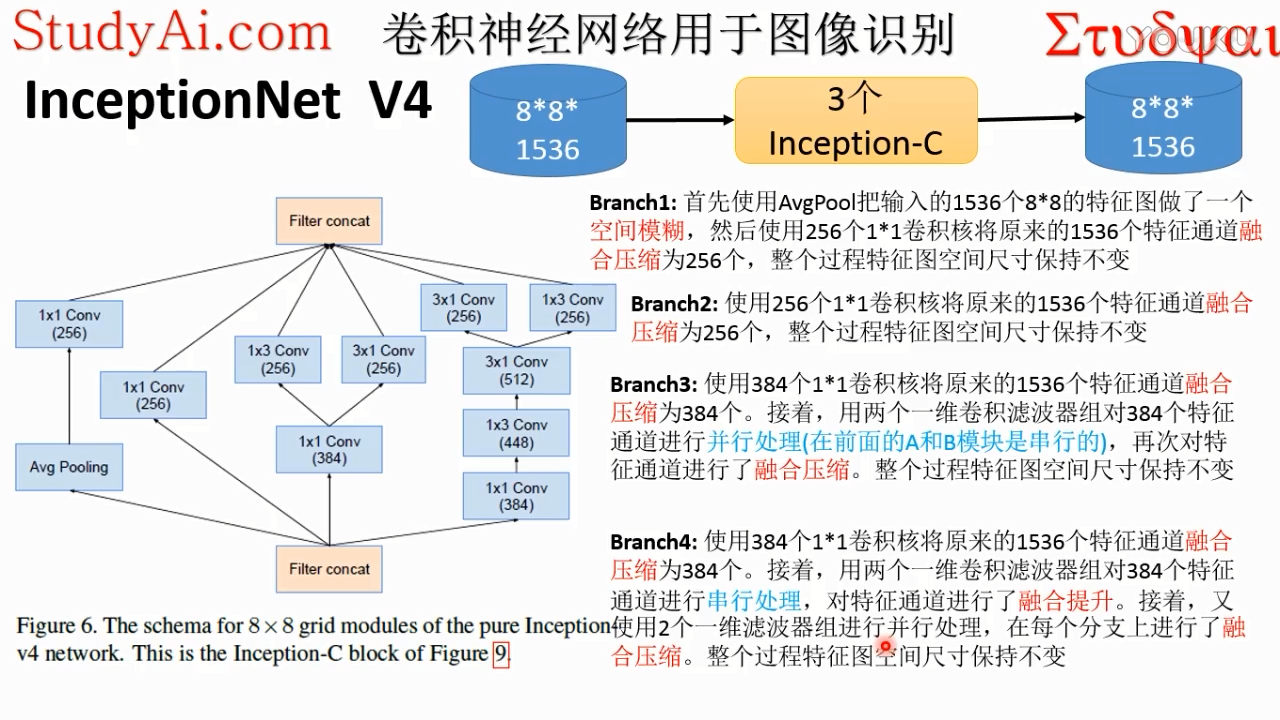
3*3变成了两个1*3和3*1的两个非线性映射过程,可以提取特征图不同的纹理进行变换,让特征图的特征更加丰富,更加抽象。
每个分支对特征提取的层次不一样
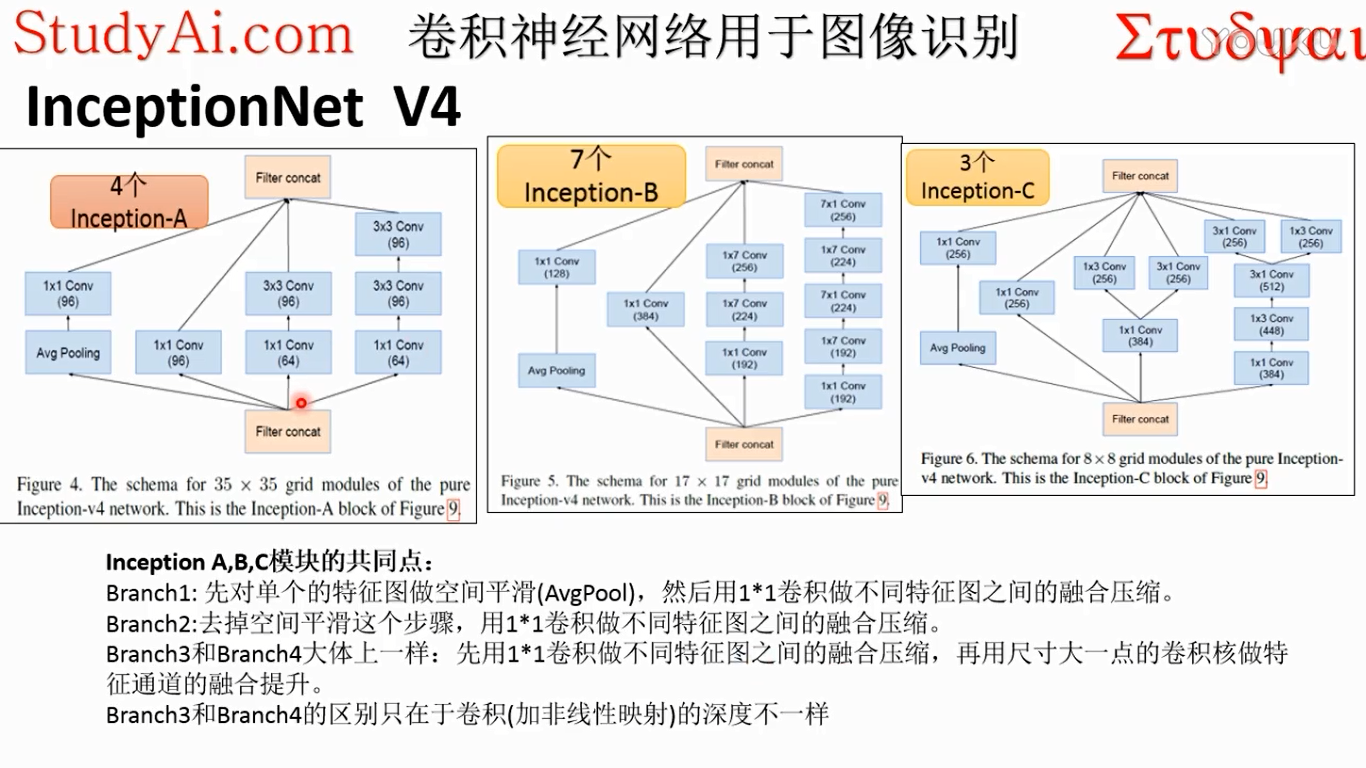
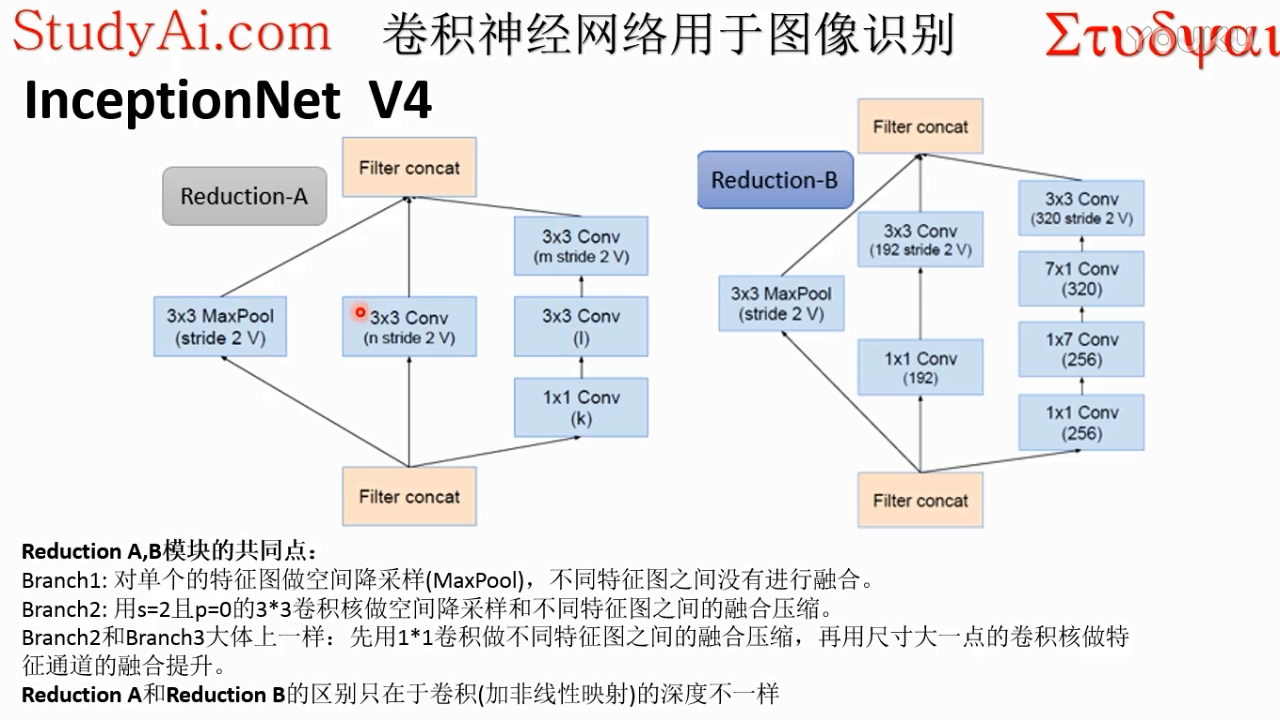
1*1的卷积核作为第一个抽象层级,为了增加抽象深度(非线性映射的深度)。
1*1卷积核的作用:
- 进行升维与降维并减少网络参数。关于其降维并减少网络参数的特点在GooLeNet中表现得一览无遗,详情可以参见GooLeNet,关于其升维并减少网络参数的功能在ResNet中使用得非常突出。关于详情可以参考http://www.caffecn.cn/?/question/136。
- 提升跨通道的信息整合与信息交互。我们知道,1*1的卷积核的每一个filter可以实现跨通道的信息通信,因此虽然是简单的线性组合,但是却丰富了信息的表现形式,因此有利于特征的提取。
发现很多网络使用1×1的卷积核,实际就是对输入的一个比例缩放,因为1×1卷积核只有一个参数,这个核在输入上滑动,就相当于给输入数据乘以一个系数。(对于单通道和单个卷积核而言这样理解是可以的)
对于多通道和多个卷积核的理解,1×1卷积核大概有两方面的作用:
1.实现跨通道的交互和信息整合(具有线性修正特性,实现多个feature
map的线性组合,可以实现feature map在通道个数上的变化,想象成跨通道的pooling,(输入的多通道的feature
map和一组卷积核做卷积求和得到一个输出的feature map)
2.进行卷积核通道数的降维和升维(同时还具有降维或者升维功能)
3.在pooling层后面加入的1×1的卷积也是降维,使得最终得到更为紧凑的结构,虽然有22层,但是参数数量却只是alexnet的1/12.
4.最近大热的MSRA的resnet也利用了1×1的卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,数量进一步减少。如果1×1卷积核接在普通的卷积层后面,配合激活函数,就可以实现network
in network的结构了。
5.还有一个很重要的功能,就是可以在保持feature
map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。(平均池化是针对每个feature
map的平均操作,没有通道间的交互,而1×1卷积是对通道的操作,在通道的维度上进行线性组合)