故事从一条小学数学题说起

"爸爸,熊猫为什么是3个不是11个"
"宝贝,你还没学二进制好吗....."
以上故事纯属虚构,真实的对话其实是这样的
"爸爸, 为什么3比4小"
"宝贝,数一下就知道啦。你看猪猪有1,2,3. 3个, 小鸟有1,2,3,4. 4个. 你看小鸟是不是比猪猪多? 所以3比4小"
为什么我们要用十进制? 我们当然明白十进制是为了把世界描述为在数学上大家统一使用的语言然后进行沟通, 如果你用十进制我用二进制,那没法沟通了是不?
决策树用多了, 习惯了用信息增益作为特征选择的指标, 而信息增益是由前熵后熵差值而来.
为什么用熵? 对不起,这个问题请问科学家,你用就是了
为什么说熵比较高就是比较混乱? 接下来我们算一算验证一下.
首先来个简单粗暴的:
给三个球分类, 显然一眼就可以看出把红球独自一组,黑球一组. 那么具体分类的信息增益怎样呢?
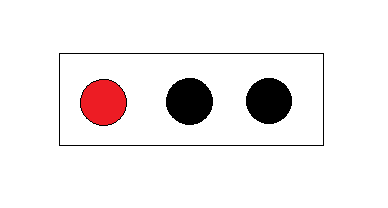
在Excel里算前熵
E(三个球) = - 1/3 * log(1/3, 2) - 2/3 * log(2/3,2) = 0.918
第一种分法是红黑球一组,黑球自己一组. 在红黑一组中有红球和黑球, 红黑球各自出现的概率是1/2. 在另一组只有 100%出现黑球, 红球的概率是0
所以 E(红黑|黑) = E(红黑) + E(黑) = - 1/2 * log( 1/2, 2) - 1/2 * log (1/2, 2) - 1 * log( 1, 2) = 1
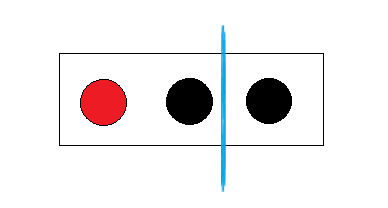
第二种分法就是红球自己一组了, 在红球组中出现黑球的概率是0, 在黑球组中出现红球的概率是0, 这样的分类已经"纯"了. 还是可以计算熵:
E(红|黑黑) = E(红) + E(黑黑) = - 1 * log( 1, 2) - 1 * log( 1, 2) = 0

那么,
红黑混合的信息增益 G(红黑|黑) = E(三个球) - E(红黑|黑) = 0.918 - 1 = -0.02
红黑分开的信息增益 G(红|黑黑) = E(三个球) - E(红|黑黑) = 0.918 - 0 = 0.918
故增益较大的红|黑黑分组较好.
注: 规定了 log ( 0, 2) = 0, 虽然这在数学上不成立
热身结束, 来个稍微复杂点的:
开始之前, 请始终把焦点集中在红蓝两个颜色上,它是我们的分类目标

E(BeforeSplit) = - 4/6 * log( 4/6, 2) - 2/6 * log( 2/6, 2) = 0.918
如果选择形状(Shape)分类, 结果是这样的(请始终把焦点集中在红蓝两个颜色上):

E(N1) = 0
E(N2) = - 2/3 * log( 2/3,2) - 1/3 * log( 1/3, 2) = 0.918
信息增益 G(Shape) = 0.918 - 0.918 - 0 = 0
根据表情分类, 结果是这样的(请始终把焦点集中在红蓝两个颜色上):

E(N1) = 0
E(N2) = -1/2 * log( 1/2, 2) - 1/2 * log( 1/2, 2) = 1
信息增益 G(Shape) = 0.918 - 1 - 0 = -0.02
如果选择线条(粗细)分类, 结果是这样的(请始终把焦点集中在红蓝两个颜色上):

E(N1) = -1/2 * log( 1/2, 2) - 1/2 * log( 1/2, 2) = 1
E(N2) = -1/4 * log( 1/4, 2) - 3/4 * log( 3/4, 2) = 0.811
信息增益 G(Bold) = 0.918 - 1 - 0.811 = - 0.893
故, 首选按形状分类。
由此也可以看出,极端情况下,使用信息增益选取特征有向节点熵为0倾斜的趋势,然而这未必就是最佳选择,但是大多情况下,它工作得不错.
10进制也不是所有领域都适用呀对吧?