- 1、Spark概述
- 2、Spark体验
- 3、Spark核心编程
- 4、数据开发三层架构
- 5、SparkSQL核心编程
- 6、SparkStreaming
1、Spark概述
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。

-
Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark的其他功能如:Spark SQL,Spark Streaming,GraphX,MLib都是在Spark Core的基础上进行扩展的
-
Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者HQL来查询数据
-
Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件
-
Spark MLib
MLib是Spark提供的一个机器学习算法库。
-
Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库
2、Spark体验
2.1 Maven项目相关配置
-
依赖配置
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> <build> <plugins> <!-- 该插件用于将 Scala 代码编译成 class 文件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <!-- 声明绑定到 maven 的 compile 阶段 --> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> -
配置log4j.properties文件在resources目录,控制日志级别
log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to ERROR. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2.2 Spark运行环境
2.2.1 Local模式
local模式,不需要其他任何任何节点资源,在本地执行Spark代码的环境,一般用于教学,调试,演示等。
-
解压安装包
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/software -
修改文件夹为spark_local
mv spark-3.0.0-bin-hadoop3.2 spark_local -
启动spark-shell
./bin/spark-shell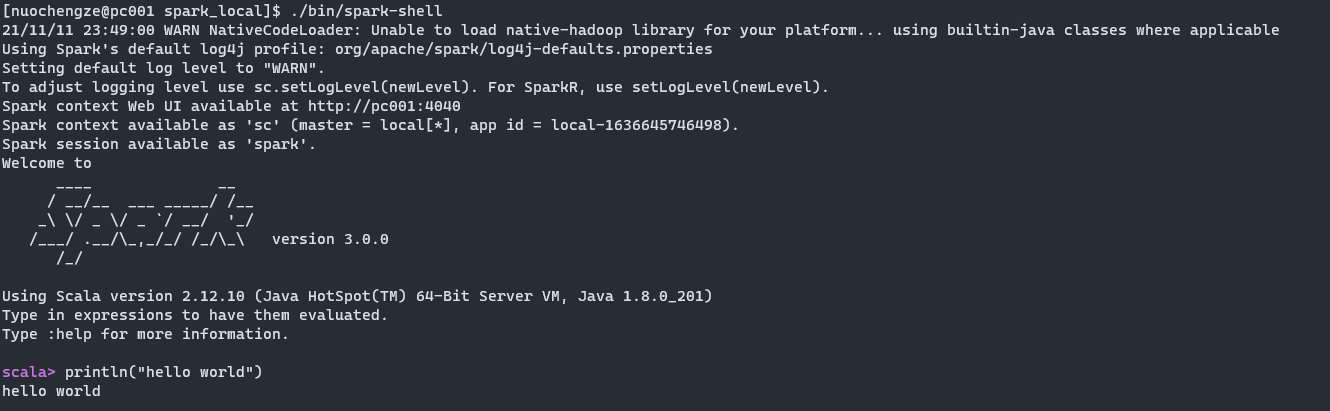
-
启动成功后,可以查看Web UI监控页面
http://pc001:4040-
执行spark任务
sc.textFile("/home/nuochengze/sublime_dir/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
-
Web UI反应程序在运行
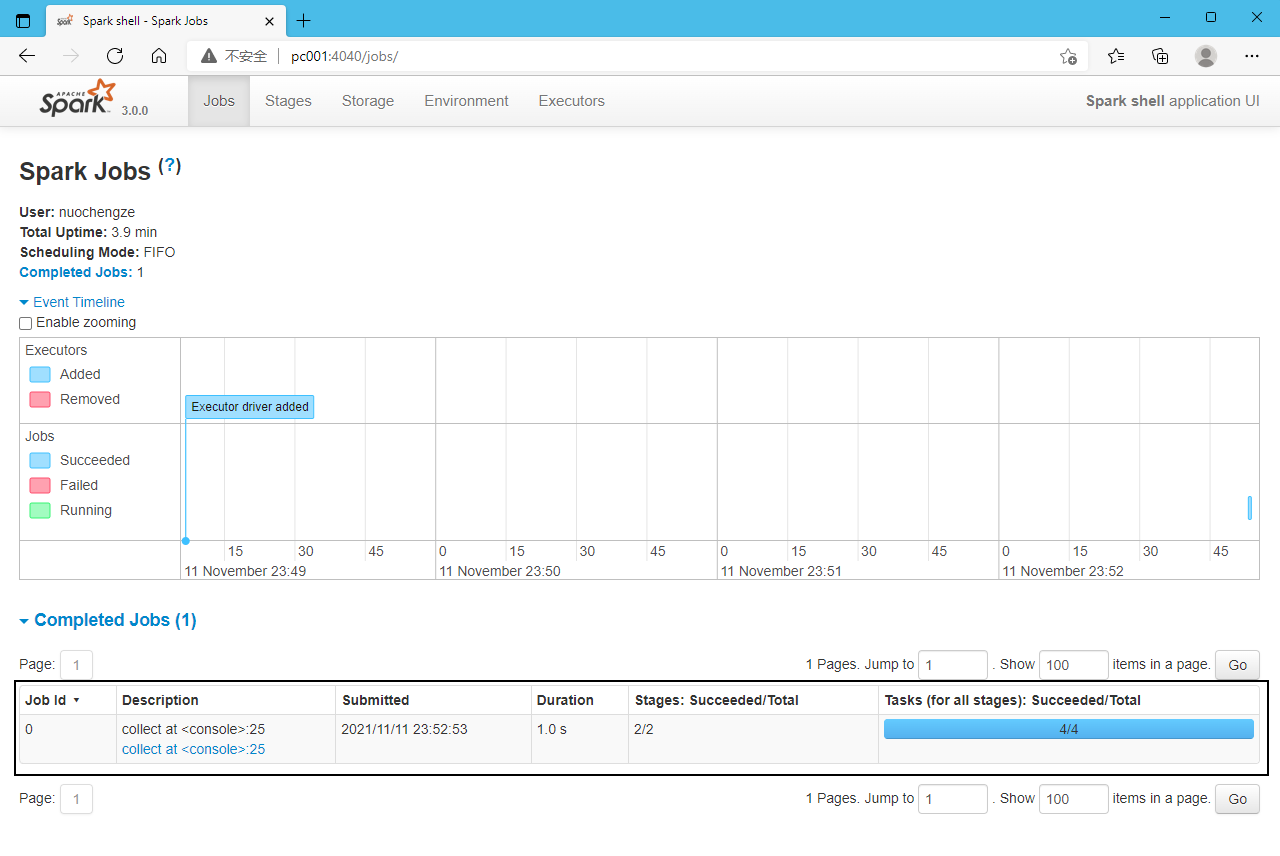
-
-
退出本地模式
ctrl+c或者输入
:quit -
本地提交应用
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10-
关键字解释

-
执行结果

-
2.2.2 Standalone模式
只使用Spark自身节点运行的集群模式,即独立部署(Standalone)模式
集群规划:
| pc001 | pc002 | pc003 | |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
实现步骤:
-
解压缩安装包
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/software cd /opt/software mv spark-3.0.0-bin-hadoop3.2 spark-standalone -
修改配置文件
-
进入解压缩后的路径的conf目录,修改workers.template文件为workers
mv workers.template workers -
修改workers文件,添加work节点
pc001 pc002 pc003 -
修改spark-env.sh.template文件名为spark-env.sh
mv spark-env.sh.template spark-env.sh -
修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
export JAVA_HOME=/opt/software/jdk1.8.0_201 SPARK_MASTER_HOST=pc001 SPARK_MASTER_PORT=7077说明:7077端口,为spark集群内部通讯端口
-
分发到其他host
-
-
启动集群
-
执行脚本命令
$SPARK_STANDALONE/sbin/start-all.sh
-
查看三台服务器的运行进程

-
查看Master资源监控Web UI:http://pc001:8080 (默认端口为8080)
-
-
提交应用
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://pc001:7077 \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10- --class表示要执行程序的主类
- --master spark://pc001:7077 standalone模式,连接到spark集群
- ./examples/jars/spark-examples_2.12-3.1.2.jar 运行类所在的jar包
- 10 表示程序的入口参数
-
执行程序时状态说明
程序在执行任务时,会产生多个java进程
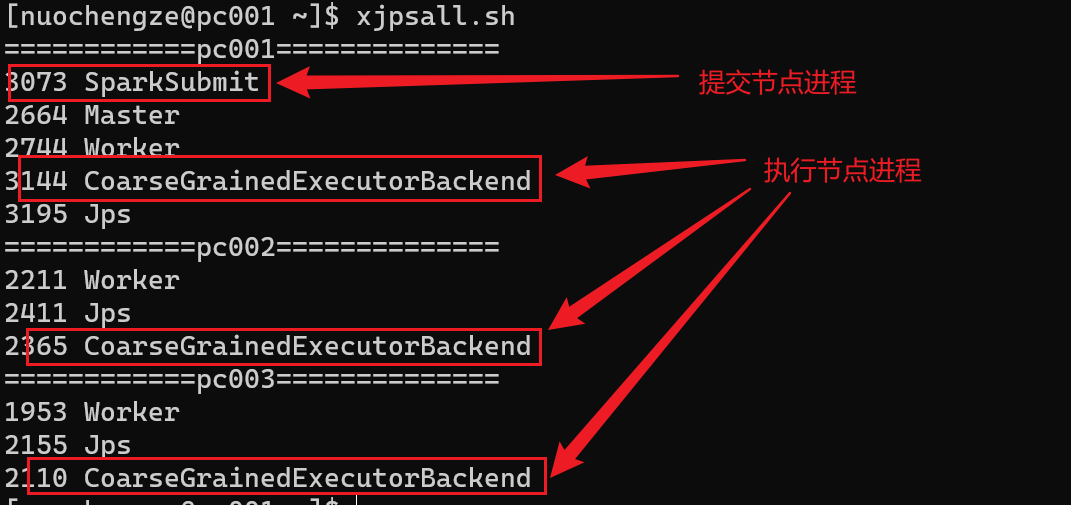
在执行任务时,默认采用服务器集群节点的总核数,每个节点内存1024M
-
提交参数说明
# 在提交应用中,一般会同时提交参数 ./bin/spark-submit \ --class <main-class> --master <master-url> \ ... # other options <application-jar> [application-arguments]参数 解释 可选值举例 --class Spark程序中包含主函数的类 --master Spark程序运行的模式(环境) (1)local[*]
(2)spark://pc001:7077
(3)Yarn--executor-memory 1G 指定每个executor可用内存为1G --total-executor-cores 2 指定所有executor使用的cpu核数为2个 --executor-cores 指定每个executor使用的cpu核数 application-jar 打包好的应用jar,包含依赖。这个URL在集群中全局可见,如hdfs:// 共享存储系统。如果是file://path,那么所有的节点的path都包含同样的jar application-arguments 传递给main()方法的参数 -
配置历史服务
在spark-shell停掉之后,集群监控pc001:4040页面无法看到历史任务的运行情况,需要配置历史服务器记录任务运行情况
-
修改/conf/spark-defaults.conf.template文件名为spark-defaults.conf
-
修改spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true spark.eventLog.dir hdfs://pc001:8082/spark/log_directory说明:HDFS上的directory_spark目录需要提前存在
hdfs dfs -mkdir /spark/log_directory -
修改spark-env.sh文件,添加日志配置
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://pc001:8082/spark/log_directory -Dspark.history.retainedApplications=30"- 参数1含义:WebUI访问的端口号为18080
- 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
-
分发配置文件
-
重新启动集群和历史服务
./sbin/stop-all.sh ./sbin/start-all.sh ./sbin/start-history-server.sh -
重新执行任务测试
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://pc001:7077 \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10 -
查看历史服务:http://pc001:18080
-
-
配置高可用(HA)
集群中Master节点只有一个,容易造成单点故障问题。需要配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务。其HA,由zookeeper提供可用性监测。
集群规划:
pc001 pc002 pc003 Spark Master
Zookeeper
WorkerMaster
Zookeeper
Worker
Zookeeper
Worker-
停止集群
./sbin/stop-all.sh ./sbin/stop-history-server.sh -
启动zookeeper
-
修改/conf/spark-env.sh文件并添加配置
# 注释如下内容: # SPARK_MASTER_HOST=pc001 # SPARK_MASTER_PORT=7077 # Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,自定义一下 SPARK_MASTER_WEBUI_PORT=8989 # 添加Zookeeper集群调度 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=pc001,pc002,pc003 -Dspark.deploy.zookeeper.dir=/spark" -
分发配置给其他host
-
重启集群
./sbin/stop-all.sh ./sbin/stop-history-server.sh ./sbin/start-all.sh ./sbin/start-history-server.sh -
访问pc001的Web UI:http://pc001:8989
-
启动pc002的单独Master节点,此时pc002节点Master状态处于备用状态
ssh pc002 "$SPARK_STANDALONE_HOME/sbin/start-master.sh" -
访问pc002的Web UI:http://pc002:8989
-
此时当pc001的master进程被意外中止时,pc002的master能及时替补
-
应用提交
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://pc001:7077,pc002:7077 \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10
-
2.2.3 Yarn模式
Standalone模式由Spark自身提供计算资源,但是因为其主要是计算框架,所以它本身提供的资源调度不是强项。在结合了Yarn后,Spark会更易用。
-
解压安装包
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/software cd /opt/software mv spark-3.0.0-bin-hadoop3.2 spark-yarn -
修改hadoop配置文件$HADOOP_HOME/etc/hadoop/yarn-site.xml,并分发给其他host
<property> <!-- 虚拟内存检查,默认打开,修改为关闭 --> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <!-- 物理内存检查,默认打开,修改为关闭 --> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> -
修改conf/spark-env.sh,添加JAVA_HOME和YARN_CONF_DIR配置
export JAVA_HOME=/opt/software/jdk1.8.0_201 YARN_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop -
重启hadoop集群
-
提交应用
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10 -
配置历史服务器
-
修改/conf/spark-defaluts.conf.template文件名为spark-defaults.conf
-
修改spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true spark.eventLog.dir hdfs://pc001:8082/spark/log_directory -
修改spark-env.sh文件,添加日志配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://pc001:8082/spark/log_directory -Dspark.history.retainedApplications=30" -
修改spark-defaults.conf文件
spark.yarn.historyServer.address=pc001:18080 spark.history.ui.port=18080 -
启动历史服务
sbin/start-history-server.sh
-
-
重新提交应用
./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.12-3.1.2.jar \ 10
2.3 部署模式的比较
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |
2.4 常用端口号
- Spark查看当前Spark-shell运行任务情况端口号:4040
- Spark Master内部通信服务端口号:7077
- Standalone模式下,Spark Master Web端口号:8989(防止和zookeeper的端口号8088重合)
- Spark历史服务器端口号:18080
- Hadoop Yarn任务运行情况查看端口号:8088
3、Spark核心编程
Spark计算框架封装了三大数据结构:
- RDD:弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
3.1 RDD
3.1.1 RDD的定义
RDD(Resilient Distributed Dataset):弹性分布式数据集,是Spark中最基本的数据处理模型,在代码中是一个抽象类,它代表一个弹性的、不可变的、可分区的、集合中元素可并行计算的集合。
-
弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分辨的弹性:可根据需要重新分片
-
分布式
数据存储在大数据集群不同节点上
-
数据集
RDD封装了计算逻辑,并不保存数据
-
数据抽象
RDD是一个抽象类,需要子类具体实现
-
不可变
RDD封装了计算逻辑,是不可改变的,如果想要改变只能产生新的RDD封装新的计算逻辑
-
可分区、并行计算
3.1.2 RDD的核心属性
RDD共有5个核心属性
# RDD.scala
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
-
分区列表
RDD数据结构中存在分区列表,用于执行任务时并行计算,为实现分布式计算的重要属性。
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protected def getPartitions: Array[Partition] -
分区计算函数
Spark在计算时,是使用分区函数对每一个分区进行计算
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T] -
RDD之间的依赖关系
RDD是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个RDD建立依赖关系
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps -
分区器
当数据为KV类型数据时,可以通过设定分区器自定义数据的分区
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None -
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
3.1.3 基础编程
3.1.3.1 RDD创建
在Spark中创建RDD可以分为4种:
-
从集合(内存)中创建RDD
通过parallelize和makeRDD创建RDD,makeRDD的底层是parallelize
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val ints: List[Int] = List(1, 2, 3, 4) val value: RDD[Int] = sc.makeRDD(ints,3) value.saveAsTextFile("datas/output") // 通过文件的方式,可以很直观的看到分区的方式 value.collect.foreach(println) sc.stop() } }对分区数的理解:
numSlices: Int = defaultParallelism // defaultParallelism的数为本机的最大CPU核心数对分区的理解:
-
def makeRDD
# SparkContext.scala def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices) } -
def parallelize
# SparkContext.scala def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { assertNotStopped() new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]()) }-
ParallelCollectionRDD
# ParallelCollectionRDD.scala # 1.对数据的读取规则,按seq的长度进行处理,返回每个分区的范围值 def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } } # 2.对读取数据的处理 case _ => val array = seq.toArray // To prevent O(n^2) operations for List etc positions(array.length, numSlices).map { case (start, end) => array.slice(start, end).toSeq }.toSeq
-
-
从外部存储(文件)创建RDD
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) // sc.textFile读取单个文件 // sc.wholeTextFiles读取文件夹里面的所有文件 val value: RDD[String] = sc.textFile("datas/test1.txt",3) value.saveAsTextFile("datas/output") value.collect.foreach(println) sc.stop() } }对分区的理解:
-
def textFile
# SparkContext.scala def textFile( path: String, minPartitions: Int = defaultMinPartitions): RDD[String] = withScope { assertNotStopped() hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions).map(pair => pair._2.toString).setName(path) }可以看到,spark读取文件的底层,所使用的方法来自于hadoop,且文件的读取方式为TextInputFormat按行读取
对分区数的理解:
minPartitions: Int = defaultMinPartitions = def defaultMinPartitions: Int = math.min(defaultParallelism, 2) defaultParallelism的数为本机的最大CPU核心数 -
TextInputFormat -> FileInputFormat.java
public InputSplit[] getSplits(JobConf job, int numSplits)中:
-
totalSize 为读取的文件的字节总和
-
goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // 表示每个分区存放的字节数
totalSize/goalSize = 分区的数量(需要注意TextInputFormat分区特性,大于1.1倍,则分区+1)
-
-
-
从其他RDD创建
主要是通过一个RDD运算完成后,再产生新的RDD
-
直接创建RDD(new)
使用new的方式直接构造RDD,一般由Spark框架自身使用
3.1.3.2 RDD并行度与分区
Spark可以将一个作业切分成多个任务后,发送给Executor节点并行计算,其能够并行计算的任务数量称之为并行度。
说明:并行执行的任务数量,并不是值的切分任务的数量。
3.1.3.3 算子简介
算子即为RDD方法,有两种模式:
- 转换算子:功能的补充和封装,将旧的RDD包装成新的RDD,如flatMap、map
- 行动算子:触发任务的调度和作业的执行,如collect
3.1.3.4 转换算子
RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型
3.1.3.4.1 Value类型
| 序号 | 函数 |
|---|---|
| 1 | map |
| 2 | mapPartitions |
| 3 | mapPartitionsWithIndex |
| 4 | flatMap |
| 5 | glom |
| 6 | groupBy |
| 7 | filter |
| 8 | sample |
| 9 | distinct |
| 10 | coalesce |
| 11 | repartition |
| 12 | sortBy |
-
map
-
定义
将处理的数据逐条进行映射转换,转换可以是类型的转换,也可以是值的转换
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val ints: List[Int] = List(1, 2, 3, 4) val value: RDD[Int] = sc.makeRDD(ints,3) val value1: RDD[Int] = value.map(_ * 2) value1.collect.foreach(println) sc.stop() } } -
获取文件中某列数据
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[String] = sc.textFile("datas/apache.log") val value1: RDD[String] = value.map((line) => { val strings: Array[String] = line.split(" ") strings(6) }) value1.collect.foreach(println) sc.stop() } }
-
-
mapPartitions
-
定义
将待处理的数据以分区为单位发送到计算节点进行处理。
-
mapPartitions与map在功能角度的区别:
- Map算子主要目的是将数据源中的数据进行转换和改变,但是不会减少或增多数据。
- MapPartitions算子需要传递一个迭代器,返回一个迭代器,没有要求元素的个数保持不变,可以增加或减少数据
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) // mapPartitions: 以分区为单位进行数据转换操作 // 但是会将整个分区的数据加载到内存进行引用 // 如果处理完的数据是不会被释放掉,存在对象的引用 // 在内存较小,数据量较大的场合下,容易出现内存溢出 val value1: RDD[Int] = value.mapPartitions((iter) => { iter.map(_ * 2) }) value1.collect.foreach(println) sc.stop() } } -
获取每个数据分区的最大值
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) // 获取每个数据分区的最大值 val value1: RDD[Int] = value.mapPartitions((iter) => { List(iter.max).iterator }) value1.collect.foreach(println) sc.stop() } }
-
-
mapPartitionsWithIndex
-
定义
将待处理的数据以分区为单位发送到计算节点进行处理,在处理的同时可以获取当前分区索引
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val value1: RDD[Int] = value.mapPartitionsWithIndex((index, iter) => { if (index == 1) { iter } else { Nil.iterator } }) value1.collect.foreach(println) sc.stop() } } -
获取分区号及数字
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val value1: RDD[(Int, Int)] = value.mapPartitionsWithIndex((index, iter) => { iter.map( (num) => { (index, num) } ) }) value1.collect.foreach(println) sc.stop() } }
-
-
flatMap
-
定义
将处理的数据进行扁平化后再进行映射处理,因此算子也称为扁平映射。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) // RDD[List[Int]] val value: RDD[List[Int]] = sc.makeRDD(List(List(1, 2, 3), List(3, 4, 7)), 2) val value1: RDD[Int] = value.flatMap( (list) => { list }) value1.collect.foreach(println) // RDD[String] val value2: RDD[String] = sc.makeRDD(List("hello world", "hello spark")) val value3: RDD[String] = value2.flatMap( (list) => { list.split(" ") } ) value3.collect().foreach(println) sc.stop() } } -
扁平化异构数据
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Any] = sc.makeRDD(List(List(1, 2), 3, List(4, 5))) // 说明:该写法报错,在这里只是说明可以使用模式匹配的方式处理数据 val value1: RDD[Nothing] = value.flatMap( (data) => { data match { case list: List[_] => list case _ => List(_) } }) value1.collect.foreach(println) sc.stop() } }
-
-
glom
-
定义
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val value1: RDD[Array[Int]] = value.glom() value1.collect().foreach((data)=>{println(data.mkString(","))}) sc.stop() } }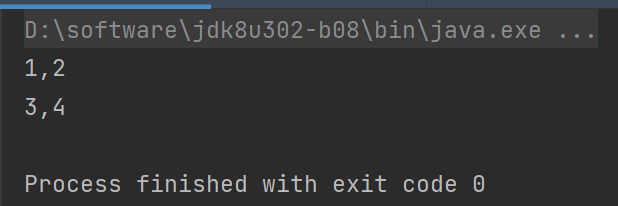
-
求分区内的最大值和
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val value1: RDD[Int] = value.glom().map( (array) => { array.max } ) println(value1.collect().sum) sc.stop() } }
-
-
groupBy
-
定义
将数据根据指定的规则进行分组,分区默认不变,但是数据会被打乱重新组合(shuffle过程),在极限的情况下,数据可能被分在同一个分区中。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2) val value1: RDD[(Int, Iterable[Int])] = value.groupBy((list) => { list % 2 }) value1.collect().foreach(println) sc.stop() } } -
将字符按照首字母进行分组
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[String] = sc.makeRDD(List("Hello", "hello", "Hbase", "Hadoop"), 2) val value1: RDD[(Char, Iterable[String])] = value.groupBy((list) => { list.charAt(0) }) value1.collect().foreach(println) sc.stop() } } -
统计频次
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import java.text.SimpleDateFormat import java.util.Date object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[String] = sc.textFile("datas/apache.log") val value1: RDD[(String, Int)] = value.map((line) => { val strings: Array[String] = line.split(" ") val date: String = strings(3) val format: SimpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") val date1: Date = format.parse(date) val format1 = new SimpleDateFormat("HH") val hour: String = format1.format(date1) (hour, 1) }).groupBy((tuple) => { tuple._1 }).map((tuple => { (tuple._1, tuple._2.size) })) value1.collect().foreach(println) sc.stop() } }
-
-
filter
-
定义
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。
说明:当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val value1: RDD[Int] = value.filter((list) => { list % 2 != 0 }) value1.collect().foreach(println) sc.stop() } }
-
-
sample
-
定义
根据指定的规则从数据集中抽取数据
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) /** * 情况一 value.sample(false, 0.5, 1) 抽取数据不放回(伯努利算法) 第一个参数:抽取的数据不放回:false 第二个参数,抽取的几率,范围在[0,1]之间,0表示全不取,1表示全取 第三个参数,随机数种子 * 情况二: value.sample(true,2,1) 抽取数据放回(泊松算法) 第一个参数:抽取的数据放回:true 第二个参数:重复数据的几率,范围大于等于0,表示每一个元素被期望抽取到的次数 第三个参数:随机数种子 * */ val value1: RDD[Int] = value.sample(false, 0.5, 1) value1.collect().foreach(println) sc.stop() } }
-
-
distinct
-
定义
将数据集中重复的数据去重
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,3,4,5)) // 底层的实现原理:case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1) val value1: RDD[Int] = value.distinct() value1.collect().foreach(println) sc.stop() } }
-
-
coalesce
-
定义
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率
说明:当Spark程序存在过多的小任务的时候,可以通过coalesce方法,收缩合并分区,减少分区的个数,减少任务调度成本。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3) /** * coalesce方法默认情况下不会将分区的数据打乱重新组合,这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜 * 如果想要让数据均衡,可以进行shuffle处理,即将coalesce的第二个参数设置为true */ val value1: RDD[Int] = value.coalesce(2) value1.saveAsTextFile("datas/output") sc.stop() } }
-
-
repartition
-
定义
该操作内部其实执行的时coalesce操作,参数shuffle的默认值为true。
说明:无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为都会经过shuffle过程。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),2) /** * repartition的底层为 coalesce(numPartitions, shuffle = true) */ val value1: RDD[Int] = value.repartition(3) value1.saveAsTextFile("datas/output") sc.stop() } }
-
-
sortBy
-
定义
该操作用于排序数据。
说明:在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为升序排列。排序后产生新的RDD的分区数与原RDD的分区数一致,中间存在shuffle的过程。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[Int] = sc.makeRDD(List(1,3,4,2,6,5),2) // sortBy方法可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式 // sortBy默认情况下,不会改变分区,但是会进行shuffle过程 val value1: RDD[Int] = value.sortBy((num) => { num },ascending=true) value1.saveAsTextFile("datas/output") sc.stop() } }
-
3.1.3.4.2 双Value类型
| 序号 | 函数 |
|---|---|
| 1 | intersection |
| 2 | union |
| 3 | substract |
| 4 | zip |
示例用法:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Memory {
def main(args:Array[String]):Unit={
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val rdd2: RDD[Int] = sc.makeRDD(List(3, 4, 5, 6))
// intersection 差集 [3,4]
val value: RDD[Int] = rdd1.intersection(rdd2)
println(value.collect().mkString(","))
// union 并集 [1,2,3,4,3,4,5,6] 不会去重
val value1: RDD[Int] = rdd1.union(rdd2)
println(value1.collect().mkString(","))
// subtract 差集 [1,2]
val value2: RDD[Int] = rdd1.subtract(rdd2)
println(value2.collect().mkString(","))
// zip 拉链 [(1,3),(2,4),(3,5),(4,6)]
val value3: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(value3.collect().mkString(","))
sc.stop()
}
}
3.1.3.4.3 Key-Value类型
| 序号 | 函数 |
|---|---|
| 1 | partitionBy |
| 2 | reduceByKey |
| 3 | groupByKey |
| 4 | aggregateByKey |
| 5 | foldByKey |
| 6 | combineByKey |
| 7 | sortByKey |
| 8 | join |
| 9 | leftOuterJoin |
| 10 | cogroup |
-
partitionBy
-
定义
将数据按照指定Partitioner重新进行分区。
说明:Spark默认的分区器是HashPartitioner
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(Int, String)] = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "cc"), (4, "dd")),2) val value1: RDD[(Int, String)] = value.partitionBy(new HashPartitioner(2)) value1.saveAsTextFile("datas/output") sc.stop() } }
-
-
reduceByKey
-
定义
将数据按照相同的Key对Value进行聚合
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4))) val value1: RDD[(String, Int)] = value.reduceByKey(_ + _) value1.collect().foreach(println) sc.stop() } }
-
-
groupByKey
-
定义
将数据源的数据根据Key对Value进行分组。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 1))) // val value1: RDD[(String, Iterable[(String, Int)])] = value.groupBy(_._1) /** * (a,CompactBuffer((a,1), (a,2), (a,3))) * (b,CompactBuffer((b,1))) */ // 将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组 // - 元组中的第一个元素就是key // - 元组中的第二个元素就是相同key的value集合 val value1: RDD[(String, Iterable[Int])] = value.groupByKey() /** * (a,CompactBuffer(1, 2, 3)) * (b,CompactBuffer(1)) */ value1.collect().foreach(println) sc.stop() } }
-
-
aggregateByKey
-
定义
将数据根据不同的规则进行分区内计算和分区间计算
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)),2) // aggregateByKey算子,函数柯里化,存在两个参数列表 // 1.第一个参数列表中的参数表示初始值 // 2.第二个参数列表中含有两个参数: // 2.1 第一个参数表示分区内的计算规则 // 2.2 第二个参数表示分区间的计算规则 val value1: RDD[(String, Int)] = value.aggregateByKey(0)( (x, y) => { math.max(x, y) }, (x, y) => { x + y } ) value1.collect().foreach(println) /** (a,6) */ sc.stop() } }
-
-
foldByKey
-
定义
当分区内计算规则和分区间计算规则相同时,aggregateByKey就可以简化为foldByKey
-
示例说明
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args:Array[String]):Unit={ val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)),2) val value1: RDD[(String, Int)] = value.foldByKey(0)(_ + _) value1.collect().foreach(println) /** (a,10) */ sc.stop() } }
-
-
combineByKey
-
定义
最通用的对key-value型RDD进行聚集操作的聚集函数,类似于aggregate(),combineByKey()允许用法返回值的类型与输入的初始值类型不一致。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 4), ("a", 3), ("a", 4), ("b", 1), ("b", 3)), 2) val value1: RDD[(String, (Int, Int))] = value.combineByKey( (v) => { (v, 1) }, (t: (Int, Int), v) => { (t._1 + v, t._2 + 1) }, (t1: (Int, Int), t2: (Int, Int)) => { (t1._1 + t2._1, t1._2 + t2._2) } ) val value2: RDD[(String, Int)] = value1.mapValues { case (num, int) => { num / int } } value2.collect().foreach(println) /* (b,2) (a,3) */ sc.stop() } }
-
-
join
-
定义
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素连接在一起的(K,(V,W))的RDD
-
示例说明
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc = new SparkContext(sparkConf) // 两个不同数据源的数据,相同的key的value会连接在一起,形成元组 val value1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 2))) val value2: RDD[(String, Int)] = sc.makeRDD(List(("a", 2), ("b", 4), ("c", 7))) val value3: RDD[(String, (Int, Int))] = value1.join(value2) value3.collect().mkString(",").foreach(print) println() // (a,(1,2)),(b,(2,4)),(c,(2,7)) // 如果两个数据源中key没有匹配上,那么数据不会出现在结果集中 val value4: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 2))) val value5: RDD[(String, Int)] = sc.makeRDD(List(("b", 4),("d",3))) val value6: RDD[(String, (Int, Int))] = value4.join(value5) value6.collect().mkString(",").foreach(print) println() // (b,(2,4)) // 如果两个数据源中key有多个相同的,会一次匹配,可能出现笛卡尔积 val value7: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 2))) val value8: RDD[(String, Int)] = sc.makeRDD(List(("a", 4),("a",3), ("b", 2))) val value9: RDD[(String, (Int, Int))] = value7.join(value8) value9.collect().mkString(",").foreach(print) // (a,(1,4)),(a,(1,3)),(b,(2,2)) sc.stop() } }
-
-
leftOuterJoin&rightOuterJoin
-
定义
左连接,右连接
-
-
cogroup
-
定义
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Itertable[V],Iterable[W]))类型的RDD
-
3.1.3.5 行动算子
| 序号 | 函数 |
|---|---|
| 1 | reduce |
| 2 | collect |
| 3 | count |
| 4 | first |
| 5 | take |
| 6 | takeOrdered |
| 7 | aggregate |
| 8 | fold |
| 9 | countByKey |
| 10 | save |
| 11 | foreach |
-
reduce
-
定义
聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val i: Int = value.reduce(_ + _) println(i) sc.stop() } }
-
-
collect
-
定义
采集RDD数据,以数组Array的形式返回数据集的所有元素
-
-
count
-
定义
返回RDD中的元素的个数
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val l: Long = value.count() println(l) sc.stop() } }
-
-
first
-
定义
返回RDD中的第一个元素
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val l: Long = value.first() println(l) sc.stop() } }
-
-
take
-
定义
返回一个由RDD的前n个元素组成的数组
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val ints: Array[Int] = value.take(2) println(ints.mkString(",")) sc.stop() } }
-
-
takeOrdered
-
定义
返回该RDD排序后的前n个元素组成的数组
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(3, 1, 4, 2), 2) val ints: Array[Int] = value.takeOrdered(3)(Ordering.Int.reverse) println(ints.mkString(",")) sc.stop() } }
-
-
aggregate
-
定义
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(3, 1, 4, 2), 2) val i: Int = value.aggregate(10)( _ + _, _ + _ ) println(i) sc.stop() } }
-
-
fold
-
定义
当分区间和分区内的规则一样,用fold以简化aggregate
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[Int] = sc.makeRDD(List(3, 1, 4, 2), 2) val i: Int = value.fold(10)(_ + _) println(i) sc.stop() } }
-
-
countByKey
-
定义
统计每种key的个数
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 1), ("b", 1))) val stringToLong: collection.Map[String, Long] = value.countByKey() println(stringToLong) sc.stop() } }
-
-
save相关算子
-
定义
将数据保存到不同的格式的文件中
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Memory RDD") val sc: SparkContext = new SparkContext(conf) val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 1), ("b", 1)), 1) value.saveAsTextFile("datas/test.txt") sc.stop() } }
-
-
foreach
-
定义
分布式遍历RDD中的每一个元素,调用指定函数。
-
3.1.3.6 RDD序列化
3.1.3.6.1 闭包检测
从计算的角度看,算子以外的代码都是在Driver端执行的,算子以内的代码都是在Executor端执行,因此在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果。
此时如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误。
因此需要在执行计算任务前,检测闭包内的对象是否可以进行序列化,这种操作被称为 闭包检测。
3.1.3.6.2 Kryo序列化框架
参考地址:https://github.com/EsotericSoftware/kryo
Java的序列化能够序列化任何的类,但是序列化后,对象的提交的字节多。Spark能够利用Kryo序列化机制,其速度为Serializable的10倍。
说明:即使使用Kryo序列化,也要继承Serializable接口。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Memory {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("Memory RDD")
.registerKryoClasses(Array(classOf[Searcher])) // 注册需要使用Kryo序列化的自定义类
val sc: SparkContext = new SparkContext(conf)
val value: RDD[String] = sc.makeRDD(Array("hello world", "Spark", "hello hadoop", "hqqq"))
val searcher: Searcher = new Searcher("h")
val value1: RDD[String] = searcher.getMatchedRDD1(value)
value1.collect().foreach(println)
sc.stop()
}
// class Searcher extends Serializable(val query:String){
// 声明也可以使用样例类替代
case class Searcher(val query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 针对与在方法内赋值的方式,即使Searcher类不继承Serializable,也能够完成序列化,因为q为方法内局部变量,不属于Searcher的属性
def getMatchedRDD2(rdd: RDD[String]): RDD[String] = {
val q: String = query
rdd.filter(_.contains(q))
}
}
}
3.1.3.7 RDD依赖关系
3.1.3.7.1 RDD血缘关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作将会被统计入血缘依赖。
Spark能将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。
RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
value = sc.makeRDD(...)
println(value.toDebugString) // 能通过RDD.toDebugString,获取血缘关系
3.1.3.7.2 依赖关系
两个相邻RDD之间的关系,即为依赖关系。
value = sc.makeRDD(...)
println(value.dependencies) // 能通过RDD.dependencies,获取本次RDD于上次RDD之间的关系
-
RDD窄依赖
窄依赖表示,每一个上游RDD的Partition,最多被,下游RDD的一个Partition使用。即OneToOneDependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) -
RDD宽依赖
宽依赖表示,同一个上游RDD的Partition,被多个,下游RDD的Partition依赖,会引起Shuffle。即ShuffleDependency。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](...)
3.1.3.7.3 RDD阶段划分
DAG有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会产生闭环。
下图的DAG记录了RDD的转换过程和任务的阶段:
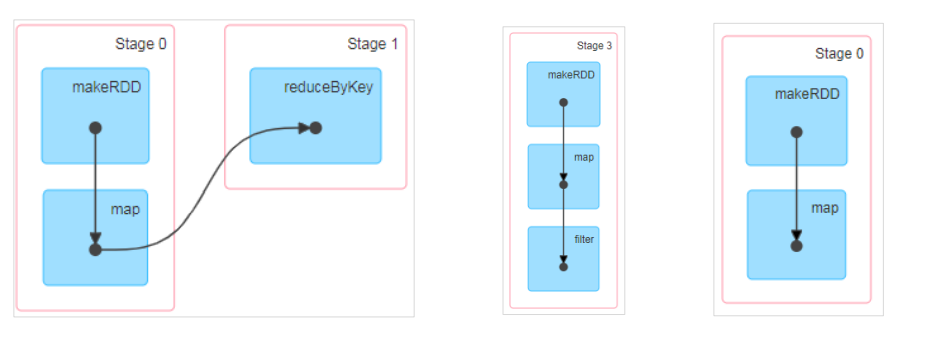
3.1.3.7.4 RDD任务划分
RDD任务切分中间分为:Application、Job、Stage和Task:
- Application:初始化一个SparkContext即会生成一个Application
- Job:一个Action算子就会生成一个Job
- Stage:Stage等于宽依赖(ShuffleDependency)的个数加1
- Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数
说明:Application -> Job -> Stage -> Task 每一层都是1对n的关系。
3.1.3.7 持久化
3.1.3.7.1 cache&persist
-
RDD Cache缓存
-
说明
RDD通过Cache方法将前面的计算结果缓存,数据在默认情况下缓存在JVM的堆内存中。
Cache方法被调用时不会立即缓存,而是触发了后面的action算子时,该RDD将会被缓存在计算节点的内存中,使其能被后面重用。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory") val sc: SparkContext = new SparkContext(conf) val value: RDD[String] = sc.makeRDD(Array("hello spark", ("hello scala"))) val value1: RDD[String] = value.flatMap(_.split(" ")) val value2: RDD[(String, Int)] = value1.map((word)=>{ println("*************") (word, 1) }) // cache将数据直接缓存在JVM内存中 value2.cache() // 将RDD.cache() 注释后,会发现,reduceByKey与groupByKey,分别都执行了start的RDD,因为RDD的transaction算子只是执行的步骤, // 并不存在数据的缓存,当action算子触发了操作后,数据才会进行处理。 val value3: RDD[(String, Int)] = value2.reduceByKey(_ + _) val value4: RDD[(String, Iterable[Int])] = value2.groupByKey() value3.collect().foreach(println) value4.collect().foreach(println) sc.stop() } }
-
-
RDD Persist缓存
-
说明
RDD通过Persist方法将前面的计算结果缓存,数据在默认情况下缓存在JVM的堆内存中。
Persist方法被调用时不会立即缓存,而是触发了后面的action算子时,该RDD将会被缓存在计算节点的内存中,使其能被后面重用。
-
Persist的存储级别
object StorageLevel { val NONE = new StorageLevel(false, false, false, false) val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) // 2表示副本的数量 val DISK_ONLY_3 = new StorageLevel(true, false, false, false, 3) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) // ser表示序列化 val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(true, true, true, false, 1)级别 使用的空间 CPU时间 是否存在内存中 是否在磁盘中 备注 MEMORY_ONLY 高 低 是 否 MEMORY_ONLY_SER 低 高 是 否 MEMORY_AND_DISK 高 中等 部分 部分 如果数据在内存放不下,则溢写到磁盘上 MEMORY_AND_DISK_SER 低 高 部分 部分 如果数据在内存中放不下,则溢写到磁盘上,在内存中存放序列化后的数据 DISK_ONLY 低 高 否 是 -
其他
一般而言,当存储于内存的数据由于内存不足被删除时,缓存可能会丢失。RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行:通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,不需要重算全部的Partition。
虽然Spark为了当一个节点Shuffle失败了避免重新计算整个输入,会自动对一些Shuffle操作的中间数据做持久化操作(如:reduceByKey),但是在实际使用的时候想重用数据,仍然建议调用persist或cache。
-
3.1.3.7.2 RDD CheekPoint检查点
-
说明
RDD CheekPoint检查点,即通过将RDD中间结果写入磁盘,减少血缘依赖过长造成的过高容错成本,当检查点后的节点出现问题,可以从检查点开始重做血缘,减少开销。
对RDD进行checkpoint操作后不会马上被执行,必须执行Action操作才能触发。
-
示例用法
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory") val sc: SparkContext = new SparkContext(conf) // 设置检查点路径 sc.setCheckpointDir("datas/checkpoint1") // 数据准备 val value: RDD[String] = sc.makeRDD(Array("hello spark", "hello scala"),2) // wordcount统计 val value1: RDD[String] = value.flatMap(_.split(" ")) val value2: RDD[(String, Int)] = value1.map((word)=>{ (word, 1) }) // 增加缓存,避免再重新跑一个job做checkpoint value2.cache() // 数据检查点:针对value2做检查点计算 value2.checkpoint() // 触发执行逻辑 value2.collect().foreach(println) sc.stop() } }
3.1.3.7.3 缓存和检查点区别
-
Cache缓存只是将数据保存起来,不切断血缘依赖。
CheckPoint检查点切断血缘依赖。
-
Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。
CheckPoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。9
-
建议对CheckPoint()的RDD使用的Cache缓存,这样CheckPoint的job只需要从Cache缓存中读取数据即可,否则需要再冲头计算一次RDD。
3.1.3.8 RDD分区器
-
说明
Spark目前支持Hash分区和Range分区,用户自定义分区。
- Hash分区为当前的默认分区
- 分区器直接决定了RDD中分区的个数
- RDD中每条数据经过Shuffle后进入哪个分区,进而决定了Reduce的个数
-
Hash分区
对于给定的Key,计算其hashCode并除以分区个数取余
-
Range分区
将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
-
自定义分区
自定义分区需要继承Partitioner类,并实现numPartitions和getPartition方法
import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext} object RDD_Memory { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory") val sc: SparkContext = new SparkContext(conf) // 数据准备 val value: RDD[String] = sc.makeRDD(Array("hello spark", "hello hadoop", "hello flume")) // wordcount统计 val value1: RDD[String] = value.flatMap(_.split(" ")) val value2: RDD[(String, Int)] = value1.map((word) => { (word, 1) }) val value3: RDD[(String, Int)] = value2.partitionBy(new MyPartition) value3.saveAsTextFile("datas/partition_test") sc.stop() } class MyPartition extends Partitioner { override def numPartitions: Int = 3 override def getPartition(key: Any): Int = { key match { case "hello" => 0 case "spark" => 1 case _ => 2 } } } }
3.1.3.9 RDD文件读取与保存
-
说明
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式及文件系统
- 文件格式分为:text文件、csv文件、sequence文件以及Object文件
- 文件系统分为:本地文件系统、HDFS、HBASE以及数据库
-
text文件
// 读取文件 sc.textFile(...) // 保存文件 xxxRDD.saveAsTextFile(...) -
sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(FlatFile)。在SparkContext中,可以调用sequenceFile[KeyClass,valueClass](path)来读取文件。
// 读取文件 sc.sequenceFile[Int,Int](...) // 保存文件 xxxRDD.saveAsSequenceFile(...) -
object对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。可以通过objectFile[T:ClassTag](path)函数接收一个路径,读取对象文件,返回对应的RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。
// 读取文件 sc.objectFile[Int](...) // 要读取序列化的文件,需要指定类型 // 保存数据 xxxRDD.saveAsObjectFIle(...)
3.2 累加器
3.2.1 实现原理
累加器为分布式只写变量,累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
3.2.2 系统累加器
系统累加器有longAccumulator、doubleAccumulator及collectionAccumulator。
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Memory {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)
val sum: LongAccumulator = sc.longAccumulator("sum")
value.foreach(
(num) => {
// 使用累加器
sum.add(num)
}
)
println(sum.value)
sc.stop()
}
}
3.2.3 自定义累加器
自定义累加器需要继承AccumulatorV2,并设定泛型,重写其中的抽象方法。
import org.apache.spark.rdd.RDD
import org.apache.spark.util.{AccumulatorV2, LongAccumulator}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object RDD_Memory {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[String] = sc.makeRDD(List("hello","spark","hello"))
// 创建累加器对象
val accumulator: MyAccumulator = new MyAccumulator()
// 向Spark进行注册
sc.register(accumulator,"wordCountAccumulator")
value.foreach(
(word) =>{
accumulator.add(word)
}
)
println(accumulator.value)
sc.stop()
}
/**
* 继承AccumulatorV2,需要定义泛型
* IN:累加器输入的数据类型
* Out:累加器返回的数据类型
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Int]]{
private var map: mutable.Map[String, Int] = mutable.Map()
override def isZero: Boolean = {
// 累加器是否为初始状态
map.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {
new MyAccumulator()
}
override def reset(): Unit = {
map.clear()
}
override def add(v: String): Unit = {
// 向累加器中增加数据(In)
// 查询map中是否存在相同的单词
// 如果有相同的单词,那么单词的数量+1
// 如果没有相同的单词,那么在map中增加这个单词
map(v) = map.getOrElse(v,0) + 1
}
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
// 合并累加器
val map1: mutable.Map[String, Int] = map
val map2: mutable.Map[String, Int] = other.value
// 两个Map的合并
map2.foreach{
case (word,count) => {
val newCount: Int = map1.getOrElse(word,0) + count
map1.update(word,newCount)
}
}
}
override def value: mutable.Map[String, Int] = {
// 获取累加器的结果
map
}
}
}
3.3 广播变量
3.3.1 实现原理
广播变量用来高效分发较大的对象,向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用
说明:在多个并行操作中使用同一个变量,Spark会为每个任务分别发送
3.3.2 使用示例
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object RDD_Memory {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD Memory")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
// 创建map值
val map: mutable.Map[String, Int] = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 将map封装成广播变量
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
value.map{
case (w,c) => {
val i: Int = bc.value.getOrElse(w, 0)
(w,(c,i))
}
}.collect().foreach(print)
/**
* 结果:(a,(1,4)),(b,(2,5)),(c,(3,6))
*/
sc.stop()
}
}
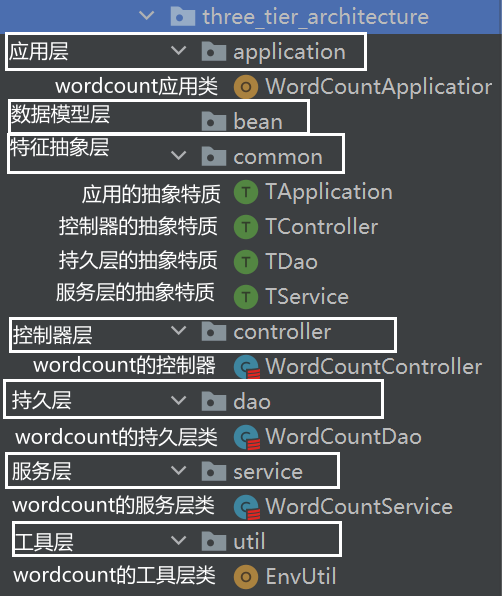
4、数据开发三层架构
三层架构主要是:controller(控制层)、service(服务层)、dao(持久层)
- controller:控制层,用来写数据处理程序的控制流程
- service:服务层,用来写业务代码
- dao:持久层,负责进行数据交互操作
示例结构:
application
WordCountApplication.scala
# WordCountApplication.scala
package three_tier_architecture.application
import org.apache.spark.{SparkConf, SparkContext}
import three_tier_architecture.common.TApplication
import three_tier_architecture.controller.WordCountController
object WordCountApplication extends App with TApplication{
start(){
val controller = new WordCountController()
controller.dispatch()
}
}
bean
暂无
common
TApplication.scala
# TApplication.scala
package three_tier_architecture.common
import org.apache.spark.{SparkConf, SparkContext}
import three_tier_architecture.controller.WordCountController
import three_tier_architecture.util.EnvUtil
trait TApplication {
def start(master:String="local[*]",name:String="Application")(op: => Unit): Unit ={
val conf: SparkConf = new SparkConf().setMaster(master).setAppName(name)
val sc: SparkContext= new SparkContext(conf)
EnvUtil.put(sc)
// 对代码的抽象
try {
op
} catch {
case ex: Exception => ex.printStackTrace()
}
sc.stop()
EnvUtil.clear()
}
}
TController.scala
# TController.scala
package three_tier_architecture.common
trait TController {
def dispatch():Unit
}
TDao.scala
# TDao.scala
package three_tier_architecture.common
import org.apache.spark.rdd.RDD
import three_tier_architecture.util.EnvUtil
trait TDao {
def read_text_file(): RDD[String] ={
val value: RDD[String] = EnvUtil.take().textFile("datas/test.txt")
value
}
}
TService.scala
# TService.scala
package three_tier_architecture.common
trait TService {
def analyze_data():Any
}
controller
WordCountController.scala
# WordCountController.scala
package three_tier_architecture.controller
import three_tier_architecture.common.TController
import three_tier_architecture.service.WordCountService
class WordCountController extends TController {
private val wordcount_service = new WordCountService()
override def dispatch(): Unit = {
// 控制业务操作逻辑
val tuples: Array[(String, Int)] = wordcount_service.analyze_data()
tuples.foreach(println)
}
}
dao
WordCountDao.scala
# WordCountDao.scala
package three_tier_architecture.dao
import three_tier_architecture.common.TDao
class WordCountDao extends TDao{
}
service
WordCountService.scala
# WordCountService.scala
package three_tier_architecture.service
import org.apache.spark.rdd.RDD
import three_tier_architecture.common.TService
import three_tier_architecture.dao.WordCountDao
class WordCountService extends TService{
private val wordcount_dao: WordCountDao = new WordCountDao()
override def analyze_data():Array[(String,Int)]={
// 操作业务
val value: RDD[String] = wordcount_dao.read_text_file()
val tuples: Array[(String, Int)] = value.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect()
tuples
}
}
util
EnvUtil.scala
# EnvUtil.scala
package three_tier_architecture.util
import org.apache.spark.SparkContext
object EnvUtil {
private val scLocal = new ThreadLocal[SparkContext]()
def put(sc:SparkContext):Unit = {
scLocal.set(sc)
}
def take():SparkContext = {
scLocal.get()
}
def clear():Unit = {
scLocal.remove()
}
}
5、SparkSQL核心编程
-
说明
Spark Core中,如果需要执行应用程序,首先需要构建上下文环境对象SparkContext。
Spark SQL是对Spark Core的一种封装,包括模型的封装,及上下文环境。
SparkSQL的查询起始点:
-
老的环境
- 一个为SQLContext,用于Spark自己提供的SQL查询
- 一个为HiveContext,用于连接Hive的查询
-
新的环境
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样可以使用。
SparkSession内部封装了SparkContext,所以计算实际上是由sparkContext完成的。
当使用Spark-shell的是时候,spark框架会自动的创建一个名称叫做spark的SparkSession对象,而sc所指的对象为SparkContext。
-
5.1 DataFrame
-
定义
SparkSQL通过DataFrameAPI的transformation操作和action操作,直接使用DataFrame而不用必须去注册临时表或者生成SQL表达式。
5.1.1 DataFrame的创建
说明:在SparkSQL中,SparkSession是创建DataFrame和执行SQL的入口。
创建DataFrame的三种方式:
- 通过Spark的数据源进行创建
- 从一个存在的RDD进行转换
- 从HiveTable进行查询返回
5.1.1.1 从Spark的数据源进行创建DataFrame
-
数据准备
# 1.josn {"username":"zhangshan","age":20} {"username":"wangwu","age":10} {"username":"lisi","age":30} {"username":"zhaoliu","age":30} -
查看Spark支持创建文件的数据源格式

-
读取
josn文件创建DataFramescala> spark.read.json("/home/nuochengze/test/1.json") res3: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
说明:(1)如果从内存中获取数据,spark可以指导数据类型具体是什么,如果是数字,默认作Int处理。
(2)如果从文件中读取的数字,不能确定是什么类型,所以用bigint接收,可以和Long类型转换
-
展示结果
scala> spark.read.json("/home/nuochengze/test/1.json") res3: org.apache.spark.sql.DataFrame = [age: bigint, username: string] scala> val df = spark.read.json("/home/nuochengze/test/1.json") df: org.apache.spark.sql.DataFrame = [age: bigint, username: string] scala> df.show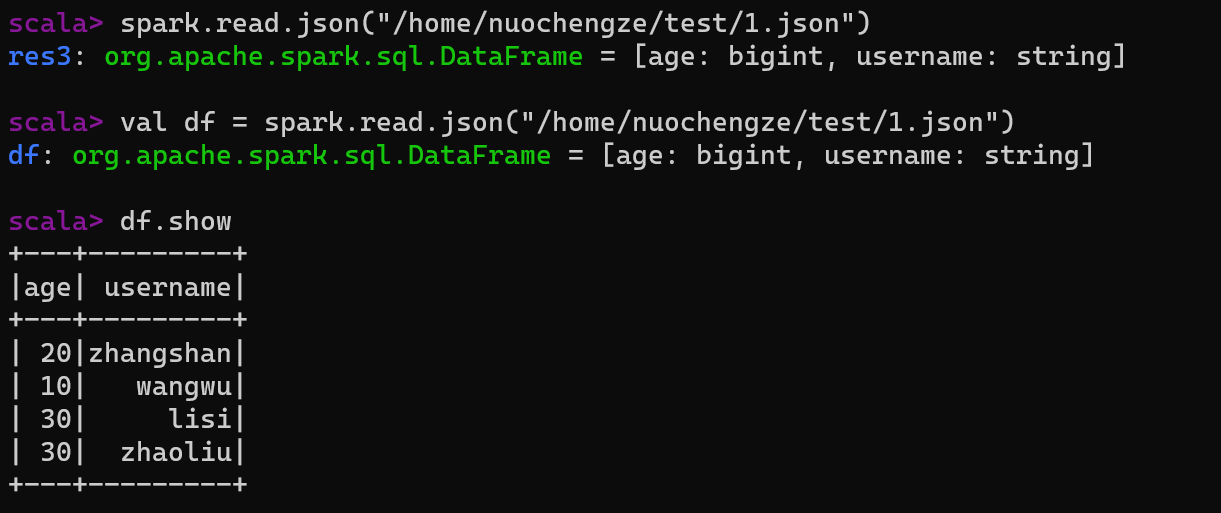
5.1.1.2 从一个存在的RDD转换成DataFrame
说明:
- 在IDEA中开发程序时,如果需要RDD与DF或者DS之间互相操作,需要引入
import spark.implicits._。 - 这里的
spark不是scala中的包名,而是创建的sparkSession对象的变量名称,所以必须先创建SparkSession对象再导入。 - 这里的spark对象不能使用var声明,即Scala只支持val修饰的对象的引入。
RDD和DataFrame之间的区别在于,RDD中只有数据,DataFrame存在数据列的名称:
-
准备文件
# 2.txt 1 2 3 4 -
创建RDD
scala> val idRDD = sc.textFile("/home/nuochengze/test/2.txt") idRDD: org.apache.spark.rdd.RDD[String] = /home/nuochengze/test/2.txt MapPartitionsRDD[3] at textFile at <console>:24
-
给RDD的数据准备列名,转换成DataFrame
scala> val id_df = idRDD.toDF("id") id_df: org.apache.spark.sql.DataFrame = [id: string]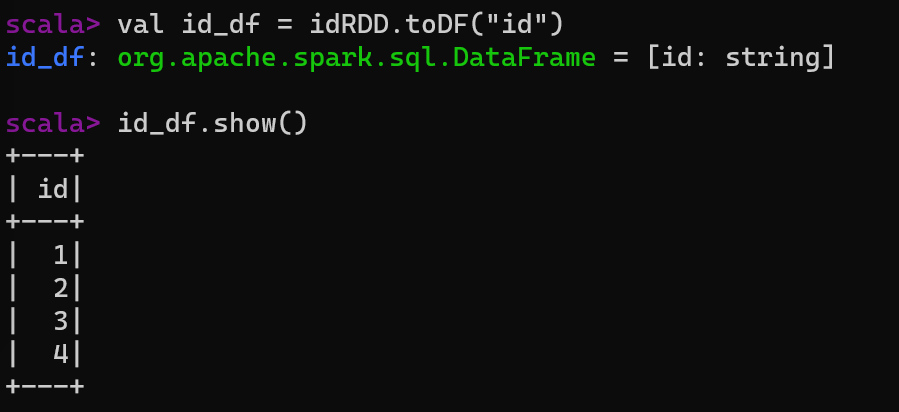
在实际的开发中,一般通过样例类将RDD转换为DataFrame:
-
创建样例类
scala> case class User(val name:String,val age:Int) defined class User -
构建RDD[User]
scala> val dataRDD = sc.makeRDD(List(("zhangsan",20),("lisi",30),("wangwu",25))).map(t=>User(t._1,t._2)) dataRDD: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[36] at map at <console>:26 -
将RDD[User]转换成DataFrame
dataRDD.toDF.show
5.1.1.3 从HiveTable进行查询返回
5.1.2 DataFrame与RDD之间的转化
5.1.2.1 RDD转化为DataFrame
[5.1.1.2 从一个存在的RDD转换成DataFrame](#5.1.1.2 从一个存在的RDD转换成DataFrame)
5.1.2.2 DataFrame转换为RDD
DataFrame其实就是对RDD的封装,所以可以直接获取内部的RDD:
scala> df.rdd

注意:从DataFrame转换为RDD,得到的RDD存储类型为Row
5.2 DataSet
说明:DataSet为具有强类型的数据集合,需要提供对应的类型信息。
创建DataSet有两种方式:
- 使用样例类序列创建DataSet
- 使用基本类型的序列创建DataSet
5.2.1 DataSet的创建
说明:在实际使用中,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet。
5.2.1.1 使用样例类序列创建DataSet
-
创建样例类
case class Person(val name:String,val age:Long) -
将Seq转换为DataSet
scala> val seqData = Seq(Person("wangwu",20),Person("lisi",30),Person("zhaoliu",45))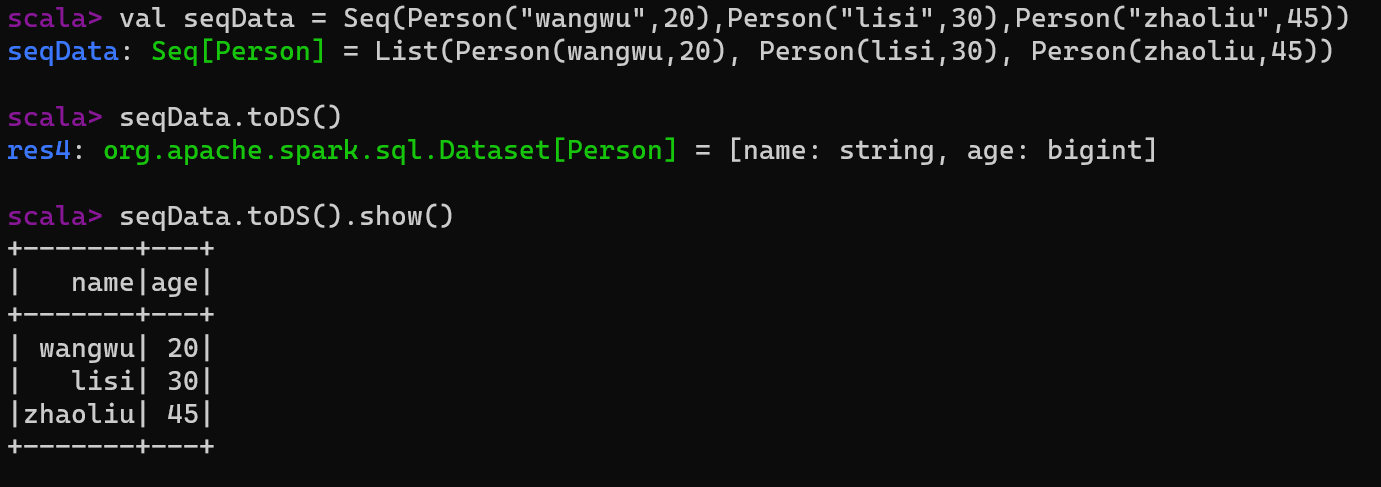
5.2.1.2 使用基本类型的序列创建DataSet
scala> val dsData = Seq(1,2,3,4,5).toDS
dsData: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> dsData.show()
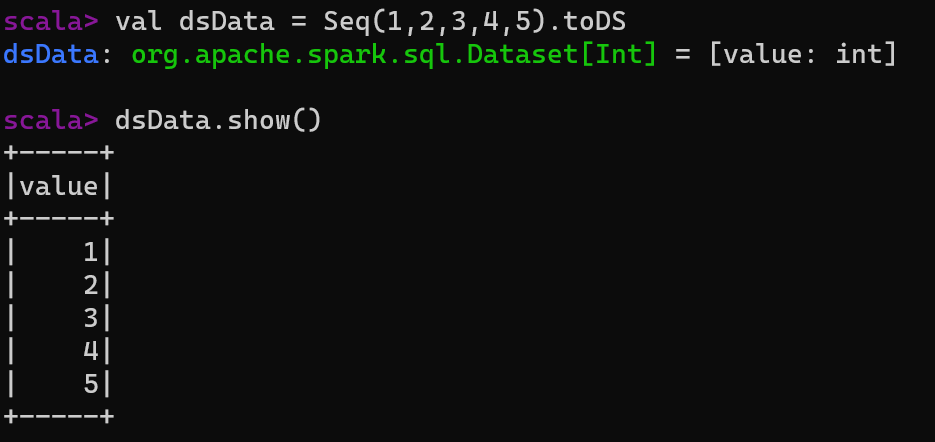
5.2.2 DataSet与RDD之间的转化
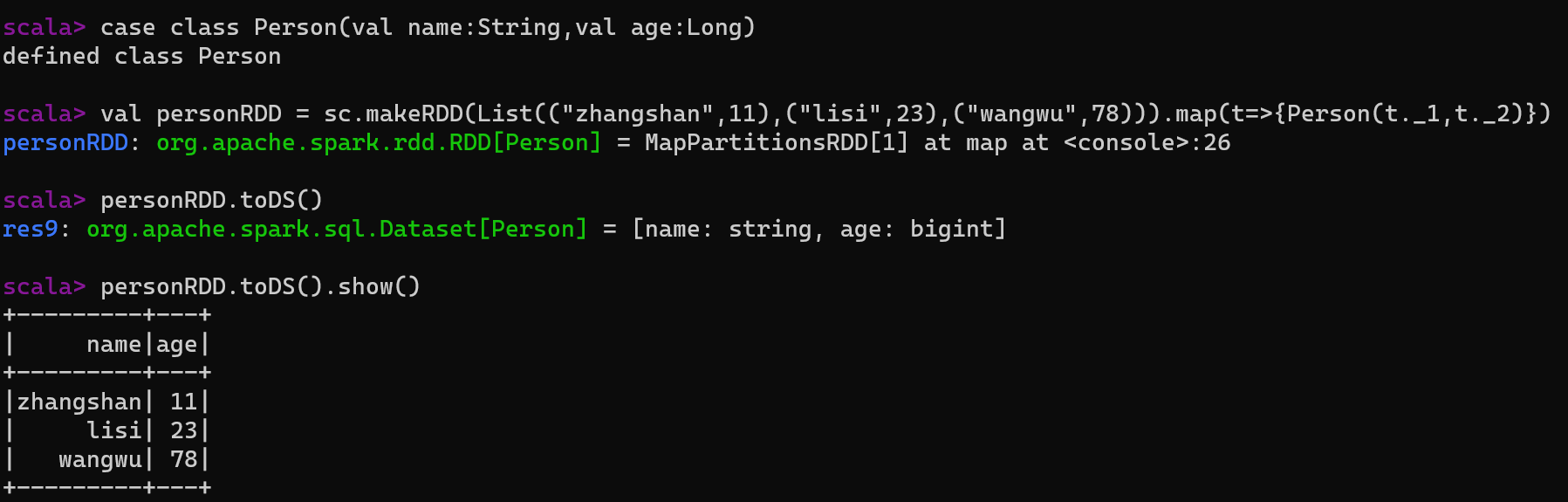
5.2.2.1 RDD转换为DataSet
说明:
- SparkSQL能够自动将包含有case类的RDD转换为DataSet,case类定义了table的结构,case类属性通过反射变成了表的列名。
- Case类可以包含诸如Seq或者Array等复杂的结构
5.2.2.2 DataSet转换为RDD
说明:DataSet其实也是对RDD的封装,可以直接获取内部的RDD
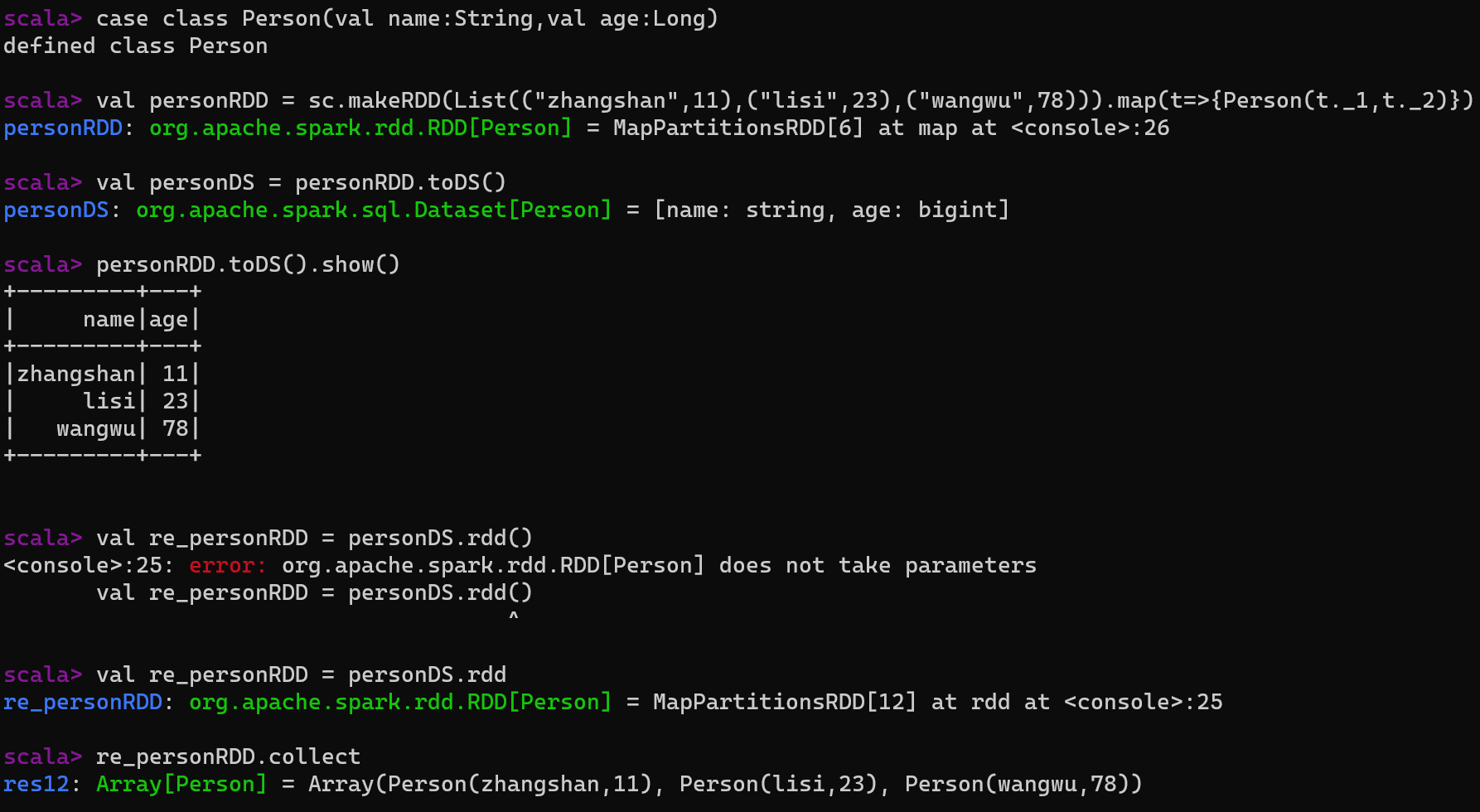
5.3 DataFrame与DataSet转换
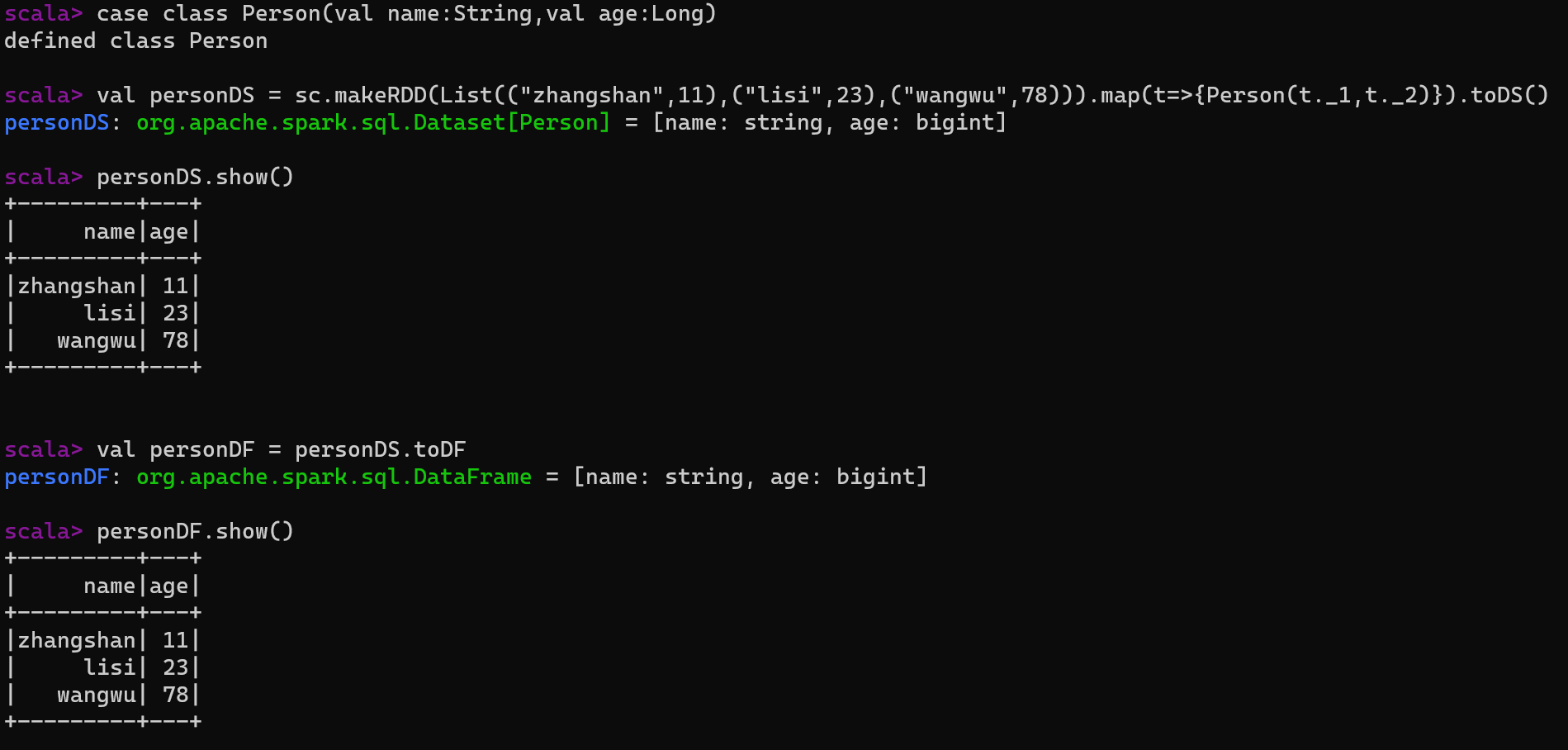
说明:DataFrame其实也是DataSet的特例,所以它们之间可以互相转换。
5.3.1 DataSet转换为DataFrame
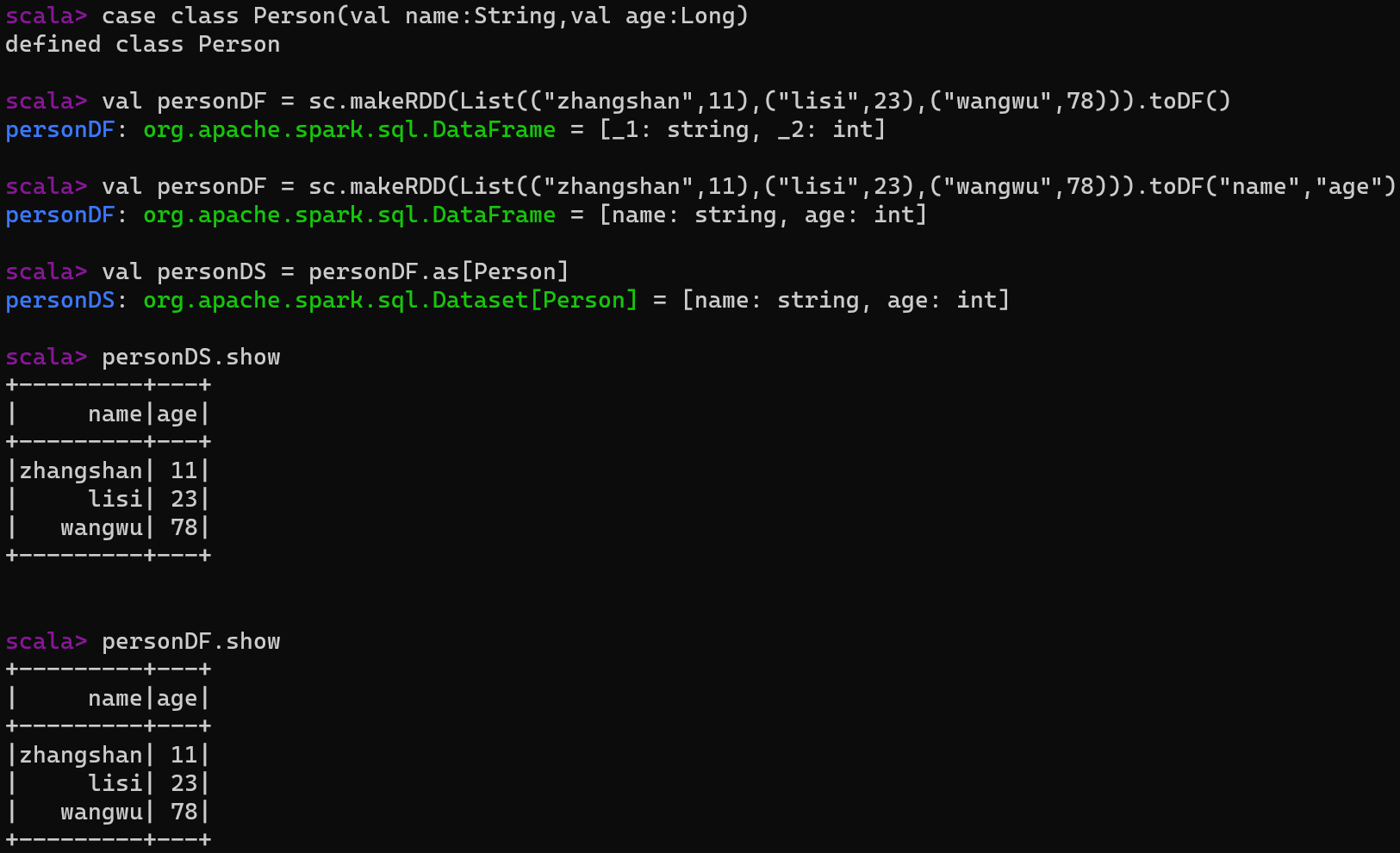
5.3.2 DataFrame转换为DataSet
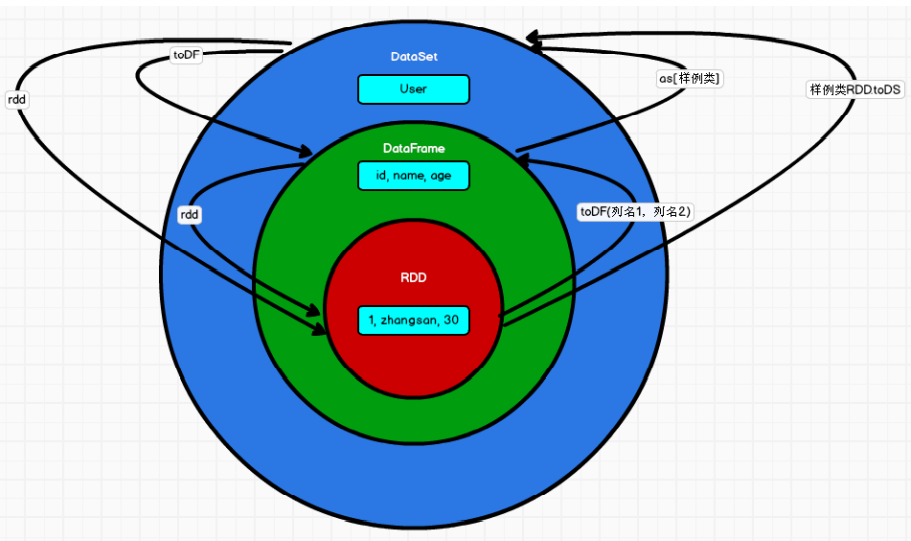
5.4 RDD、DataFrame、DataSet三者的关系
版本的产生:
- Spark1.0 => RDD
- Spark1.3 => DataFrame
- Spark1.6 => DataSet
5.4.1 RDD、DataFrame、DataSet的共性
-
三者全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
-
三者都有惰性机制,在进行创建、转换,如果map方法时,不会立即执行,只有在遇到了Action如foreach时,三者才会开始遍历运算
-
三者有许多共通的函数,如filter、排序等
-
在对DataFrame和DataSet进行操作时,许多操作都需要这个包:
import spark.implicits._在创建好SparkSession对象后尽量直接导入
-
三者都会根据Spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
-
三者都有partition的概念
-
DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型
5.4.2 RDD、DataFrame、DataSet的区别
-
RDD
- RDD一般和spark mllib同时使用
- RDD不支持sparksql操作
-
DataFrame
- 与RDD和DataSet不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
- DataFrame与DataSet,一般不与spark mllib同时使用
- DataFrame与DataSet均支持SparkSQL的操作,比如select、groupby之类,还能注册临时表/视窗,进行SQL语句操作
- DataFrame与DataSet支持一些特别方便的保存方式,比如保存成csv,可以带上头,这样每一列的字段名一目了然
-
DataSet
-
DataSet和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame其实就是DataSet的一个特例:
type DataFrame = DataSet[Row] -
DataFrame也可以叫作DataSet[Row],每一行的类型都是Row,不能解析,每一行的字段与类型无法配对获取,只能用getAS方法或者模式匹配拿出特定字段。
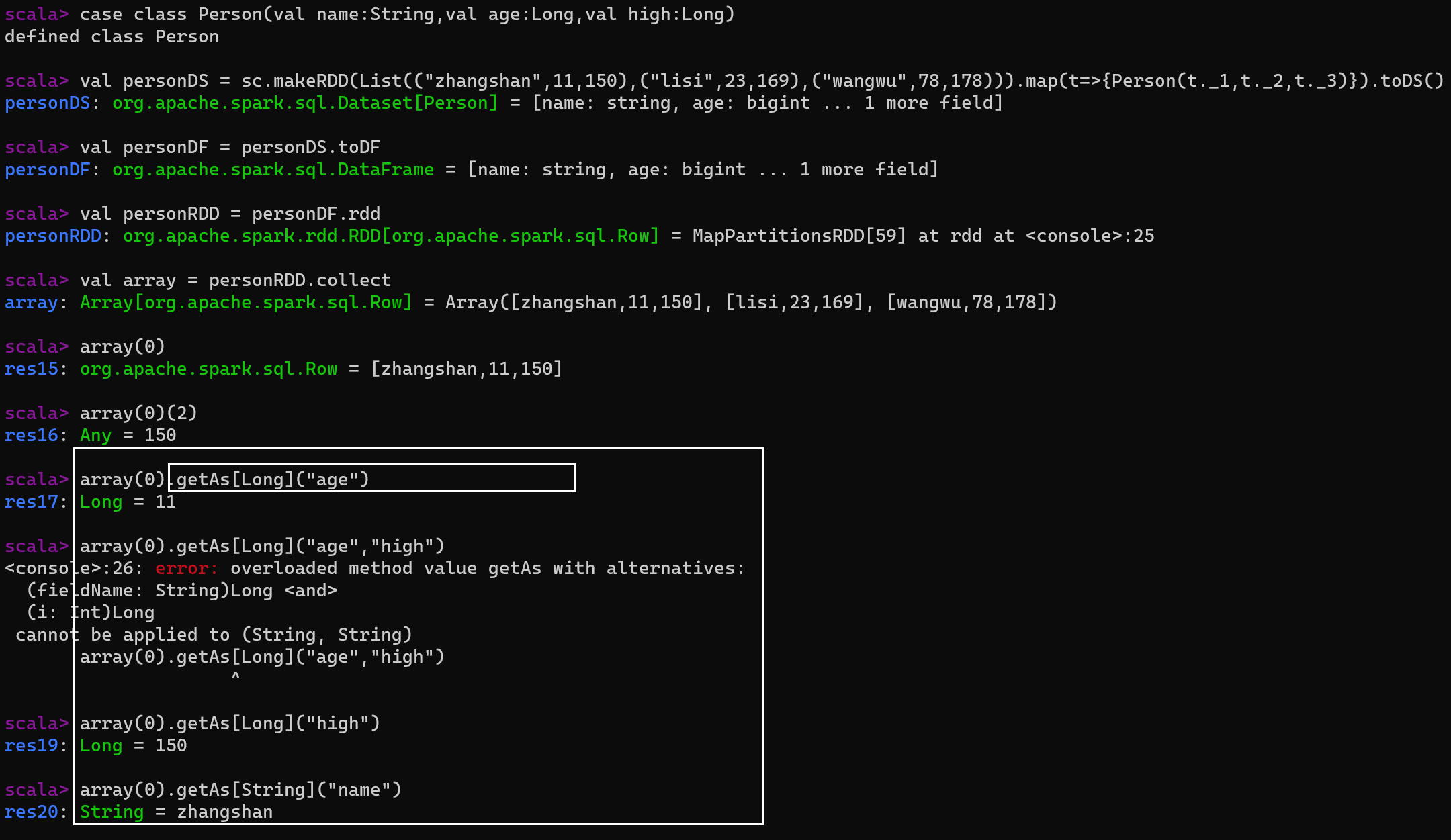
DataSet的每一行是什么类型虽然不能确定,但是在自定义了case class之后可以很自由的得获每一行的信息。
-
5.4.3 RDD、DataFrame、DataSet的互相转换
5.5 SQL语法
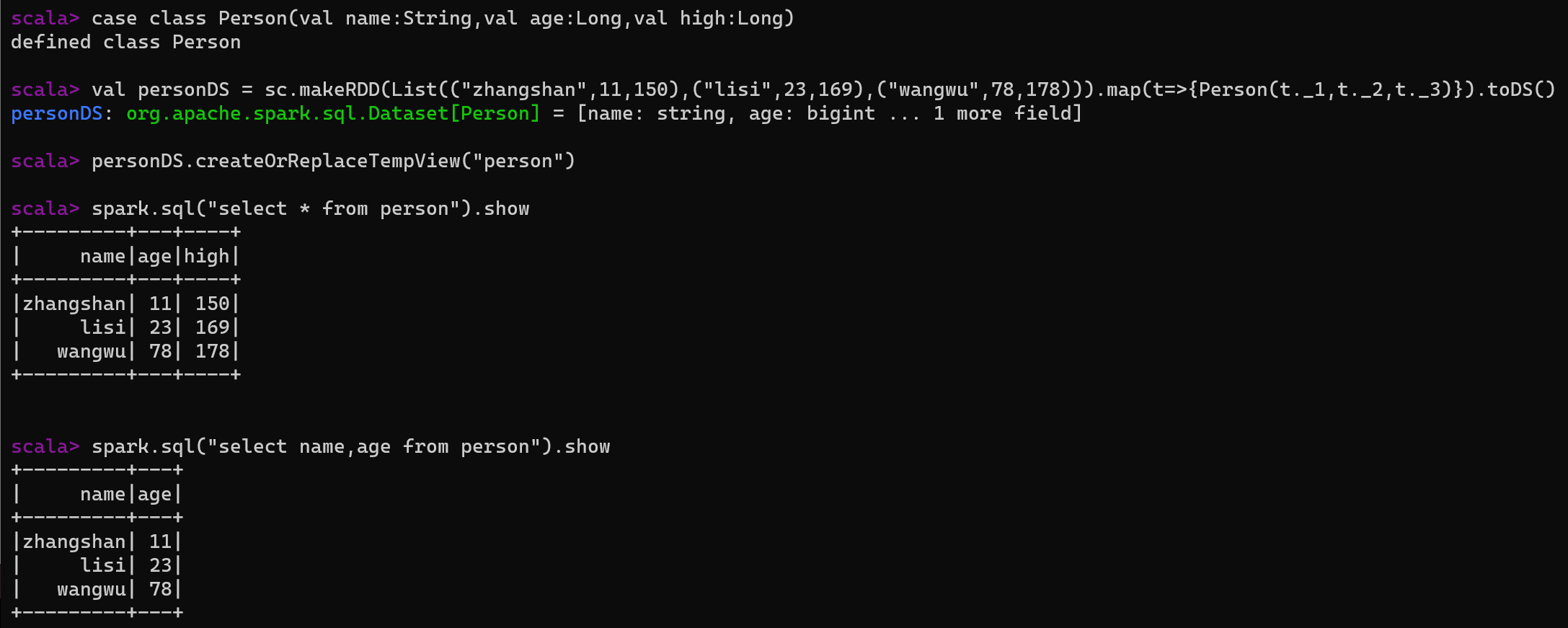
说明:
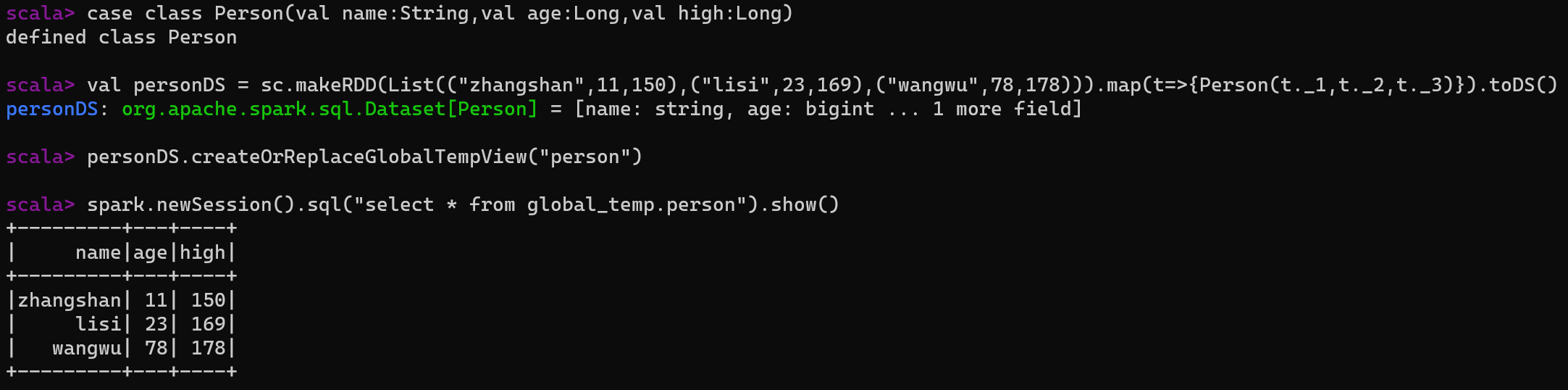
- SQL语法风格指查询数据的时候使用SQL语句来查询,但是这种风格的查询必须要有临时视图或者全局视图来辅助。
- 普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表
- 使用全局临时表时需要全路径访问,如 global_temp.person
- 报错解决
-
创建临时视图
-
创建全局视图
5.6 DSL语法
说明:
- DataFrame提供了一个特定领域语言(domain-specific language,DSL)去管理结构化的数据。
- 使用DSL语法风格不必去创建临时试图。
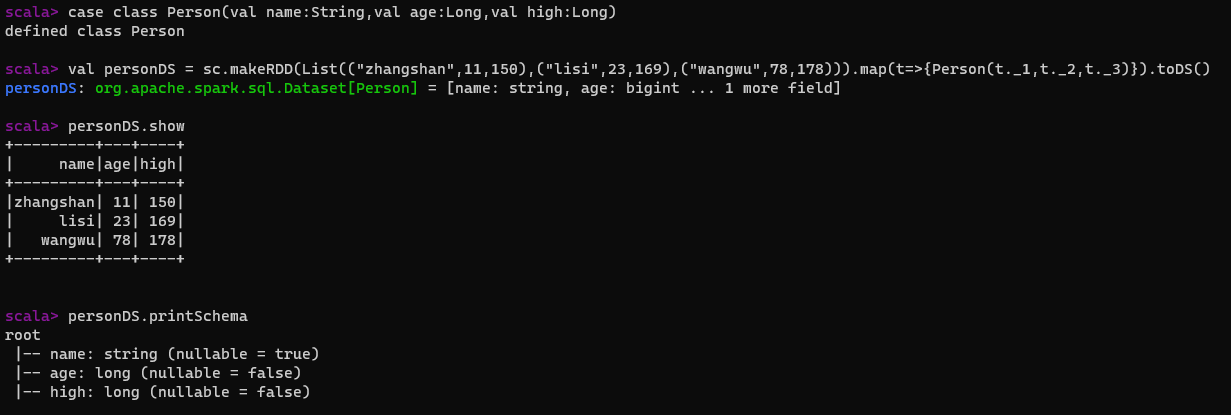
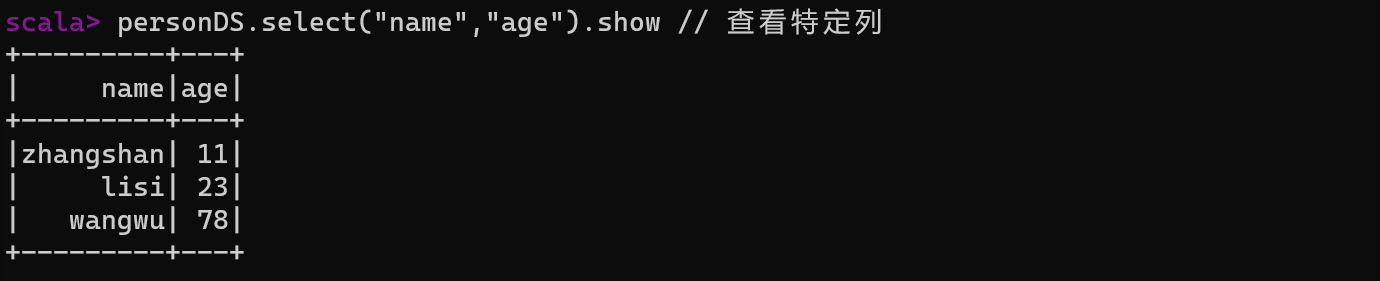

注意:在涉及到运算的时候,每列都必须使用$,获取采用引号表达式:单引号+字段名


5.7 IDEA开发SparkSQL
5.7.1 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
5.7.2 IDEA操作API示例
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object LocalSql {
def main(args:Array[String]):Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
val value: RDD[(String, Int, Int)] = sc.makeRDD(List(("zhangsan", 12, 176), ("lisi", 24, 180), ("wangwu", 43, 165)))
// 1. RDD => DataFrame
println("******************1. RDD => DataFrame:")
val frame: DataFrame = value.toDF("name","age","high")
frame.show()
// 2. RDD => DataSet
println("******************2. RDD => DataSet:")
val value1: RDD[Person] = value.map(t => {
Person(t._1, t._2, t._3)
})
val value2: Dataset[Person] = value1.toDS()
value2.show()
//...
spark.close()
}
case class Person(val name:String,val age:Int,val high:Int)
}
5.7.3 用户自定义函数
说明:可以通过spark.udf功能添加自定义函数,实现自定义功能。
5.7.3.1 创建UDF函数
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object LocalSql {
def main(args:Array[String]):Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
val value: RDD[(String, Int, Int)] = sc.makeRDD(List(("zhangsan", 12, 176), ("lisi", 24, 180), ("wangwu", 43, 165)))
val frame: DataFrame = value.map(t => {
Person(t._1, t._2, t._3)
}).toDF()
frame.show()
frame.createOrReplaceTempView("person")
// 注册UDF函数
spark.udf.register("prefixName",(name:String)=>{
"A_"+name
})
spark.sql("select prefixName(name),age from person").show()
spark.close()
}
case class Person(val name:String,val age:Int,val high:Int)
}

5.7.3.2 UDAF函数-弱类型函数实现
说明:需要继承UserDefinedAggregateFunciont(比较老的版本了)来实现用户自定义弱类型聚合函数。
package sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object LocalSql {
def main(args:Array[String]):Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
val value: RDD[(String, Int, Int)] = sc.makeRDD(List(("zhangsan", 12, 176), ("lisi", 24, 180), ("wangwu", 43, 165)))
val frame: DataFrame = value.map(t => {
Person(t._1, t._2, t._3)
}).toDF()
frame.createOrReplaceTempView("person")
spark.udf.register("ageAvg",new MyAvgUDAF()) // 注册函数
spark.sql("select ageAvg(age) from person").show()
spark.close()
}
case class Person(val name:String,val age:Int,val high:Int)
/** 弱类型函数实现
* 目的:自定义聚合函数类:计算年龄的平均值
*/
class MyAvgUDAF extends UserDefinedAggregateFunction{
/** 输入数据的结构:In
*
* StructType为样例类,他的伴生对象让我们可以直接创建对象,其参数为序列[StructField]
* StructField样例类有两个参数:
* args(0)为name,表示要输入的值的名称,这里为 "age"
* args(1)为DataType,表示要输入的类型,DataType为抽象类,Ctrl+H后可以找到对应的实现子类,这里为 LongType
*
*/
override def inputSchema: StructType = {
StructType(Array(
StructField("age",LongType)
))
}
/** 缓冲区数据的结构
*
* Buffer
*/
override def bufferSchema: StructType = {
StructType(Array(
StructField("total",LongType),
StructField("count",LongType)
))
}
/** 函数计算结果的数据类型:Out
*
*/
override def dataType: DataType = LongType
/** 函数的稳定性:
* 当数据为随机数时,确定数据的输出和输入是否一致
*/
override def deterministic: Boolean = true
/** 缓冲区初始化
*
*/
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// scala中语法的功能,当对象中有update方法时,可以简化写法
// buffer(0) = 0L
// buffer(1) = 1L
buffer.update(0,0L)
buffer.update(1,0L)
}
/** 根据输入的值更新缓冲区数据
*
*/
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getLong(0)+input.getLong(0))
buffer.update(1,buffer.getLong(1)+1)
}
/** 缓冲区数据合并
* x + y => x , 不断的更新后,最终的结果都是更新为 x
*/
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getLong(0)+buffer2.getLong(0))
buffer1.update(1,buffer1.getLong(1)+buffer2.getLong(1))
}
/** 计算平均值
*
*/
override def evaluate(buffer: Row): Any = {
buffer.getLong(0) / buffer.getLong(1)
}
}
}
5.7.3.3 UDAF函数-强类型函数实现
说明:需要继承Aggregator类来实现用户自定义强类型聚合函数。
package sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, functions}
object LocalSql {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
val value: RDD[(String, Int, Int)] = sc.makeRDD(List(("zhangsan", 12, 176), ("lisi", 24, 180), ("wangwu", 43, 165)))
val frame: DataFrame = value.map(t => {
Person(t._1, t._2, t._3)
}).toDF()
frame.createOrReplaceTempView("person")
// DataFrame里面只有数据,我们无法将一个强类型的函数,应用在弱类型的数据上
// 若要使用强类型函数上,需要使用转换函数
spark.udf.register("ageAvg", functions.udaf(new MyAvgUDAF()))
spark.sql("select ageAvg(age) from person").show()
spark.close()
}
case class Person(val name: String, val age: Int, val high: Int)
/** 强类型函数实现
* 目的:自定义聚合函数类:计算年龄的平均值
*
* 继承 org.apache.spark.sql.expressions.Aggregator 类后需要给定泛型:
* IN:输入的数据类型 Long
* BUF:缓冲区的数据类型 Buff
* OUT:输出的数据类型 Long
*/
case class Buff(var total: Long, var count: Long)
class MyAvgUDAF extends Aggregator[Long, Buff, Long] {
/** z & zero:初始化或零值
* 缓冲区的初始化
*/
override def zero: Buff = {
Buff(0L, 0L)
}
/** 根据输入的数据更新缓冲区的数据
*
* @param buff
* @param in
* @return
*/
override def reduce(buff: Buff, in: Long): Buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
/** 合并缓冲区
*
* @param b1
* @param b2
* @return
*/
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total = b1.total + b2.total
b1.count = b1.count + b2.count
b1
}
/** 计算结果
*
*/
override def finish(reduction: Buff): Long = {
reduction.total / reduction.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
5.7.3.4 早期强类型函数实现
package sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, TypedColumn, functions}
object LocalSql {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
val value: RDD[(String, Int, Int)] = sc.makeRDD(List(("zhangsan", 12, 176), ("lisi", 24, 180), ("wangwu", 43, 165)))
val frame: DataFrame = value.map(t => {
Person(t._1, t._2, t._3)
}).toDF()
/**
* 在早期的版本中,Spark不能在sql中使用强类型UDAF操作
* 但是我们除了 SQL语法 外,还有 DSL语法
*
* 早期的UDAF强类型聚合函数使用的是DSL语法操作:
* 需要将自定义函数的输入类型该为 自定义样例类, 这里是 Person
* 需要通过 x[Person].age 的方式 去访问属性,进行操作
*/
// 将DataFrame转换为DataSet
val dataSet: Dataset[Person] = frame.as[Person]
// 将UDAF函数转换为查询的列对象
val column: TypedColumn[Person, Long] = new MyAvgUDAF().toColumn
// 将聚合函数,当成一个查询的列,比较特殊
dataSet.select(column).show()
spark.close()
}
case class Person(val name: String, val age: Int, val high: Int)
/** 强类型函数实现
* 目的:自定义聚合函数类:计算年龄的平均值
*
* 继承 org.apache.spark.sql.expressions.Aggregator 类后需要给定泛型:
* IN:输入的数据类型 Person
* BUF:缓冲区的数据类型 Buff
* OUT:输出的数据类型 Long
*/
case class Buff(var total: Long, var count: Long)
class MyAvgUDAF extends Aggregator[Person, Buff, Long] {
/** z & zero:初始化或零值
* 缓冲区的初始化
*/
override def zero: Buff = {
Buff(0L, 0L)
}
/** 根据输入的数据更新缓冲区的数据
*
* @param buff
* @param in
* @return
*/
override def reduce(buff: Buff, in: Person): Buff = {
buff.total = buff.total + in.age
buff.count = buff.count + 1
buff
}
/** 合并缓冲区
*
* @param b1
* @param b2
* @return
*/
override def merge(b1: Buff, b2: Buff): Buff = {
b1.total = b1.total + b2.total
b1.count = b1.count + b2.count
b1
}
/** 计算结果
*
*/
override def finish(reduction: Buff): Long = {
reduction.total / reduction.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
5.7.4 数据的加载和保存
5.7.4.1 通用的加载和保存方式
说明:
- 通用指使用相同的API,根据不同的参数读取和保存不同格式的数据。
- SparkSQL默认读取和保存的文件格式为parquet
5.7.4.1.1 加载数据
-
读取不同格式的数据,可以对不同的数据格式进行设定
scala> spark.read.format("...").[.option("...")].load("...")-
format("..."):指定加载的数据类型,包括:
csv jdbc json orc parquet text textFile -
load("..."):在
csv jdbc json orc parquet text textFile格式下需要传入加载数据的路径 -
option("..."):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
-
-
简写
如:spark.read.json("...path...") -
可以直接在文件上进行查询:文件格式.`文件路径`
spark.sql("select * from json.`...path...`").show
5.7.4.1.2 保存数据
-
保存不同格式的数据,可以对不同的数据格式进行设定
datafrmae.write.format("...").[.option("...")].save("...")- format("..."):指定保存的数据类型,包括:
csv jdbc json orc parquet text textFile - save("..."):在
csv jdbc json orc parquet text textFile格式下需要传入保存数据的路径 - option("..."):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
- format("..."):指定保存的数据类型,包括:
-
保存操作可以使用SaveMode,用来指明如何处理数据,使用mode()方法来设置
dataframe.write.mode("append").json("...path...")说明:这些SaveMode都是没有加锁的,也不是原子操作
Scala/Java Any Language Meaning SaveMode.ErrorIfExists(default) "error"(default) 如果文件已经存在则抛出异常 SaveMode.Append "append" 如果文件已经存在则追加 SaveMode.Overwrite "overwrite" 如果文件已经存在则覆盖 SaveMode.Ignore "ignore" 如果文件已经存在则忽略
5.7.4.2 Parquet文件
说明:
- SparkSQL的默认数据源为Parquet格式
- Parquet是一种能够有效存储嵌套数据的列式存储格式
- 数据源为Parquet文件时,SparkSQL可以方便的执行所有的操作,不需要使用format
- 修改配置项spark.sql.sources.default,可修改默认数据源格式
5.7.4.3 JSON
说明:
-
SparkSQL能够自动推测JSON数据集的结构,并将它加载为一个Dataset[Row]
-
可以通过SparkSession.read.json()去加载json文件
-
Spark读取的JSON文件不是传统的JSON文件,每一行都应该是一个JSON串,如
{"username":"zhangshan","age":20} {"username":"wangwu","age":10} [{"username":"lisi","age":30},{"username":"zhaoliu","age":30}]
5.7.4.4 CSV
说明:
- SparkSQL可以配置CSV文件的列表信息,读取CSV文件
spark.read.format("csv").option("sep",";").option("inferSchema","ture").option("header","true").load("...path...")
5.7.4.5 MySQL
说明:
- SparkSQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中
- 如果使用spark-shell操作,可在启动shell时指定相关的数据库驱动路径或将相关的数据库驱动放到spark的类路径下
IDEA中导入依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
IDEA读取数据:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SparkSession}
import java.util.Properties
object LocalSql {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val sc: SparkContext = new SparkContext(sparkConf)
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
// 方式一:通用的load方法读取
println("方式一:通用的load方法读取")
spark.read.format("jdbc")
.option("url","jdbc:mysql://pc001:3306/test")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("user","root")
.option("password","root")
.option("dbtable","goods")
.load().show()
// 方式二:通用的load方法读取,参数另一种形式
println("方式二:通用的load方法读取,参数另一一种形式")
spark.read.format("jdbc")
.options(Map("url" -> "jdbc:mysql://pc001:3306/test?user=root&password=root",
"dbtable"->"goods",
"driver"->"com.mysql.cj.jdbc.Driver")).load().show()
// 方式三:使用jdbc方法获取
println("方式三:使用jdbc方法获取")
val props = new Properties()
props.setProperty("user","root")
props.setProperty("password","root")
spark.read.jdbc(url="jdbc:mysql://pc001:3306/test","goods",props).show()
spark.close()
}
}
IDEA写出数据:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf}
import org.apache.spark.sql.{Dataset, SaveMode, SparkSession}
import java.util.Properties
object LocalSql {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("LocalSql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 引入隐式转换规则,否则无法转换
import spark.implicits._
// 准备数据
val value: RDD[goods] = spark.sparkContext.makeRDD(List(goods(7, "X7", 70), goods(8, "X8", 80)))
val value_ds: Dataset[goods] = value.toDS()
// 方式一:通用的sava方法写出
println("方式一:通用的sava方法写出")
value_ds.write.format("jdbc")
.option("url","jdbc:mysql://pc001:3306/test")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("user","root")
.option("password","root")
.option("dbtable","test1")
.mode(SaveMode.ErrorIfExists)
.save()
// 方式二:使用jdbc方法write
println("方式二:使用jdbc方法write")
val props = new Properties()
props.setProperty("user","root")
props.setProperty("password","root")
value_ds.write.mode(SaveMode.ErrorIfExists).jdbc(url="jdbc:mysql://pc001:3306/test","test2",props)
spark.close()
}
case class goods(val id:Int,val name:String,val weight:Int)
}
5.7.4.6 Hive
-
内嵌的HIVE(基本不使用)
说明:
- 使用Spark内嵌的Hive,直接使用即可。
- SparkSQL会在当前的工作目录中创建出自己的Hive元数据仓库,即metastore_db。
- 如果使用HiveQL中的create table(并非create external table)语句来创建表,这些表会被放在默认的文件系统中的/user/hive/warehouse目录中
- Hive的元数据存储再derby中,默认仓库地址:$SPARK_HOME/spark-warehouse
-
外部的HIVE(主要使用)
如果想连接外部已经部署好的Hive,需要:
- Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下
- 把Mysql的驱动拷贝到jars/目录下
- 如果不访问本地文件系统,而是访问HDFS,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下
- 重启spark-shell
运行sparkSQL CLI:
SparkSQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。
在Spark目录下执行:
./bin/spark-sql即可启动SparkSQL CLI后,直接执行SQL语句运行Spark beeline:
-
启动Thrift Server
./sbin/start-thriftserver.sh -
使用beeline连接Thrift Server
./bin/beeline -u jdbc:hive2://pc001:10000 -n root
代码操作Hive:
-
导入依赖
<dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.25</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>3.1.2</version> </dependency> </dependencies> -
将hive-site.xml文件拷贝到项目的resources中
-
代码实现
//创建 SparkSession val spark: SparkSession = SparkSession .builder() .enableHiveSupport() .master("local[*]") .appName("sql") .getOrCreate()-
在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址
config("spark.sql.warehouse.dir", "hdfs://pc001:8082/user/hive/warehouse") -
如果出现用户权限错误,需要将用户改为HDFS的用户
System.setProperty("HADOOP_USER_NAME", "nuochengze")
5.8 案例
SparkSQL+自定义UDAF
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object Test {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "nuochengze")
val spark: SparkSession = SparkSession.builder()
.appName("Test")
.master("local[*]")
.config("hadoop.home.dir", "hdfs://pc001:8082/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
spark.sql("use test")
spark.sql("drop table if exists user_visit_action;")
spark.sql("drop table if exists product_info;")
spark.sql("drop table if exists city_info;")
spark.sql(
"""
|CREATE TABLE `user_visit_action`(
| `date` string,
| `user_id` bigint,
| `session_id` string,
| `page_id` bigint,
| `action_time` string,
| `search_keyword` string,
| `click_category_id` bigint,
| `click_product_id` bigint,
| `order_category_ids` string,
| `order_product_ids` string,
| `pay_category_ids` string,
| `pay_product_ids` string,
| `city_id` bigint)
|row format delimited fields terminated by '\t';
|""".stripMargin)
spark.sql("load data local inpath 'data/user_visit_action.txt' into table user_visit_action;")
spark.sql(
"""
|CREATE TABLE `product_info`(
| `product_id` bigint,
| `product_name` string,
| `extend_info` string)
|row format delimited fields terminated by '\t';
|""".stripMargin)
spark.sql("load data local inpath 'data/product_info.txt' into table product_info;")
spark.sql(
"""
|CREATE TABLE `city_info`(
| `city_id` bigint,
| `city_name` string,
| `area` string)
|row format delimited fields terminated by '\t';
|""".stripMargin)
spark.sql("load data local inpath 'data/city_info.txt' into table city_info;")
// spark.sql("select * from user_visit_action limit 10").show()
// spark.sql("select * from product_info limit 10").show()
// spark.sql("select * from city_info limit 10").show()
spark.sql(
"""
|select a.*,b.product_name,c.area,c.city_name
|from user_visit_action a
|inner join product_info b
|on b.product_id = a.click_product_id
|inner join city_info c
|on c.city_id = a.city_id
|where a.click_product_id > -1
|""".stripMargin).createOrReplaceTempView("t1")
// 根据区域,商品进行数据聚合
spark.udf.register("cityRemark", functions.udaf(new CityRemarkUDAF()))
spark.sql(
"""
|select t1.area,
| t1.product_name,
| count(*) as clickCnt,
| cityRemark(city_name) as city_remark
|from t1
|group by t1.area,t1.product_name
|""".stripMargin).createOrReplaceTempView("t2")
spark.sql(
"""
|select t2.area,
| t2.product_name,
| t2.clickCnt,
| t2.city_remark,
| row_number() over(partition by t2.area order by t2.clickCnt desc) as rank
|from t2
|""".stripMargin).createOrReplaceTempView("t3")
spark.sql(
"""
|select t3.area,
| t3.product_name,
| t3.clickCnt,
| t3.city_remark
|from t3
|where t3.rank <= 3
|""".stripMargin).show(false)
spark.close()
}
case class Buffer(var total: Long, var cityMap: mutable.Map[String, Long])
/**
* IN:城市名称
* BUF:Buffer => [总点击量,Map[城市名称,这个产品在这个城市的点击量]]
*/
class CityRemarkUDAF extends Aggregator[String, Buffer, String] {
// 缓冲区初始化
override def zero: Buffer = {
Buffer(0, mutable.Map[String, Long]())
}
// 更新缓冲区数据
override def reduce(buffer: Buffer, city: String): Buffer = {
buffer.total += 1
val newCount: Long = buffer.cityMap.getOrElse(city, 0L) + 1
buffer.cityMap.update(city, newCount)
buffer
}
//
override def merge(buffer1: Buffer, buffer2: Buffer): Buffer = {
buffer1.total += buffer2.total
// 合并两个map
val map1: mutable.Map[String, Long] = buffer1.cityMap
val map2: mutable.Map[String, Long] = buffer2.cityMap
map2.foreach {
case (c, cnt) => {
val newCount: Long = map1.getOrElse(c, 0L) + cnt
map1.update(c, newCount)
}
}
buffer1.cityMap = map1
buffer1
}
// 将统计的结果生成字符串信息
override def finish(buffer: Buffer): String = {
val remarkList: ListBuffer[String] = ListBuffer[String]()
val total: Long = buffer.total
val cityMap: mutable.Map[String, Long] = buffer.cityMap
// 降序排列
val cityTuples: List[(String, Long)] = cityMap.toList.sortWith(
(left: (String, Long), right: (String, Long)) => {
left._2 > right._2
}
).take(2)
// 判断有多少个城市
val hasMoreCityThan2: Boolean = cityMap.size > 2
var rSum: Long = 0L
cityTuples.foreach{
case (city ,cnt) => {
val l: Long = cnt * 100 / total
remarkList.append(s"${city} ${l}%")
rSum += l
}
}
if(hasMoreCityThan2){
remarkList.append(s"其他 ${100-rSum}%")
}
remarkList.mkString(", ")
}
override def bufferEncoder: Encoder[Buffer] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
}
6、SparkStreaming
6.1 SparkStreaming定义
Spark Streaming用于流式数据的处理,将收到的每个时间区间的数据作为RDD,组成一个序列,具有离散化的特点,叫做DStream。
Spark接收到数据输入后,利用 Spark的高度抽象原语(和算子类似,如map、reduce、join、window等)进行运算后,输出到存储路径。

Spark属于准实时(范围在秒,分钟),微批次(时间)的数据处理框架。
6.2 SparkStreaming架构
-
整体的架构图
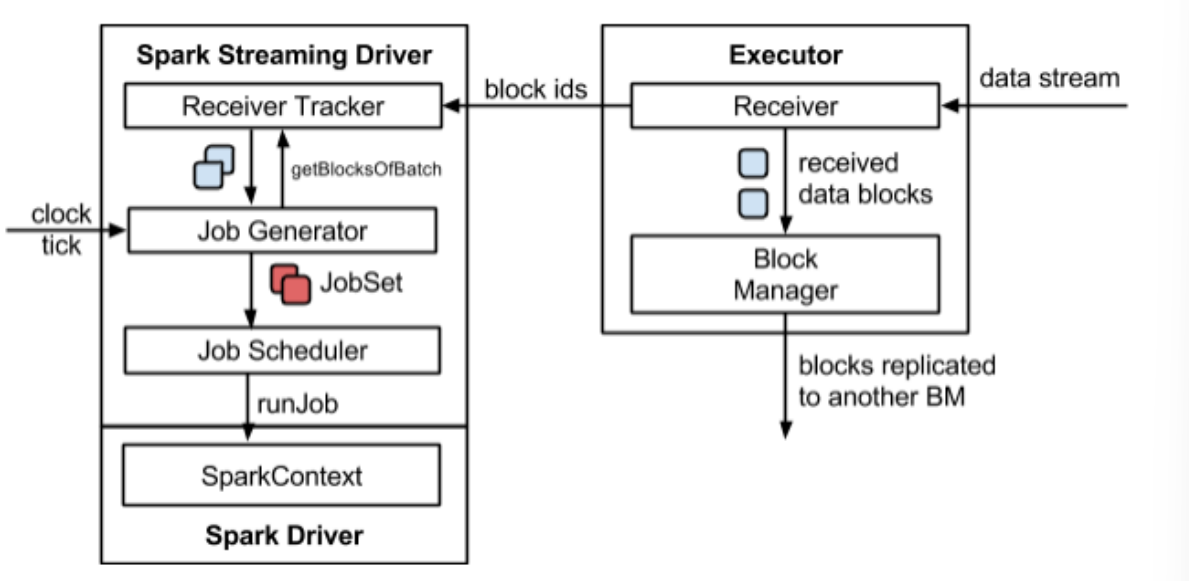
-
Spark Streaming 架构图
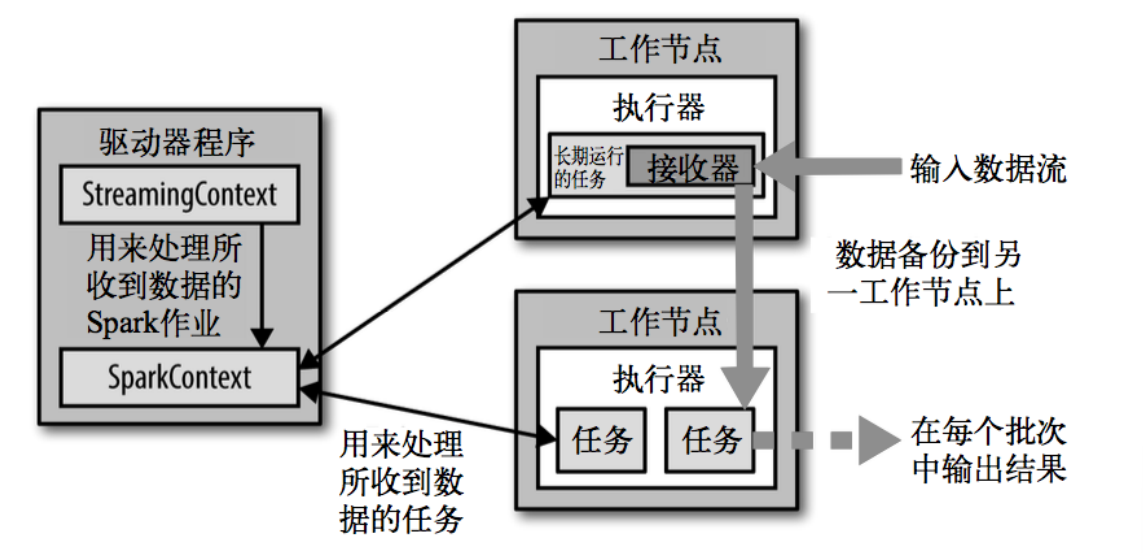
6.3 背压机制
说明:数据在处理实时流时,需要协调数据接受速率与资源处理能力,于是产生了背压机制。
-
在Spark1.5版本之前
在Spark1.5版本之前,用户如果要限制Receiver的数据接收速率,可以通过设置静态配置参数"spark.streaming.receiver.maxRate"的值来实现。
缺陷:虽然能够限制接收速率,来适配当前的处理能力,防止内存溢出,但是当producer数据生成高于maxRate,当前集群处理能力也高于maxRate时,会造成资源利用率下降等问题。
-
在Spark1.5版本之后
在Spark1.5版本之后,SparkStreaming可以动态控制数据接收速率来适配集群数据处理能力,即背压机制(Spark Streaming Backpressure):根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
通过属性"spark.streaming.backpressure.enabled"来控制是否启用backpressure机制,默认为false,不启用。
6.4 Dstream入门
6.4.1 WordCount案例
说明:
- 使用netcat工具向9999端口发送布局,通过SparkStreaming读取端口数据并统计不同单词出现的次数
步骤:
-
导入maven依赖
<dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.25</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>3.1.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.1.2</version> </dependency> </dependencies> -
编写代码
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args:Array[String]):Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(conf,Seconds(3)) val lines: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999) val words: DStream[String] = lines.flatMap(_.split(" ")) val word: DStream[(String, Int)] = words.map((_, 1)) val word_Count: DStream[(String, Int)] = word.reduceByKey(_ + _) word_Count.print() // 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭 // 如果main方法执行完毕,应用程序也会自动结束,所以不能让main执行完毕,需要启动采集器和等待采集器关闭 // ssc.stop() // 1.启动采集器 ssc.start() // 2.等待采集器的关闭 ssc.awaitTermination() } } -
端口发送数据
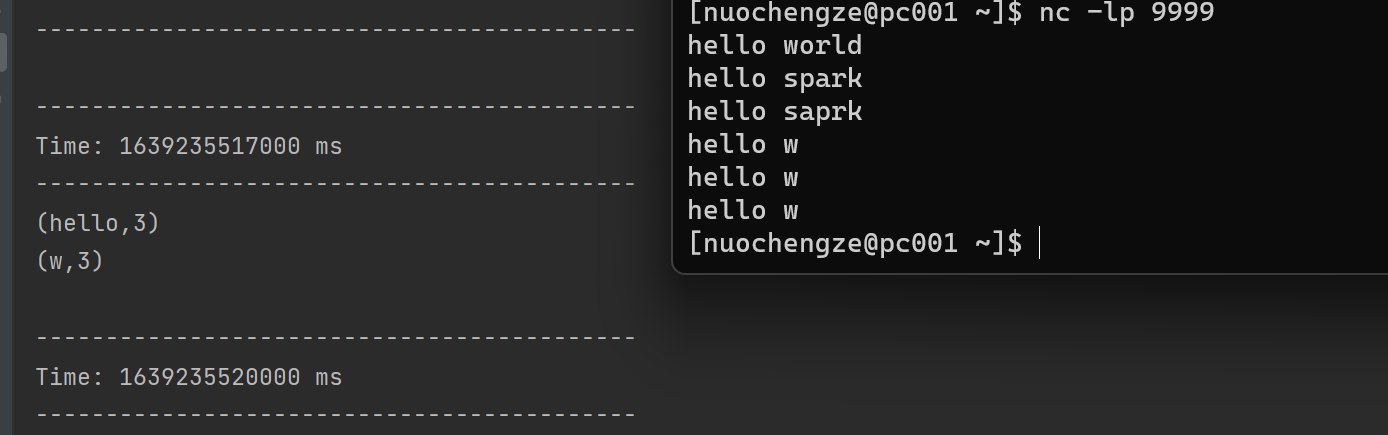
6.5 DStream创建
6.5.1 RDD队列
说明:
- 通过ssc.queueStream(mutable.Queue[RDD[T]])来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream来处理。
示例代码:
-
说明
循环创建RDD,将RDD放入队列,通过SparkStream创建DStream,计算WordCount
-
代码
import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable object WordCount { def main(args:Array[String]):Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(conf,Seconds(3)) // 1.创建RDD队列 val rddQueue: mutable.Queue[RDD[Int]] = new mutable.Queue[RDD[Int]]() // 2.创建QueueInputDStream val inputStream: InputDStream[Int] = ssc.queueStream(rddQueue, false) // 3.处理队列中的RDD数据 val mappedStream: DStream[(Int, Int)] = inputStream.map((_, 1)) val reducedStream: DStream[(Int, Int)] = mappedStream.reduceByKey(_ + _) // 4.打印结果 reducedStream.print() // 5.启动任务 ssc.start() // 6.循环创建并向RDD队列中放入RDD for( i <- 1 to 5){ rddQueue += ssc.sparkContext.makeRDD(1 to 300,10) Thread.sleep(2000) } // 7.等待采集器的关闭 ssc.awaitTermination() } }
6.5.2 自定义数据源
说明:
自定义数据源,需要继承Receiver,并重写onStart、onStop方法
示例代码:
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.Random
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
val strDStream: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())
strDStream.print()
// 启动任务
ssc.start()
// 等待采集器的关闭
ssc.awaitTermination()
}
/**
* 自定义数据采集器:
* 1、继承Receiver方法,需要定义泛型,传递参数
* 2、重写方法onStart()、onStop()
*/
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var flag = true
override def onStart(): Unit = {
// 生成一个新线程运行任务
new Thread(new Runnable {
override def run(): Unit = {
while (flag) {
val str: String = "采集的随机数为:" + new Random().nextInt(10).toString
// 将数据进行存储,由底层自动封装
store(str)
Thread.sleep(500)
}
}
}).start()
}
override def onStop(): Unit = {
flag = false
}
}
}
6.5.3 连接Kafka
说明:
通过连接kafka后,进行wordcount的操作
步骤:
-
代码
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord} import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(conf, Seconds(3)) val kafkaParams: Map[String, Object] = Map[String, Object]( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "pc001:9092,pc002:9092,pc003:9092", ConsumerConfig.GROUP_ID_CONFIG -> "test", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer" ) val value: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Set("test"), kafkaParams) ) val value1: DStream[String] = value.map(_.value()) val value2: DStream[String] = value1.flatMap(_.split(" ")) val value3: DStream[(String, Int)] = value2.map((_, 1)).reduceByKey(_ + _) value3.print() // 启动任务 ssc.start() // 等待采集器的关闭 ssc.awaitTermination() } } -
启动kafka集群
-
开启kafka的生产端
kafka-console-producer.sh --topic test --broker-list pc001:9092 -
验证
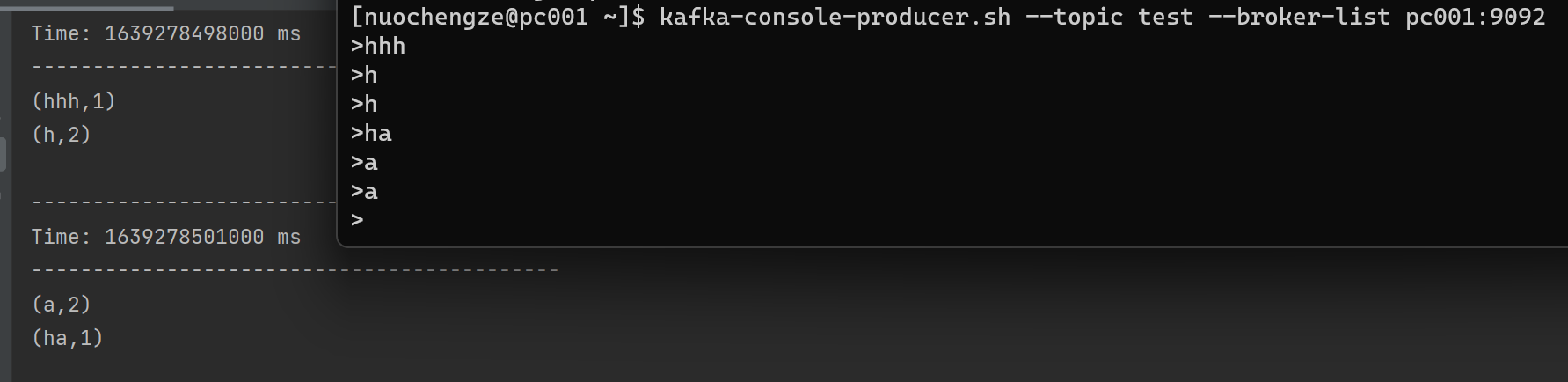
6.6 DStream转换和输出
说明:
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种。
6.6.1 DStream转换
6.6.1.1 无状态转化操作
说明:无状态转化操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。
注意:针对键值对的DStream转化操作(比如reduceByKey())要添加import StreamingContext._才能在Scala中使用。
6.6.1.1.1 Transform
说明:
Transform允许DStream上执行任意的RDD-to-RDD函数。即使这些函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API。该函数每一批次调度一次。
示例代码:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
val value: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999)
// code Driver端,main线程启动执行一次
val value1: DStream[String] = value.transform(
rdd => {
// code Driver端,按RDD流,周期性执行
rdd.map(
str => {
// code :Executor端
str
}
)
}
)
// 和简单的map对比
// code Driver端
val value2: DStream[String] = value.map(
rdd => {
// code Executor端
rdd
}
)
/**
* 说明:
* 虽然 value1和value2获取到的对象都是DStream,但是value1通过transform获取的过程中,其能code的地方明显比value1的简单map多
*
* transform使用的地方:
* 1、DStream功能不完善时
* 2、需要代码周期性执行的时候
*/
// 启动任务
ssc.start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}
6.6.1.1.2 join
说明:两个流之间的join需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的RDD进行join,与两个RDD的join效果相同。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999)
val value2: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 8888)
val value9999: DStream[(String, String)] = value1.flatMap(_.split(" ")).map((_, "9999"))
val value8888: DStream[(String, String)] = value2.flatMap(_.split(" ")).map((_, "8888"))
// 查看底层的原码,可以发现本质上还是RDD.join
val value: DStream[(String, (String, String))] = value9999.join(value8888)
value.print()
// 启动任务
ssc.start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}
6.6.1.2 有状态转换操作
6.6.1.2.1 UpdateStateByKey
说明:
- UpdateStateByKey原语用于记录历史记录,当我们在流计算中累加wordCount时,需要在DStream中跨批次维护状态。针对这种情况,updateStateByKey()提供了对一个状态变量的访问,即键值对形式的DStream:给定一个由(键,事件)对构成的DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的DStream,其内部数据为(键,状态)对。
- updateStateByKey()的结果会是一个新的DStream,其内部的RDD序列是由每个时间区间对应的(键,状态)对组成的。
- updateStateByKey()操作使我们可以在用新信息进行更新时保持任意的状态,使用这个功能,需要完成3步:
- 定义状态,状态可以是一个任意的数据类型
- 定义状态更新函数,用词函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新
- 使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
使用示例:
-
示例代码
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(conf, Seconds(3)) // 设置检查点 ssc.checkpoint("data/checkpoint") val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999) val value2: DStream[(String, Int)] = value1.flatMap(_.split(" ")).map((_, 1)) /** * updateStateByKey,根据key对数据的状态进行更新 * 传递的参数中含有两个值: * 1、第一个值表示相同的key的value数据,如(1,1,1,1,...) * 2、第二个值表示缓存区相同的key的value数据 */ // 使用updateStateByKey来更新状态,统计从运行开始依赖单词总的次数 val value: DStream[(String, Int)] = value2.updateStateByKey( (seq: Seq[Int], buffer: Option[Int]) => { val newCount: Int = buffer.getOrElse(0) + seq.sum Option(newCount) } ) value.print() // 启动任务 ssc.start() // 等待采集器的关闭 ssc.awaitTermination() } } -
netcat发送数据
nc -lp 9999 -
结果
6.6.1.2.2 WindowOperations
说明:
WindowOperations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态,所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
- 窗口时长:计算内容的时间范围
- 滑动步长:隔多久触发一次计算
注意:窗口时长和滑动步长,都必须为采集周期大小的整数倍。
使用示例:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
// 设置检查点
ssc.checkpoint("data/checkpoint")
val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999)
val value2: DStream[(String, Int)] = value1.flatMap(_.split(" ")).map((_, 1))
/**
* 窗口的范围应该是采集周期的整数倍
* 窗口滑动的范围,默认为一个采集周期
* 为了避免重复数据的计算,可以改变滑动的步长
*/
val value3: DStream[(String, Int)] = value2.window(Seconds(6), Seconds(6))
val value: DStream[(String, Int)] = value3.reduceByKey(_ + _)
value.print()
// 启动任务
ssc.start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}
其他Window的操作:
- window(windowLength,slideInterval):基于对源DStream窗化的批次进行计算返回一个新的DStream
- countByWindow(windowLength,slideInterval):返回一个滑动窗口计数流中的元素个数
- reduceByWindow(func,windowLength,slideInterval):通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流
- reduceByKeyAndWindow(func,windowLength,slideInterval,[numTasks]):当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值
- reduceByKeyAndWIndow(func,invFunc,windowLength,slideInterval,[numTasks]):这个函数是reduceByKeyAndWindow的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并“反向reduce"离开窗口的旧数据来实现这个操作。
6.6.2 DStream输出
说明:
输出操作指定了对流数据经转化操作得到的数据所要执行的操作。与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
输出操作:
-
print()
在运行流程序的驱动节点上打印DStream中每一批次数据的最开始10个元素,一般用于开发和调试。
-
saveAsTextFile(prefix,[suffix])
以text文件形式存储这个DStream的内容,每一批次的存储文件名基于参数中的prefix和suffix:
prefix-Time-IN_MS[.suffix] -
saveAsObjectFiles(prefix,[suffix])
以Java对象序列化的方式将Stream中的数据保存为SequenceFiles,每一批次的存储文件名基于参数中的prefix和suffix:
prefix-Time-IN_MS[.suffix] -
saveAsHadoopFiles(prefix,[suffix])
将Stream中的数据保存为Hadoop files,每一批次的存储文件名基于参数中的prefix和suffix:
prefix-Time-IN_MS[.suffix] -
foreachRDD(func)
将函数func用于产生于DStream的每一个RDD,其中参数传入的函数func应该实现将每一个RDD中数据 推送到外部系统:如将RDD存入文件或者通过网络将其写入数据库。
在foreachRDD()中,可以重用我们在Spark中实现的所有行动操作。
注意:
- 连接不能写在Driver层面(序列化)
- 如果写在foreach,则每个RDD中的每一条数据都创建,浪费资源
- 增加foreachPartition,在分区创建(获取)
伪代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
// 设置检查点
ssc.checkpoint("data/checkpoint")
val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999)
val value2: DStream[(String, Int)] = value1.flatMap(_.split(" ")).map((_, 1))
val value: DStream[(String, Int)] = value2.reduceByKey(_ + _)
value.print()
// 启动任务
ssc.start()
// 优雅的关闭
/**
* 如果想要关闭采集器,那么需要创建新的线程
* 而且需要在第三方程序中增加关闭状态
*/
new Thread(
new Runnable{
override def run(): Unit = {
/**
* 优雅的关闭,表示当计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭
* 比如: mysql 写入一行数据后判断的方式
*/
while(true){
if(true){
// 获取SparkStreaming状态
val state: StreamingContextState = ssc.getState()
if(state == StreamingContextState.ACTIVE){
ssc.stop(true,true)
}
}
Thread.sleep(5000)
System.exit(0)
}
}
}
).start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}
使用示例:
-
MonitorStop模块
import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.{FileSystem, Path} import org.apache.spark.streaming.{StreamingContext, StreamingContextState} import java.net.URI class MonitorStop(ssc:StreamingContext) extends Runnable { override def run(): Unit = { val fs: FileSystem = FileSystem.get(new URI("hdfs://pc001:8082"), new Configuration(), "nuochengze") while(true){ try{ Thread.sleep(5000) }catch { case e:InterruptedException => e.printStackTrace() } val state: StreamingContextState = ssc.getState() val bool: Boolean = fs.exists(new Path("hdfs://pc001:8082/stopSpark")) if(bool){ if(state==StreamingContextState.ACTIVE){ ssc.stop(true,true) System.exit(0) } } } } } -
wordcount模块
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState} object WordCount { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming") val ssc = new StreamingContext(conf, Seconds(3)) // 设置检查点 ssc.checkpoint("data/checkpoint") val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999) val value2: DStream[(String, Int)] = value1.flatMap(_.split(" ")).map((_, 1)) val value: DStream[(String, Int)] = value2.reduceByKey(_ + _) value.print() // 启动任务 ssc.start() // 启动优雅的关闭 new Thread(new MonitorStop(ssc)).start() // 等待采集器的关闭 ssc.awaitTermination() } }
优雅的关闭-数据恢复:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object WordCount {
def main(args: Array[String]): Unit = {
/**
* 通过StreamingContext.getActiveOrCreate,结合检查点,可以恢复数据
*/
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("data/checkpoint", () => {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(conf, Seconds(3))
val value1: ReceiverInputDStream[String] = ssc.socketTextStream("pc001", 9999)
val value2: DStream[(String, Int)] = value1.flatMap(_.split(" ")).map((_, 1))
val value: DStream[(String, Int)] = value2.reduceByKey(_ + _)
value.print()
ssc
})
// 设置检查点
ssc.checkpoint("data/checkpoint")
// 启动任务
ssc.start()
// 启动优雅的关闭
new Thread(new MonitorStop(ssc)).start()
// 等待采集器的关闭
ssc.awaitTermination()
}
}