高级操作
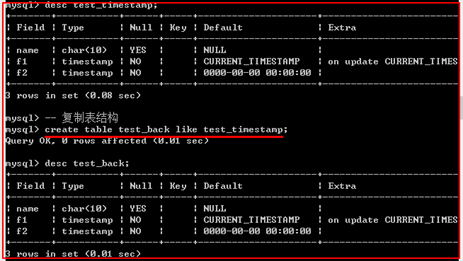
复制表结构
语法:
create table 表B like 表A;
示例:
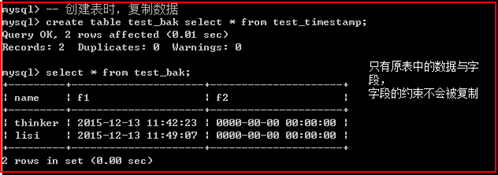
复制表中的数据
语法:
create table 表B select *或字段列表 from 表A;
蠕虫复制
语法:
insert into 表名【(字段列表)】 select *或字段列表 from 表名;
修改操作
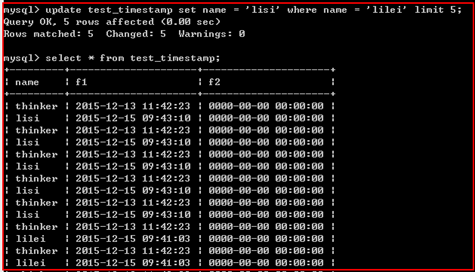
限制修改指定的行数。
语法:
update 表名 set 字段=值... 【where子句】 limit n;
说明:
在执行update语句时,限制最多修改n行
示例:
删除操作
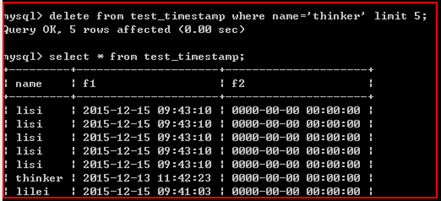
限制删除的行数
语法:
delete from 表名 【where 子句】 limit n;
说明:
用于限制最多只能删除n条记录
示例:
插入操作
主键冲突
基本语法:
insert into 表名【(字段列表)】 values(值列表);
主键冲突
insert into 表名【(字段列表)】 values(值列表) on duplicate key update 字段=值,字段=值...;
示例:
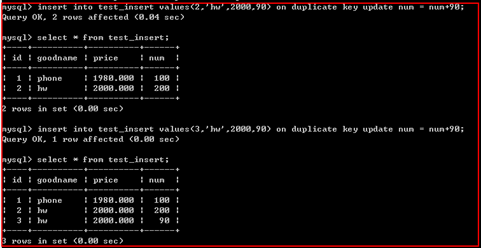
说明:
主键冲突的方式也可应用在唯一键冲突。
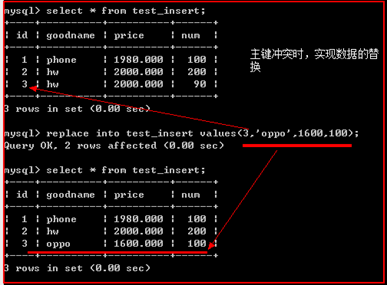
唯一键冲突
同理
replace into 表名【字段列表】 values(值列表);
说明:
在主键冲突或唯一键冲突时,替换冲突的记录
示例:
查询操作
标准语法:
select 【all|distinct】 *|字段列表|字段名 【as】 别名 from 数据源 【where子句】【group by子句】【having子句】【order by 子句】【limit子句】
说明:
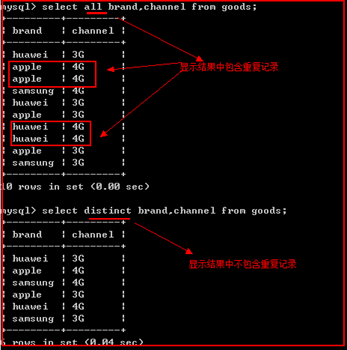
select选项
all(缺省) 表示显示所有的记录(包含重复的记录)
distinct 表示不显示重复的记录(去掉重复记录)
示例:
字段别名
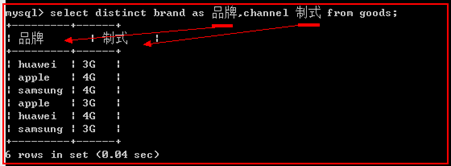
语法:
字段名 【as】 别名
示例:
说明:
只是在显示的更改字段的名子,并没有更改表结构中的字段的名子。
一般是用在多表查询时
表别名
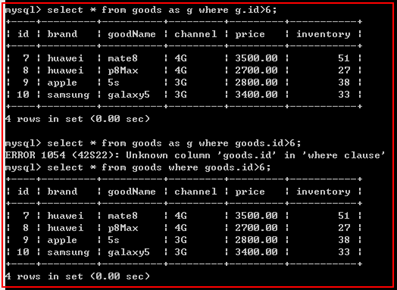
语法:
from 表名 【as】 表别名
示例:
数据源
数据的来源,数据的来源可以分3种:
1、单表数据源
select * from 表名;
2、多表数据源
select * from 表A,表B;
说明:
将多个表的字段进行横向连接,
记录数相乘
术语:迪卡尔积
示例:
3、子查询数据源
select语句查询的结果是一个结果集,那再将此结果集作为from的一个数据源,此种数据源即为子查询数据源
示例:
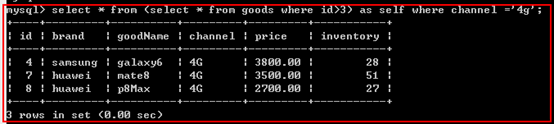
说明:
子查询数据源,必须将子查询使用括号括起来,并且设置一个别名
【where子句】
根据条件进行数据筛选,条件即为一个表达式,表达式就需要运算符
is null
is not null
<=>安全相等 专用于判断null,只适用于MySQL SQL Server不适用
between
between m and n
介于m与n之间(包含m与n)
in
like
% 表示当前位置及其后所有的字符
_ 只表示当前位置的字符
where原理
首先明确:计算机数据存储磁盘,运算在内存中。
where就是将存储磁盘中的数据,读取到内存,并根据条件进行筛选。如果省略where,则表示所在记录都匹配
图解:

【group by子句】
作用是根据group by的条件进行分组,就是一个大的结果集,划分为多个小区域,再进行统计。
简单分组:
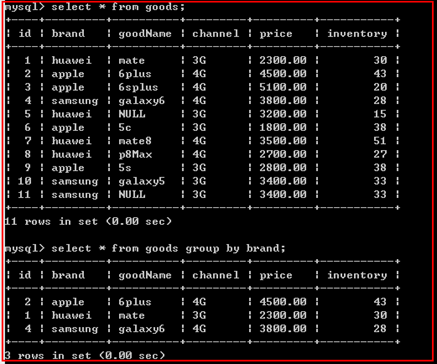
说明:
group by虽然是分组的意义,但group by 更重要的作用是对大的结果集中的小区域进行统计。
group by的原理
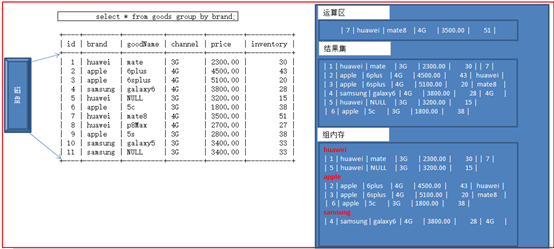

更改分组排序
示例:
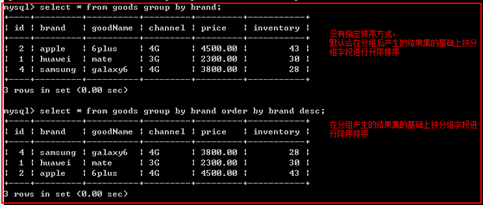
需求,每一组中价格最高的商品
错误示例:由于order by 是根据 group by之后的结果再行排序,
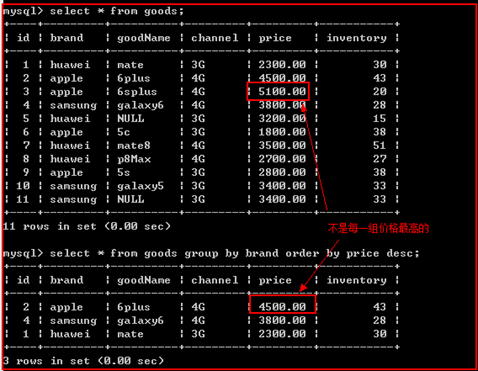
解决办法,在分组之前就对原数据进行排序。
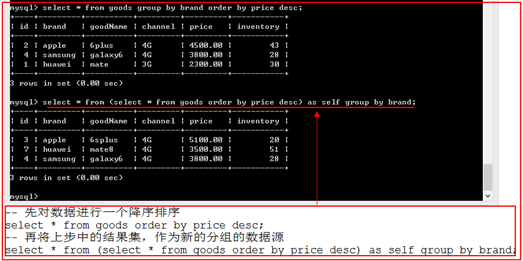
统计函数(聚合函数)
group by 最主要的作用是对分组的小区域进行统计
count();
统计显示结果中记录数
语法:
count(*|字段名);
说明:
*:表示统计所有的记录数
字段名:根据字段名进行统计记录数
示例1:
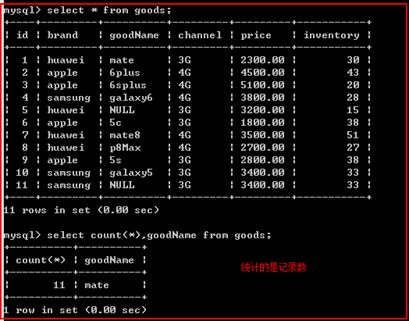
示例:

max();
统计最大值
示例:
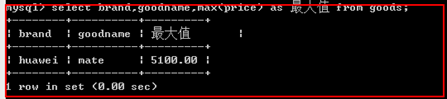
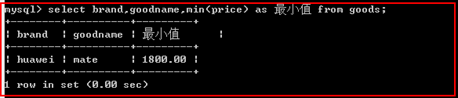
min();
统计最小值
示例:
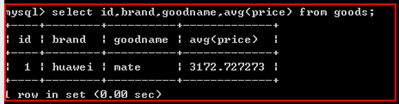
avg();
统计平均值
示例:
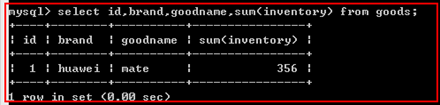
sum();
统计和
示例:
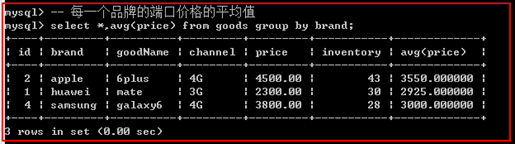
分组统计:
示例1:
示例2:

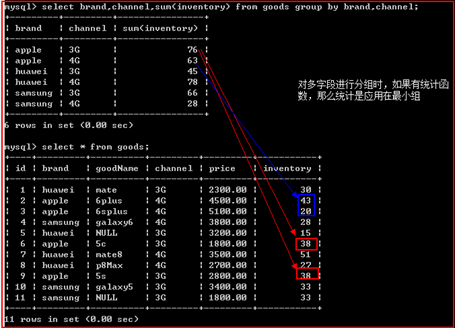
多字段分组
group by可以对多字段进行分组
语法:
group by 字段1,字段2;
说明:
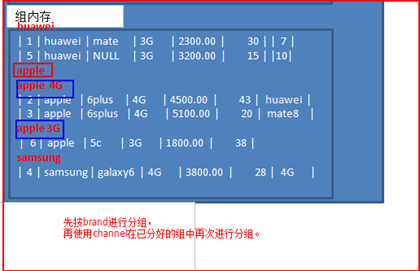
先使用字段1对结果集进行分组,再使用字段2在分组的结果中再进行分组。有几个字段相当于分了几层。
示例:
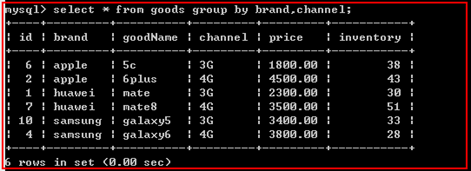
图解:
对多字段进行分组并统计时,统计函数是应用在最小组
示例:
with rollup(回溯)
使用汇总,对多个字段进行分组时所产生的多个层级的组,由里向外再应用统计函数。
示例:
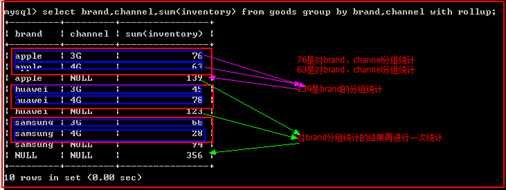
原理图:

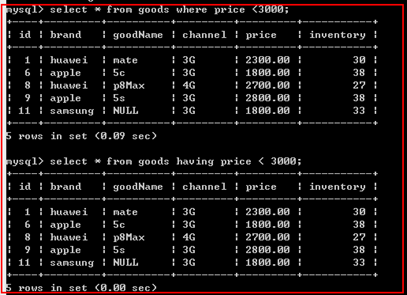
【having子句】
作用:
对group by分组后的结果再进行筛选。
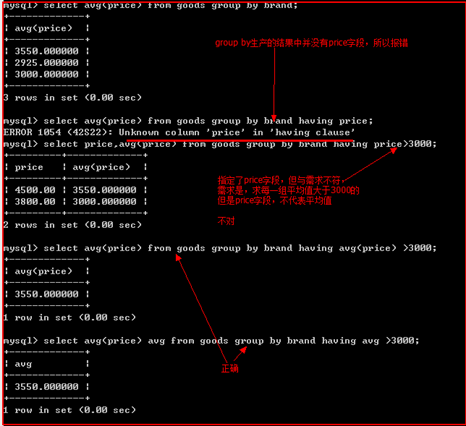
where能够实现的having也能够实现,但是having能实现的,where不一定能实现
示例:
where 的效率高于having。
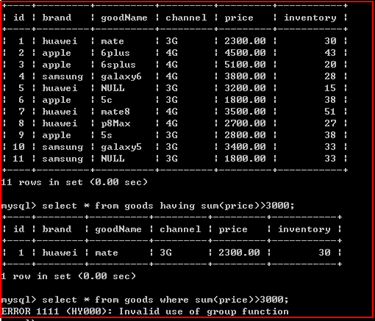
having可以使用统计函数,但是where不可以使用统计函数。
说明:
统计函数是对分组后的数据进行再次统计。在where执行过程中,结果集还没有完成生成,所以无法应用统计函数。
【order by 子句】
按指定的字段对数据进行排序
asc 升序
desc 降序
【limit子句】
限制数据的操作(显示、更新、删除)
外键
外键,就是外面的键。
为了某种需求,表A中的某个字段是表B中的主键,那么该字段叫表B的外键。
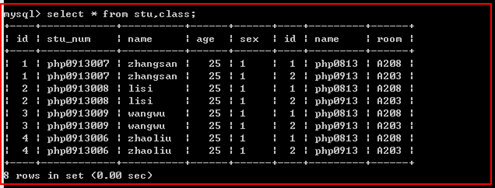
需求,有两个表,学生表与班级表,学生与班级有关系。如下:
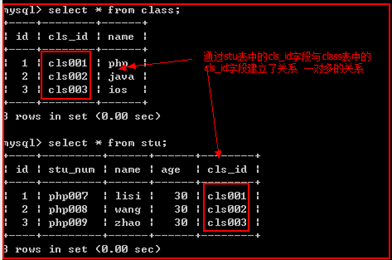
虽然两个表建立关系,但并没有实质的约束存在,如下:
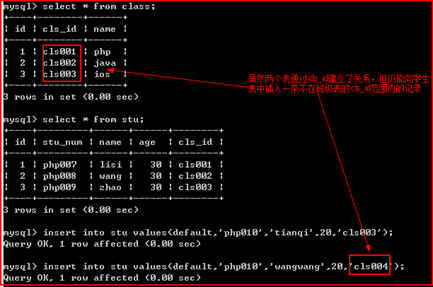
为了解决此种问题,必须使用外键约束。
创建外键:
条件:
前提外键所附属的表必须先存在
外键字段必须所附属表的主键
字段的类型一定要相同。
语法1:在创建表时创建外键。
foreign key(字段) references 表名(字段名)
示例:

语法2:通过修改表结构,创建外键

查看外键
show create table 表名;
示例:
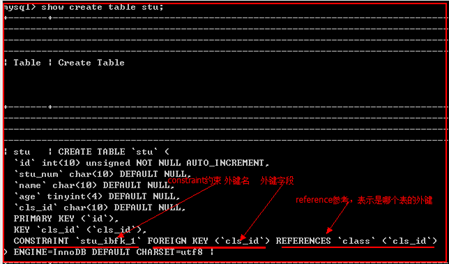
删除外键
语法:
alter table 表名 drop foreign key 外键名;
示例:

使用外键
1、向class插入数据

2、向stu表中插入数据
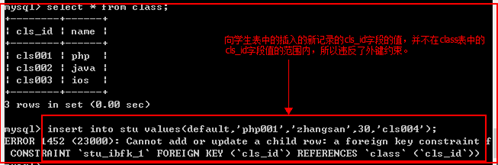
外键的约束
class为主表,stu为从表
主表被从表约束
1、对主表的数据进行操作时(update与delete),不能违反外键约束。
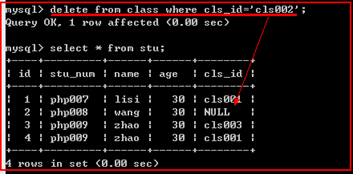
示例:

2、如果主表与从表建立了外键约束,那么主表不能被删除
示例:

从表被主键约束
向从表中插入数据时,外键字段,必须是主表中主键字段已有的数据。
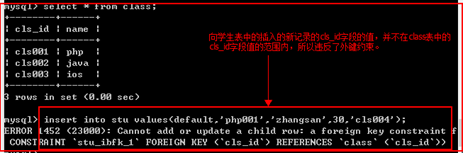
置空约束
on delete set null
当删除主表中的记录时,从表中与之有关联的记录的外键自动设置为null
级联约束
on update cascade
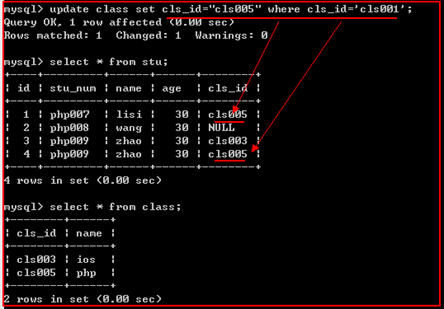
当对主表中的记录的主键字段进行更改时,从表中的与之关联的外键同步更新。
示例:
添加置空与级联约束
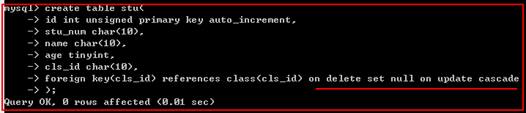
添加数据:
insert into stu values(default,'php007','lisi',30,'cls001');
insert into stu values(default,'php008','wang',30,'cls002');
insert into stu values(default,'php009','zhao',30,'cls003');
insert into stu values(default,'php009','zhao',30,'cls001');
尝试删除与更新