2018-05-03
《C++反汇编和逆向技术》第五章 流程控制语句的识别读书笔记(写了半天没保存,全没了,慢慢补充)
1.if语句块
if语句块的功能是先对运算条件进行比较,然后根据比较结果选择对应的语句块来执行。
cmp dword ptr[ebp+8],0 jne main+2Fh(0040103f) C语言中if语句argc == 0,对应汇编if是jne(不等于0则跳转)
总结: ;先执行各类影响标志位的指令 ;其后是各种条件跳转指令 jxx xxxx
汇编语言的if语句跟C语言中if语句是相反的,因为按照C语言中if语句的规定,满足if判定的表达式才能执行if的语句块,而汇编语言的条件跳转却是满足某条件则跳转,绕过代码块。
既然这样,为什么C语言编译器不将else语句块提到前面呢?
因为C语言是根据代码行的位置来决定编译后的二进制代码的地址高低的,也就是说,低行数对应低地址,高行数对应高地址,所以有时会使用标号相减得到代码段的长度。鉴于此,C语言的编译器不能随意改变代码行在内存中的顺序。
【CMP指令 对两个操作数进行一次减法操作。涉及到的标志位:
CF: 是否有进位或借位操作
ZF: 0标志位,就是结果是否为0
OF: 溢出标志位,计算机结果是否溢出了,只有有符号数才会溢出
SF: 符号位,0为正,1为负。】
【有符号数与无符号数比较后,使用的跳转指令不同。这是由于无符号数只考虑CF,ZF。无符号数还要考虑SF,OF。
如果比较指令是ja/jae/jb/jbe,是无符号数的比较。
如果比较指令是jg/jge/jl/jle.是有符号数的比较。】
2.if...else语句块
cmp dword ptr [ebp+8],0 jne IfElse+2Dh ;跳转到else语句块 ... ;if语句块 jmp IfElse+3Ah ;跳转过else块 ... ;else语句块 总结: ;先执行影响标志位的相关指令 jxx ELSE_BEGIN IF_BEGIN: ...... ;if语句块内的执行代码 IF_END: jmp ELSE_END ELSE_BEGIN: ...... ;else语句块内的执行代码 ELSE_END:
3.if...else_if...else语句块
cmp dword ptr [ebp+8],0 jle IfElseIf+2Dh ;跳转到下一个else if语句块 ... ;if语句块 jmp IfElse+4Fh ;跳到end cmp dword ptr [ebp+8],0 jne IfElseIf+42h ;跳转到else语句块 ... ;elseif语句块 jmp IfElse+4Fh ;跳到end ... ;else语句块 总结: ;先执行影响标志位的相关指令 jxx ELSE_IF_BEGIN IF_BEGIN: ...... ;if语句块内的执行代码 IF_END: jmp END ELSE_IF_BEGIN: ;可影响标志位的指令 jxx ELSE_BEGIN ...... ;else if语句块内的执行代码 ELSE_IF_END: jmp END ELSE_BEGIN: ...... ;else语句块内的执行代码 END:
4. switch的真相
switch是比较常用的多分支结构,使用起来非常方便,并且效率上也高于if...else if多分支结构。
case语句不超过3条的switch多分支结构:
cmp dword ptr [ebp-8],1 je SwitchIf+4Ah ;跳转到case1代码块 cmp dword ptr [ebp-8],3 je SwitchIf+59h ;跳转到case3代码块 cmp dword ptr [ebp-8],100 je SwitchIf+68h ;跳转到case100代码块 jmp end ... ;case1代码块 jmp end ... ;case3代码块 jmp end ... ;case100代码块 end
注意:switch的条件跳转指令跟C语言语句本身是一致的
上述代码片段显示switch语句使用了3次条件跳转指令,如果成功则跳转到相应的执行代码块中。这种结构与if...else if多分支结构很相似,不过也有明显的区别:
通过对比可以发现,if...else if会在每个条件跳转后紧跟语句块;而switch结构则将所有的条件跳转放置在一起,并且所有case语句块也都是连在一起放置的。这样做是为了实现C语法的要求,当case中没有break语句是,顺序执行后续case语句。[两个跳转地址之间就是一个case语句块]
在switch分支数小于4时,VC++6.0采用模拟if...else if的方法。这样做并没发挥出switch的优势,在效率上也没有if...else if强。
分支数大于3,并且case的判定值存在明显的线性组合关系时:

代码中为case语句制作了一份case地址表。这个数组保存了每个case语句块的首地址,并且数组的下标从0开始。而case中最小值是1,所有需要对edx减1调整,使其与地址表下标对应寻址。当然,如果case最小值是0,则不需要调整。

在进入switch后会先进行一次比较,检查输入的数值是否大于case值的最大值,如果大于则跳转到default。看00401128地址处case采用比例因子寻址。

case块还是连续放置的。实际没有case4块,为了达到线性有序,编译器将以switch结束地址或default语句块的首地址填充。
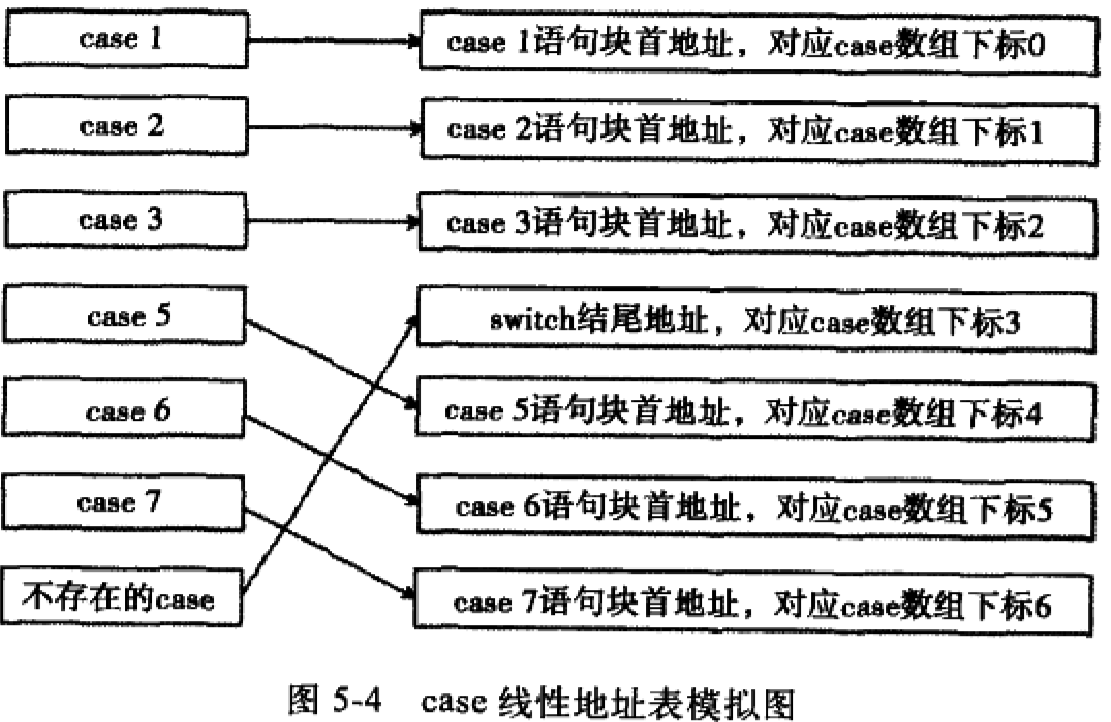
如果每两个case值之间的差值小于等于6,并且case语句数大于等于4,编译器就会形成这种线性结构。而且在便携式无需有序排列case值,编译器会在编译过程中对case线性地址表进行排序。如case顺序3,2,1,4,5,在地址表中也是,1,2,3,4,5。
5. 难以构成跳转表的switch
对于非线性的switch结构,可以采用制作索引表的方法来优化。索引表需要两张表:一张为case语句块地址表,另一张为case语句块索引表。
地址表中每一项保存一个case语句块的首地址,有几个case语句块就有几项。deault语句块也在其中,这个结束地址只会保存一份,不会像有序线性地址表那样,重复填充switch结束地址。
索引表中保存地址表的编号,它的大小等于最大case值和最小case值的差。当差值大于255时,这种优化方式也会很浪费空间,可通过树方式优化,下文再讲。
比如把上面case7改成case15,如果还用有序线性方式优化,则需要把7-15都填充成switch结束地址。很浪费空间。所以采用二次查表法:
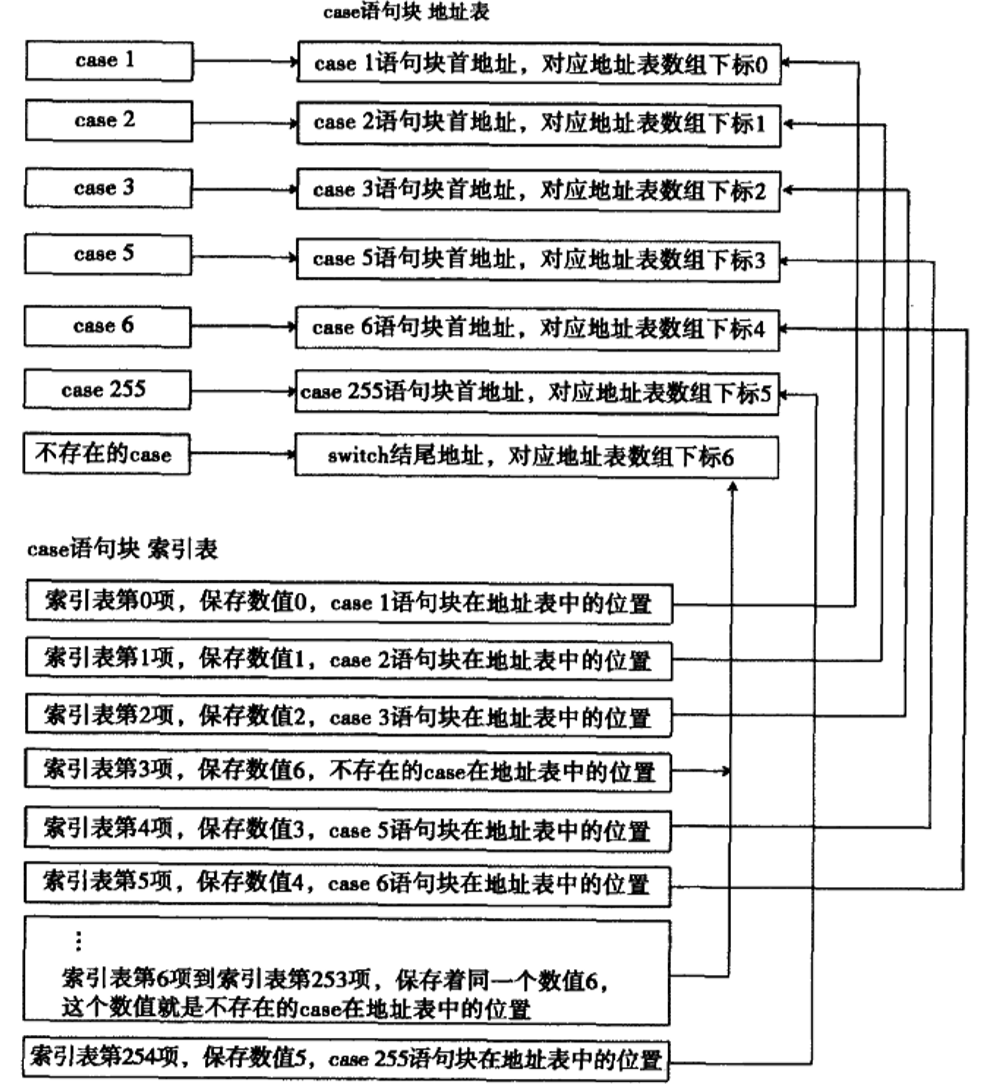
索引表中保存了地址表的下标值。索引表中最多可以存储256项,每项的大小为1个字节,这决定了case值不能超过1字节的最大表示范围(0-255)。
跟线性地址表相比,制作索引表更节省空间,但是由于查两次表,因此效率会有所下降。【虽然索引表和线性地址表都是连续空间,但索引表单位时1字节,线性地址表单位是4字节,所以还是节省空间的】
占用总字节数 = ((MAX - MIN) * 1字节)+ (SUM * 4字节)
6. switch降低判定树的高度
当最大case值与最小case值之差大于255,超出索引1字节的表达范围时,上述优化方案同样会造成空间的浪费。此时采用另一种优化方案——判定树:将每个case值作为一个节点,从这些节点中找到一个中间值作为根节点,以此形成一棵平衡二叉树,以每个节点为判定值,大于和小于关系分别对应左子树和右子树,这样可以提高效率。
如果打开O1选项——体积优先,由于有序线性优化和索引表优化都需要消耗额外的空间,因此在体积优先的情况下,这两种优化方案是不被允许的。编译器尽量以二叉判定树的方式来降低程序占用的体积。

其对应汇编代码会二分查找,先cmp 10分边再比较两边。
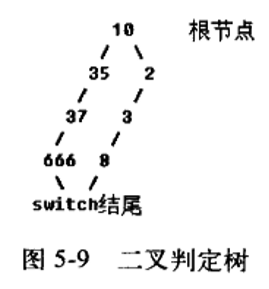
从图中发现,这棵树的左右两侧并不平衡。进行树平衡的效率低于if...else。这时,编译器采取的策略是,当树中的叶子节点数小于等于3时,就会转换形成一个if...else结构。
如果向左子树插入一个叶子节点10000时,左子树叶子节点大于4。此时if else转换已经不适合,优先查看是否可以匹配有序线性优化、非线性索引表优化,如果可以就转换,如果不行,继续使用判定树。
在Release版下,使用IDA查看编译器是如何优化的,如下图:
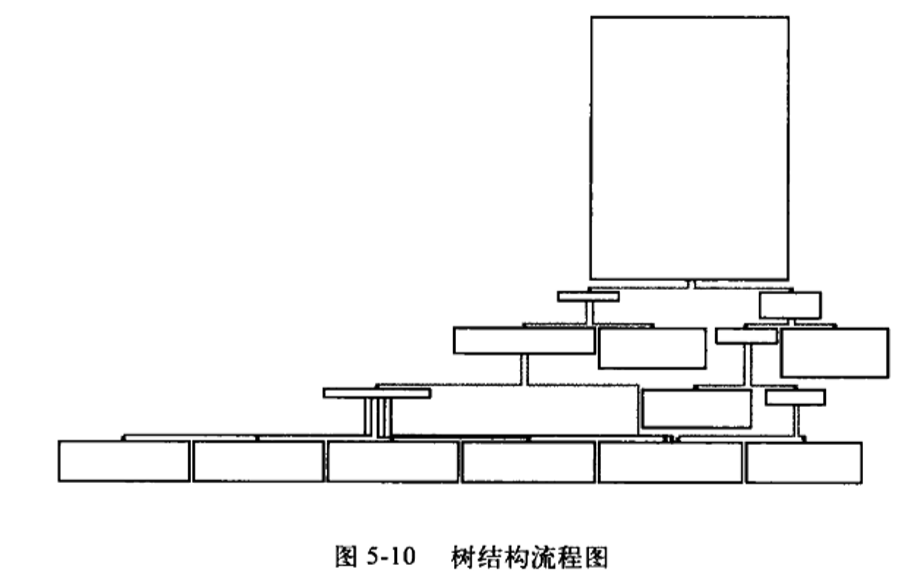
根据流程走向可以看出,有一个根节点,左边多分支结构很像一个switch,而右边则是一个多次比较判断,跟if...else类似。
总结:为了降低树的高度,在树的优化过程中,检测树的左子树或右子树能否满足if else优化、有序线性优化、非线性索引优化,利用这三种优化来降低树高度。选择哪种优化也是有顺序的,谁的效率最高,又满足其匹配条件,就可以被优先使用。以上三种优化都无法匹配,就会选择使用判定树。
7. do/while/for的比较
do循环:
... ;do循环语句块内的执行代码 cmp edx, dword ptr [ebp -8] jle LoopDo+26h(0040b4e6) ;向上跳转到do循环体,且条件跳转指令比较和C语句是一致的 end 总结: DO_BEGIN: ...... ;循环语句块 ;影响标记位的指令 jxx DO_BEGIN ;向上跳转
与if语句区别:if语句的比较是相反的,并且跳转地址大于当前代码的地址,是一个向下跳转的过程;而do中跳转逻辑小于当前代码的地址,是一个向上跳转的过程,所以条件跳转的逻辑与源码中的逻辑相同,且条件跳转指令比较和C语句是一致的。
while循环:
while循环和do循环正好相反,在执行循环语句块之前那,必须要进行条件判断,根据比较结果再选择是否执行循环语句块。
总结: WHILE_BEGIN: ;影响标志位的指令 jxx WHILE_END ;条件成立跳转到循环语句块结尾处 ...... ;循环语句块 jmp WHILE_BEGIN ;向上跳转 WHILE_END:
注意:while比较与if语句一样,也是比较相反,向下跳转。while循环结构中使用了两次跳转指令完成循环,比do循环多一次跳转,因此效率会低一点。
需要注意的是,while循环结构很可能被有化成do循环结构,如下:
if (xxx) { do { //.... }while(xxx) }
for循环:
for循环是三种循环中最复杂的一种。
总结: mov mem/reg, xxx ;赋初值 jmp FOR_CMP ;跳转到循环条件判定部分 FOR_STEP: ;修改循环变量Step mov reg,Step add reg,xxxx ;修改循环变量的计算过程,在实际分析中,视算法不同而不同 mov Step,eax FOR_CMP: ;循环条件判定部分 mov ecx,dword ptr Step ;判定循环变量和循环终止条件StepEnd的关系,满足条件则退出for循环 cmp ecx,StepEnd jxx FOR_END ;条件成立则结束循环 ...... ;循环体 jmp FOR_STEP ;向上跳转,修改流程回到步长计算部分 FOR_END:
三种循环结构的比较:
在执行效率上,do循环结构是最高的。因为do循环在结构上非常精简,利用了程序执行时由低地址到高地址的特点,只使用了一个条件跳转指令就完成了循环。
for循环是执行速度最慢的,他需要三个跳转指令才能完成循环。
while和for循环经常会优化成do循环。