| 课程 | 软件工程1916|W(福州大学) |
| 作业要求 | 结对第一次—原型设计(文献摘要热词统计) |
| 结对学号 | 221600426 221600401 |
| 原型设计工具 | 墨刀 |
| 原型浏览 | 点击浏览 |
| 作业目标 | 了解《构建之法》中的NABCD模型,学习分析用户需求和设计原型 |
| 设计原型 | download |
| 博客PDF | download |
PSP表格
| PSP2.1 | Personal Software Process Stages |
| Planning | 计划 |
| Estimate | 估计这个任务需要多少时间 |
| Development | 开发 |
| Analysis | 需求分析 (包括学习新技术) |
| Design Spec | 生成设计文档 |
| Design Review | 设计复审 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) |
| Design | 具体设计 |
| Coding | 具体编码 |
| Code Review | 代码复审 |
| Test | 测试(自我测试,修改代码,提交修改) |
| Reporting | 报告 |
| Test Repor | 测试报告 |
| Size Measurement | 计算工作量 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 |
| 合计 |
NABCD模型
-
N(Need,需求)
1.用户可给定论文列表
- 通过论文列表,爬取论文的题目、摘要、关键词、原文链接
- 可对论文列表进行增删改操作(今年、近两年、近三年)
2.对爬取的信息进行结构化处理,分析top10个热门领域或热门研究方向
- 可对论文属性(oral、spotlight、poster)进行筛选及分析
- 形成如关键词图谱之类直观的查看方式
3 .可进行论文检索,当用户输入论文编号、题目、关键词等基本信息,分析返回相关的paper、source code、homepage等信息
4.可对多年间、不同顶会的热词呈现热度走势对比(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)
5.可进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等。
6.拓展功能
- 由于每个用户给定的论文不同,因此用户需要注册并登录系统,方可对用户进行唯一标识
- 用户可给出专业,爱好等信息-->系统给用户推荐论文和热门词汇
- 训练推荐模型

-
A(Approach,方法)
1.采用平台
- web:操作系统无关性,易于推广;PC可操作,方便用户处理查看数据。
2.功能分析
- 用户给定论文列表,对论文列表进行增删改操作
用户通过点击页面的单篇导入或者批量导入,选择文件对话框中的论文;导入后在网页显示已导入的所有论文的论文编号,论文名称,并在每篇论文后有一个删除论文按钮。
- 通过论文列表,爬取论文的题目、摘要、关键词、原文链接
对每一篇论文过滤出其题目,摘要,关键词,原文链接,并形成一个结构体存入数据库
-
论文数据处理
对所有论文中出现的关键词存入map,并记入其出现次数,根据关键词出现次数对数据进行排序,即可筛选出top10个热门领域或研究方向 -
用户可根据年份,属性,顶会类型筛选论文,并进行数据的分析展示
根据用户筛选的条件,选出匹配的论文在表格中展示其编号,题目。并对匹配出的论文进行国家,学校引用数的统计,即可得出哪个学校哪方面的研究方向比较强。对通过顶会类型筛选的论文进行热词统计,年份统计,对统计后的数据进行折线+条形图展现。对通过年份筛选出的论文进行热词统计,对统计后的数据进行饼状图展示每年的热词占比。 -
论文检索
用户选择输入论文编号或者论文题目或者关键词,在页面中展示搜索结果。 -
用户给出自己的专业,爱好,给用户推荐论文和热门方向
根据用户的专业,爱好,自动匹配论文库中的热词,对相似度进行排序,给用户推荐相关的论文和热门方向。并记入专业,爱好与论文推荐的对应关系,如此当数据达到一定规模时可以采用监督学习的方法来训练推荐模型,并进行迭代更新。 -
B(Benefit,好处)
- 1.由于采用web,移动端,pc端皆可使用,而且维护成本低,用户操作简便,易于推广。
- 2.用户进行登录验证,系统可以给用户进行唯一标识定位,方便对用户进行管理,以及推荐论文,并可留下拓展空间。
- 对论文分析数据进行模型训练,可以使本系统在使用过程中逐渐自我完善,推荐出更加符合用户的论文,更加人性化。
-
C(Competitors,竞争)
-
优势:
1.免费
2.基于web,适应性,可操作性,灵活性强
3.智能推荐,在使用过程中逐渐完善系统
4.界面简洁明了 -
劣势:
1.前期用户量少,可获取论文数量少,推荐功能无法得到完善
2.论文通过用户上传,或者自动爬取,存在版权问题
-
-
D(Delivery,推广)
-
线上:
1.借助大V,或者微信公众号
2.论文网站(万方,知网等)广告位租用 -
线下:
通过同学,老师等传播
-
结对过程
设计流程:
线上结对-->见面讨论规划模块,拟定草图-->开创墨刀项目团队,根据草图合作完成原型设计-->整理项目,编辑博客
设计草图:
登录,注册

论文,热词推荐
论文检索
导入论文,数据分析

结对成员讨论:

原型设计
- 登录,注册界面 :为了方便系统标识每个用户,并对用户进行智能推荐,以及后期扩展功能做准备


- 导入论文界面 :用户可通过点击单篇导入或者批量导入论文,并可在对应论文出进行修改或者删除

- 论文检索界面 :用户可点击下拉框选择通过论文编号或者论文题目或者关键词来检索论文

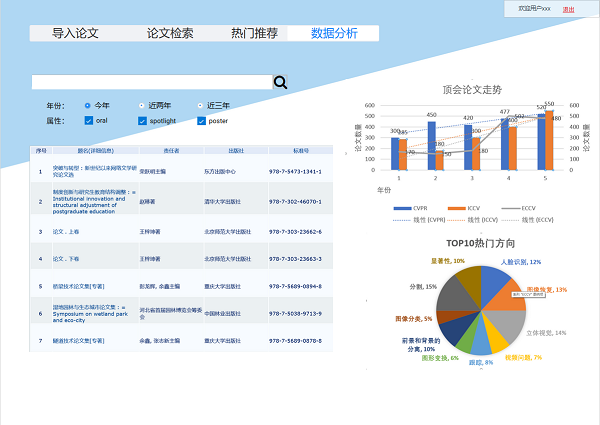
- 数据分析界面 :根据用户筛选的条件,选出匹配的论文在表格中展示其编号,题目。并对匹配出的论文进行国家,学校引用数的统计,即可得出哪个学校哪方面的研究方向比较强。对通过顶会类型筛选的论文进行热词统计,年份统计,对统计后的数据进行折线+条形图展现。对通过年份筛选出的论文进行热词统计,对统计后的数据进行饼状图展示每年的热词占比
- 推荐论文,热门方向页面 : 根据用户的专业,爱好,自动匹配论文库中的热词,对相似度进行排序,给用户推荐相关的论文和热门方向

遇到的困难及解决方法
-
1.墨刀工具初次使用,没有网页所需数据图等
解决方法 :对着教程边看对制作界面,自学Excel绘制图表 -
2.结对成员上课时间冲突,未能深入讨论设计方案
解决方法 :在双方都没课时,约个时间讨论简略的设计方案;然后更加细节处在开发过程中,通过墨刀团队合作实时共享设计,并用qq保持交流 -
3.对于需求分析中第5点“进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等”,未能很好的理解
解决方法:结对成员讨论出一种可能:对每篇论文,如果有国家录用则定义一个自增1的变量,学校录用同理;然后对每个学校录用论文中相同热词进行统计,对每个热词进行排序,即可得到每个学校每个研究方向的一个排序
结对心得
221600426
| 首先,此次任务能和小姐姐组队真是万分荣幸呢,在队伍中有个小姐姐,任务的完成效率,质量都能显著提高(相比自己曾经的开发经历,一群大老爷们总是会比较懒散)。再者,看到题目中有一个发挥想象的机会,结合我曾经开发过的一个短文本分析工具和当下比较流行的深度学习,我觉得“小樱”可能更需要的是一款通过她的专业,爱好等可以给它推荐热门和论文系统。最后,我本人审美水平经常被喷(其实我小学还是得过市儿童画二等奖,我个人比较喜欢色彩鲜艳,丰富),所以一直以来都不想去尝试UI设计,但这也算是一次UI设计的锻炼吧。 |
221600401
| 这次结对作业让我第一次接触了墨刀,也是第一次不用敲代码而是设计原型,我感觉先设计模型对之后代码实现确实是有很大帮助的。我在把教程全看了一遍后才正式与队友进行需求分析,我们经过讨论确定了需要的功能和界面个数,对每个界面的设计也参考了网上一些论文检索系统的界面,完善了许多排版的不足,最后和队友一起在墨刀上完成了文献摘要热词统计的原型设计。 |