一个简单的paddlepaddle线性回归预测、模型保存、模型加载及使用的过程.
全连接神经网络,fluid.layers.fc:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/layers_cn/fc_cn.html#fc
平方误差,fluid.layers.square_error_cost:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/layers_cn/square_error_cost_cn.html#square-error-cost
随机梯度下降,fluid.optimizer.SGDOptimizer:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/optimizer_cn/SGDOptimizer_cn.html#sgdoptimizer
模型保存,save_inference_model:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/save_inference_model_cn.html#save-inference-model
模型加载,load_inference_model:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/load_inference_model_cn.html#load-inference-model
import paddle.fluid as fluid
import paddle
import numpy as np
def load_model(inpt):
# 定义一个简单的线性网络,对输入inpt进行全连接,映射为100维大小
# batchsize:一批、一组数据的大小
# 比如输入inpu:[batchsize,13],则hidden:[batchsize,100]
hidden = fluid.layers.fc(input=inpt, size=100, act='relu')
# 再全连接,映射为1维大小,作为输出
# [batchsize,1]
net = fluid.layers.fc(input=hidden, size=1, act=None)
return net
def cost(model,label):
# 定义损失函数,损失需要预测input,真实值label
# (model-label)^2
cost = fluid.layers.square_error_cost(input=model, label=label)
# 为了忽略数量的影响,损失定义为平均损失
avg_cost = fluid.layers.mean(cost)
return avg_cost
def optimizer(cost):
# 定义优化方法为随机梯度下降SGDOptimizer,会对输入cost进行反向梯度,希望cost变得越来越小
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01)
opts = optimizer.minimize(cost)
return opts
def data():
# 定义训练和测试数据,5条数据,每条13维
x_data = np.array([[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[2.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[3.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[4.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[5.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]).astype('float32')
# 5条数据的回归y值
y_data = np.array([[3.0], [5.0], [7.0], [9.0], [11.0]]).astype('float32')
# 1条测试数据
test_data = np.array([[6.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]).astype('float32')
return x_data, y_data, test_data
def train(epoch, feed, fetch_list, exe):
# 训练epoch次
for ei in range(epoch):
train_cost, o_net = exe.run(program=fluid.default_main_program(),
feed=feed,
fetch_list=fetch_list)
print("epoch:%d, cost:%0.5f" % (ei, train_cost[0]))
def save(params_dirname='result', feeded_var_names=None, target_vars=None, executor=None):
'''
params_dirname:保存的路径
feeded_var_names:保存模型的输入名称list
target_vars:模型的输出目标
executor:模型的执行器
'''
print('save model at:',params_dirname)
fluid.io.save_inference_model(dirname=params_dirname, feeded_var_names=feeded_var_names,
target_vars=target_vars, executor=executor)
def execut(if_cuda=False):
# 创建执行设备,如果GPU,就使用0号GPU卡,多卡在后面,慢慢来
place = fluid.CUDAPlace(0) if if_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
return exe
def predict(program, feed_data, fetch_list):
# 开始预测
result = exe.run(program=program,
feed=feed_data,
fetch_list=fetch_list)
print("当x为6.0时,y为:%0.5f:" % result[0][0][0])
if __name__ == '__main__':
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
# 创建数据
x_data, y_data, test_data = data()
# 创建模型
predict_y = load_model(x)
# 创建当前主程序default_main_program的克隆程序,用于预测:clone(for_test=True)
test_program = fluid.default_main_program().clone(for_test=True)
# 创建损失
avg_cost = cost(predict_y,y)
opts = optimizer(avg_cost)
# 创建执行器
exe = execut(if_cuda=True)
# 初始化所以网络参数
exe.run(fluid.default_startup_program())
# 开始训练,喂的数据是:{'x': x_data, 'y': y_data},希望输出的是:平均损失avg_cost,模型输出model
train(epoch=10, feed={'x': x_data, 'y': y_data}, fetch_list=[avg_cost, predict_y], exe=exe)
# 保存模型,这个模型保存到result,输入的数据要求必须是给x占位的,输出的是模型最后那个return net
save(params_dirname='result', feeded_var_names=['x'], target_vars=[predict_y], executor=exe)
predict(program=test_program, feed_data={'x': test_data}, fetch_list=[predict_y])
'''
epoch:0, cost:49.64904
epoch:1, cost:15.40312
epoch:2, cost:2.15408
epoch:3, cost:0.05858
epoch:4, cost:0.03799
epoch:5, cost:0.03717
epoch:6, cost:0.03639
epoch:7, cost:0.03562
epoch:8, cost:0.03488
epoch:9, cost:0.03415
save model at: result
当x为6.0时,y为:13.28173:
'''
模型保存后的样子:
在别的地方加载之前保存的result模型:
import paddle.fluid as fluid
import numpy as np
def execut(if_cuda):
place = fluid.CUDAPlace(0) if if_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
return exe
if __name__ == '__main__':
# 现在需要加载训练好的模型,并且预测2条数据:
test_data = np.array([[6.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[3.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
]).astype('float32')
# 创建执行器
exe = execut(if_cuda=False)
# 之前保存的模型目录
params_dirname = "result"
# 开始加载模型,模型会返回:执行程序,输入数据名列表,返回数据列表
# ps:所以这里要记得自己之前保存的时候返回多少个数据target_vars=[predict_y],在执行exe.run的左边就设置相应个数接回这些数据
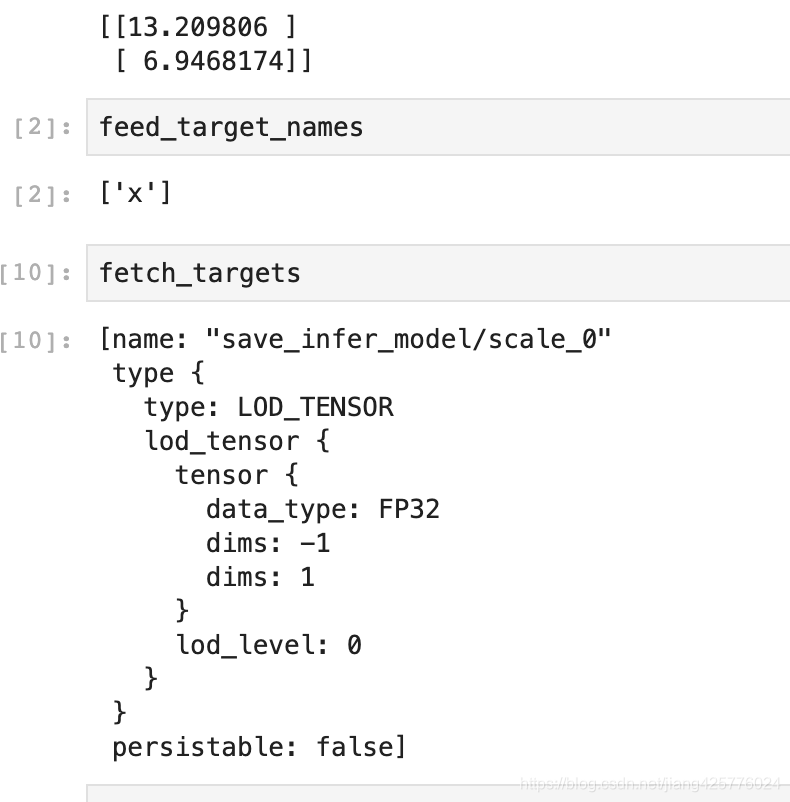
inference_program, feed_target_names, fetch_targets = fluid.io.load_inference_model(params_dirname, exe)
results = exe.run(inference_program,
feed={"x": test_data},
fetch_list=fetch_targets)
print(results[0])
返回内容: