1.评价指标的局限性
问题1 准确性的局限性
准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
例子:Hulu的奢侈品广告主希望把广告定向投放给奢侈品用户。Hulu通过第三方的数据管理平台拿到了一部分奢侈品用户的数据,并以此为训练集和测试集,训练和测试奢侈品用户的分类模型,该模型的分类准确率超过了95%,但在实际广告投放过程中,该模型还是把大部分广告投给了非奢侈品用户,这可能是什么原因造成的?
解决方法:可以使用平均准确率(每个类别下的样本准确率的算术平均)作为模型评估的指标;也可能是其他问题:过拟合或欠拟合、测试集和训练集不合理、线下评估和线上测试的样本分布存在差异。
问题2 精确率与召回率的权衡
精确率=分类正确的正样本个数/分类器判定为正样本的样本个数 所有推荐了的新闻中该推荐的新闻的比例。 比如,推荐了10篇新闻,其中8篇是应该推荐的
召回率=分类正确的正样本个数/真正的正样本的样本个数 所有应该推荐的新闻中实际推荐了的新闻的比例。比如应该推荐10篇感兴趣的新闻,只推荐了其中的8篇。
要平衡精确率和召回率,可以调节区分正负类别的概率临界值。 为提高精确率,可以提高概率临界值,使得正类别的判断更加保守;为了提高召回率,可以降低概率临界值,以增加正类别的数量
例子:Hulu提供视频的模糊搜索功能,搜索排序模型返回的Top5的精确率非常高,但在实际使用过程中,用户还是经常找不到想要的视频,特别是一些比较冷门的剧集,这可能是哪个环节出了问题呢?分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低。
解决方法:用P-R曲线,横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲线上的一个点代表着,在某一个阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本
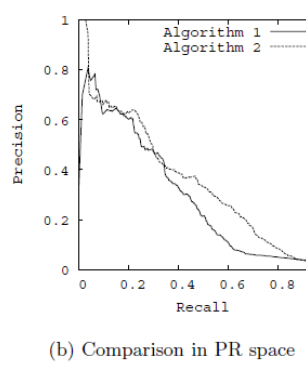
建议:做搜索:保证召回的情况下提升准确率;做疾病监测、反垃圾:保证准确率的条件下,提升召回率
问题3 平方根误差的“意外”
例子:Hulu作为一家流媒体公司,拥有众多的美剧资源,预测每部美剧的流量趋势对于广告投放、用户增长都非常重要,我们希望构建一个回归模型来预测某部美剧的流量趋势,但无论采用哪种回归模型,得到的RMSE指标都非常高。然而事实是,模型在95%的时间区间内的预测误差都小于1%,取得了相当不错的预测结果。那么,造成RMSE指标居高不下的最可能原因是什么?
原因分析:在实际情况中,如果存在个别偏离程度非常大的离群点,即使离群点数量非常少,也会让RMSE指标变得很差。回到问题中,模型在95%的时间区间内的预测误差都小于1%,这说明,在大部分时间区间内,模型的
预测效果都是 非常优秀的,然而,RMSE却一直很差,这很可能是由于在其他的5%时间区间存在非常严重的离群点。事实上,在流量预估这个问题中,噪声点确实是很容易产生的,比如流量特别小的美剧、刚上映的美剧或者
刚获奖的美剧,甚至一些相关社交媒体突发事件带来的流量,都看会造成离群点。
解决方法:
1)如果我们认定这些离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉;
2)如果不让我这些离群点是“噪声点”,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去;
3)找一个更合适的指标来评估该模型。关于评估指标,其实是存在比RMSE的鲁棒性更好的指标,比如平均绝对百分误差MAPE(mean absolute percent error),相比于RMSE,MAPE相当于把每个点的误差进行了归一化,降低了
个别离群点带来的绝对误差的影响。
2.ROC曲线
问题1:什么是ROC曲线?
ROC曲线是Receiver operating characteristic curve的简称,中文名为“受试者工作特征曲线”。ROC曲线源于军事领域,横坐标为假阳性率(False positive rate,FPR),纵坐标为真阳性率(True positive rate,TPR).
假阳性率 FPR = FP/N ---N个负样本中被判断为正样本的个数占真实的负样本的个数
真阳性率 TPR = TP/P ---P个正样本中被预测为正样本的个数占真实的正样本的个数
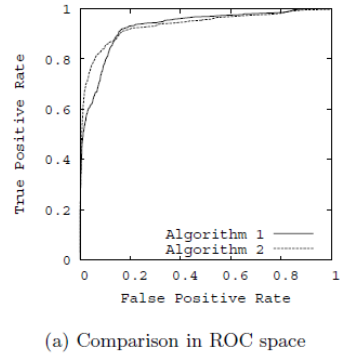
问题2:如何绘制ROC曲线?
ROC曲线是通过不断移动分类器的“截断点”来生成曲线上的一组关键点的,“截断点”指的就是区分正负预测结果的阈值。
通过动态地调整截断点,从最高的得分开始,逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC图上绘制出每个截断点对应的位置,再连接所有点就得到最终的ROC曲线。
问题3:如何计算AUC?
AUC指的是ROC曲线下的面积大小,该值能够量化地反映基于ROC曲线衡量出的模型性能。由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC的取值一般在0.5-1之间。AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
问题4:ROC曲线相比P-R曲线有什么特点?
当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。ROC能够尽量降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线能够更直观地反映其性能。
3.余弦距离的应用
问题1:结合你的学习和研究经历,探讨为什么在一些场景中要使用余弦相似度而不是欧氏距离?
余弦相似度在高维情况下依然保持“相同时为1,正交时为0,相反时为-1”的性质,而欧式距离的数值则受维度影响,并且含义也比较模糊。
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
例子:统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0);此时两者的余弦距离很大,而欧氏距离很小;我们分析两个用户对不同视频的偏好,更关注相对差异,显然应当使用余弦距离;而我们分析用户活跃度,以登录次数和平均观看时长作为特征时,余弦距离会认为(1,10)和(10,100)两个用户距离很近;但显然这两个用户活跃度是有着极大差异的,此时我们更关注数值绝对误差,应当使用欧式距离。
问题2:余弦距离是否是一个严格定义的距离?
距离需满足三条性质:正定性、对称性、三角不等式;
余弦距离满足正定性和对称性,但是不满足三角不等式,因此它不是严格意义上的距离。
正定性证明dist(A,B)>0;
对称性证明dist(A,B)=dist(B,A)
三角不等式证明dist(A,C)+dist(C,B) >= dist(A,B)
例子:在通过影视语料库训练出的词向量中,comedy和funny,funny和happy的余弦距离都很近,小于0.3,然而comedy和happy的余弦距离却高达0.7.这一现象明显不符合距离的定义。
在机器学习领域中,KL距离也叫相对熵,常用于计算两个分布之间的差异,但不满足对称性和三角不等式。
4.A/B测试的陷阱
问题1:在对模型进行充分的离线评估之后,为什么还要进行在线A/B测试?
原因:(1)离线评估无法完全消除模型过拟合的影响;
(2)离线评估无法完全还原线上的工程环境;
(3)线上系统的某些商业指标在离线评估中无法计算。
问题2:如何进行线上A/B测试?
进行用户分桶,即将用户分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型,在分桶的过程中,要注意样本的独立性和采样方式的无偏性,确保同一个用户每次只能分到同一个桶中,在分桶过程中所选取的user_id需要是一个随机数,这样才能保证桶中的样本是无偏的。
问题3:如何划分实验组和对照组?
例子:H公司的算法工程师们最近针对系统中的“美国用户”研发了一套全新的视频推荐模型A,而目前正在使用的针对全体用户的推荐模型是B。在正式上线之前,工程师们希望通过A/B测试来验证新推荐模型效果。
正确的做法是将所有美国用户根据user_id个位数划分为试验组合对照组,分别施以模型A和B,才能验证模型A的效果。
5.模型评估的方法
问题1:在模型评估过程中,有哪些主要的验证方法,它们的优缺点是什么?
(1)Holdout检验:
直接将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个点击量预测模型,我们把样本按照70%~30%的比例分成两部分,70%的样本用于模型训练;30%的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能;
缺点:在验证集上计算出来的最后评估指标与原始分组有很大的关系
(2)交叉验证
K-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;一次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实验中,k经常取10.
留一验证:每次留下一个样本作为验证集,其余所有样本作为测试集。在样本总数较多的情况下,留一验证的时间开销极大.
留p验证:每次留下p个样本作为验证集,而从n个元素中选择p个元素有Cnp种可能,因此它的时间开销更是远远高于留一验证。
(3)自助法
基于自助采样法的校验方法。对于总数为n的样本集合,进行n次有放回的随机抽样,得到大小为n的训练集。n次抽样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行规模验证。
问题2:在自助法的采样过程中,对n个样本进行n次自助抽样,当n趋于无穷大时,最终有多少数据从未被选择过?
一个样本在一次抽样过程中未被抽中的概率为(1-1/n),n次抽样均未被抽中的概率为(1-1/n)n,当n趋于无穷大时,概率为1/e,因此当样本数很大时,大约有36.8%的样本从未被选择过,可作为验证集。
6.超参数调优?
问题1:超参数有哪些调优方法?
(1)网格搜索
通过查找搜索范围内的所有的点来确定最优值。如果采用较大的搜索范围以及较小的步长,网络搜索有很大概率找到全局最优值。然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候,因此,在实际应用中,网格搜索法一般会使用较广的搜索范围和步长,来寻找全局最优值可能的位置;然后会逐渐缩小搜索范围和步长,来寻找更精确的最优值。这种方案可以降低所需的时间和计算量,但由于目标函数一般是非凸的,所以很可能会错过全局最优值。
(2)随机搜索
理论依据是如果样本集足够大,那么通过随机采样也能大概率地找到全局最优值,或其近似值。随机搜索一般会比网格搜索要快一些,但是和网格搜索的快速版一样,它的结果也是没法保证的。
(3)贝叶斯优化算法
网格搜索和随机搜索在测试一个新点时,会忽略前一个点的信息;而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的函数。具体来说,它学习目标函数形状的方法是,首先根据先验分布,假设一个搜集函数;然后,每一次使用新的采样点来测试目标函数时,利用一个这个信息来更新目标函数的先验分布;最后,算法测试由后验分布给出的全局最值最可能出现的位置的点。
对于贝叶斯优化算法,需要注意的是,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在搜索和利用之间找到一个平衡点,“搜索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。
7.过拟合与欠拟合
问题1:在模型评估过程中,过拟合和欠拟合具体是指什么现象?
过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差;
欠拟合指的是模型在训练和预测时表现到不好的情况。
问题2:能否说出几种降低过拟合和欠拟合风险的方法?
降低“过拟合”的方法:
(1)获得更多的训练数据
(2)降低模型复杂度
(3)正则化方法
(4)集成学习方法
降低“欠拟合”风险的方法:
(1)添加新特征
(2)增加模型复杂度
(3)减小正则化系数