1、千千音乐概述
1.1 目的
-
通过在程序入口,输入歌手的名字,便能获取该歌手的所有歌曲的详细信息
-
预览
python run.py
# 数据通过文件返回,文件名字为run.py同级目录下song_list.txt文件中
# 需要说明的是,该链接自带时间戳,隔天会失效{
"song_name": "演员",
"song_id": "242078437",
"song_href": "http://music.taihe.com/song/242078437",
"author_name": "薛之谦",
"author_tinguid": "2517",
"author_url": "http://music.taihe.com/artist/2517",
"song_album": "初学者",
"song_publish_date": "2016-07-18",
"song_publish_company": "海蝶(天津)文化传播有限公司",
"download_url": "http://audio04.dmhmusic.com/71_53_T10040589078_128_4_1_0_sdk-cpm/cn/0206/M00/90/77/ChR47F1_nqiAfD0hAD_MGBybIdk026.mp3?xcode=aefbd591c37efa806a6c2b65cae142a973974a6",
"song_lrc_link": "http://qukufile2.qianqian.com/data2/lrc/bed1fcb36f51259eefab8ba6d95f524f/672457403/672457403.lrc",
"mv_download_url_info": {},
"song_mv_id": null
}
********************
{
"song_name": "你还要我怎样",
"song_id": "100575177",
"song_href": "http://music.taihe.com/song/100575177",
"author_name": "薛之谦",
"author_tinguid": "2517",
"author_url": "http://music.taihe.com/artist/2517",
"song_album": "意外",
"song_publish_date": "2013-11-11",
"song_publish_company": "华宇世博音乐文化(北京)有限公司",
"download_url": "http://audio04.dmhmusic.com/71_53_T10038986648_128_4_1_0_sdk-cpm/cn/0208/M00/E5/61/ChR46119DrGAW4d4AEvErRDwLyg867.mp3?xcode=6b725779223e2de86a6bbb3ac7a1959393d994b",
"song_lrc_link": "http://qukufile2.qianqian.com/data2/lrc/0a6ef3d9a86dd4f1aa782a114d9f288e/672463341/672463341.lrc",
"mv_download_url_info": {},
"song_mv_id": null
}
......
1.2 开发环境
-
抓包分析平台:Window
-
抓包分析软件:Chrome
-
代码开发平台:Linux
-
代码开发软件:pycharm
-
技术栈
-
发送数据请求:requests
-
数据存储:mongodb
-
数据处理:lxml, re, json, pymongo, logging
-
2、项目设计
2.1 流程设计
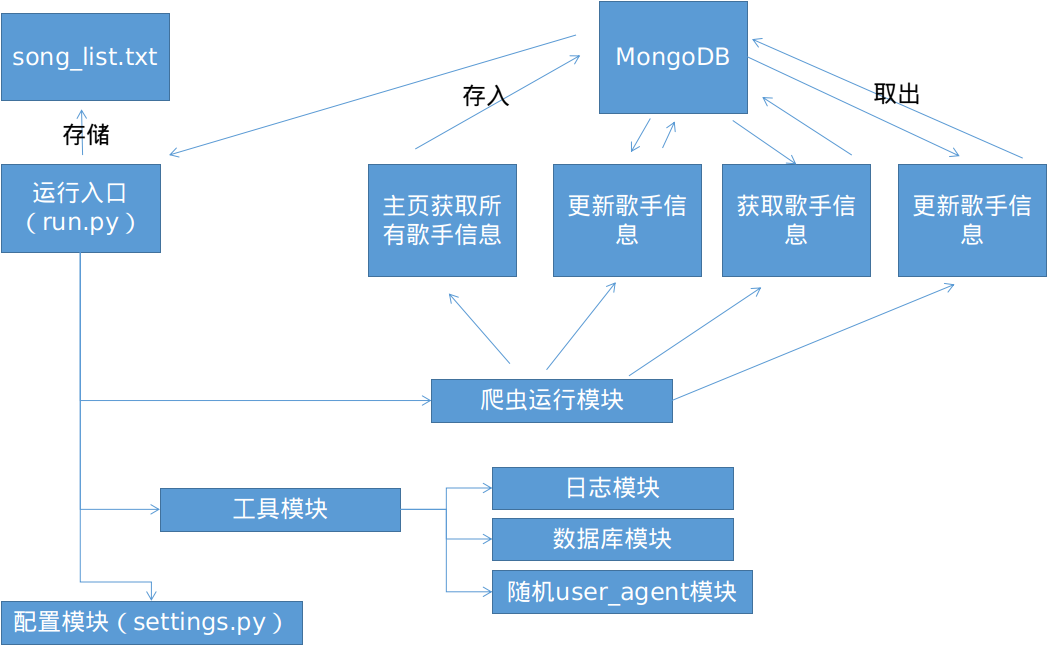
2.2 项目流程概述
-
项目目录

-
项目工作流程概述
-
bin模块-
run.py为程序入口,通过run.py能够调用core.spiders中的各个爬虫模块,实现功能 -
log.log为日志记录 -
song_list.txt为写入的歌手数据,为用户可视化的效果
-
-
core模块-
spiders为爬虫模块-
artist_total.py获取所有的歌手信息,并存入mongodb数据库 -
author_info_update更新歌手的信息,包括生日,简介等 -
song_total.py获取单个歌手的所有歌曲信息 -
song_info_total_update.py更新歌手的歌曲信息,包括下载链接,mv链接(如果有)
-
-
-
utils模块-
log.py提供log的功能 -
mongo_pool.py操作数据库的功能 -
random_useragent.py提供随机的user_agent
-
-
settings.py文件提供配置
-
3、模型设计
3.1 歌手模型
-
效果图

-
字段解释
-
author_name歌手名字 -
author_url歌手主页 -
author_tinguid歌手的id -
author_birthday歌手生日 -
author_constellation歌手星座 -
author_from_area歌手国籍 -
author_gender歌手性别 -
author_hot歌手热度 -
author_image_url歌手图片的url -
author_intro歌手简介 -
author_share_num歌手主页被分享的次数 -
author_songs_total歌手的总歌曲数量 -
author_stature歌手的身高 -
auhtor_weight歌手的体重
-
3.2 歌曲模型
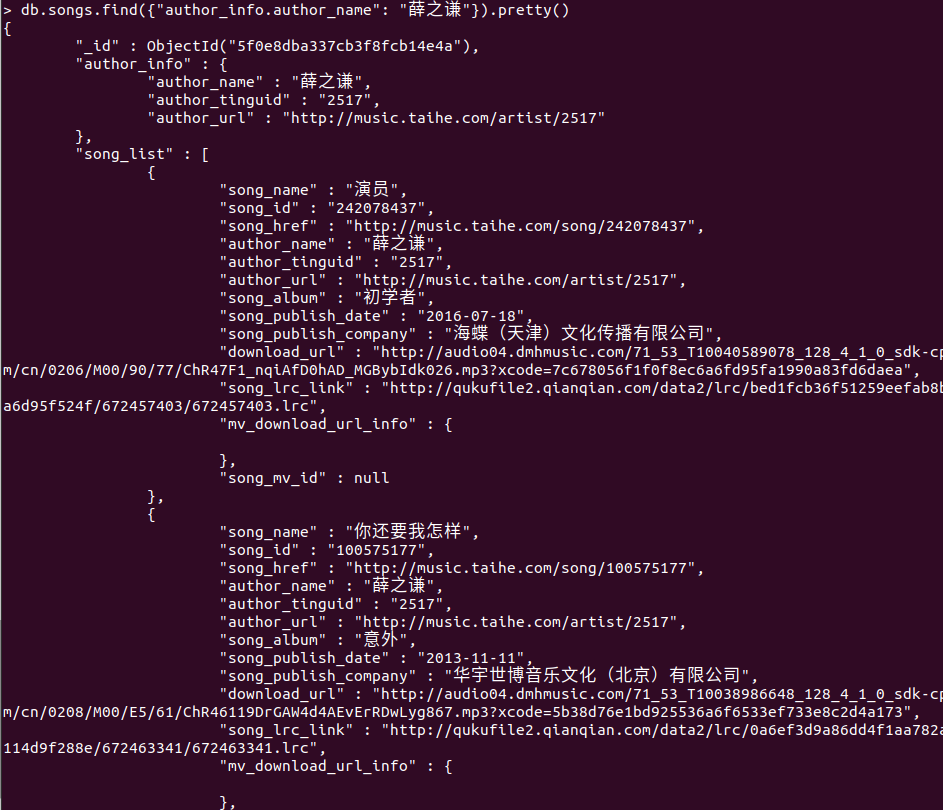
-
效果图
-
字段解释
-
author_info歌手的信息-
author_name歌手名字 -
author_tinguid歌手id -
author_url歌手主页url -
案例

-
-
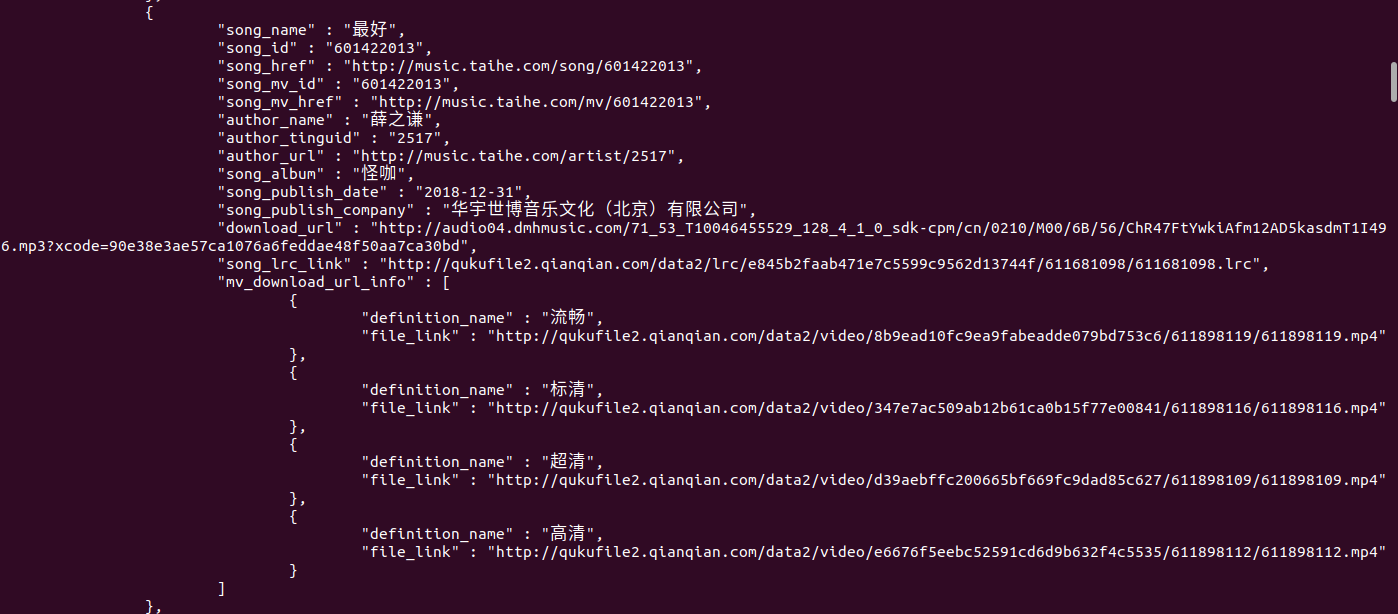
song_list歌手的所有歌曲-
song_name歌曲名字 -
song_id歌曲id -
song_href歌曲主页 -
author_name歌手名字 -
author_tinguid歌手id -
author_url歌手主页 -
song_album歌曲所属专辑 -
song_publish_date歌曲发行时间 -
song_publish_company歌曲发行公司 -
download_url歌曲下载地址 -
song_lrc_link歌曲的歌词链接 -
mv_download_url_info歌曲mv的下载信息 -
song_mv_id歌曲mv的id -
案例
-
-
4、settings.py
-
说明
-
实现全局的配置
-
-
代码
import logging
# 配置MONGO_URL
MONGO_URL = "mongodb://127.0.0.1:27017"
# 配置log
LOG_FMT = "%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s:%(message)s"
LOG_DATE_FMT = "%D-%m-%d %H:%M:%S"
LOG_FILENAME = 'log.log'
LOG_LEVEL = logging.DEBUG
# 配置user_agent
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET4.0C; .NET4.0E; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36"
]
5、utils模块
5.1 random_useragent.py
-
说明
-
实现随机生成一个user_agent的功能
-
通过property装饰方法,使其可以方便调用
-
-
代码
import random
from qianqianyinyue.settings import USER_AGENT_LIST
class RandomUserAgent(object):
def __init__(self):
self.user_agent_list = USER_AGENT_LIST
5.2 log.py
-
说明
-
文件存储
-
方便后续查看日志
-
-
控制台输出
-
方便及时发现数据的变动
-
-
-
代码
import logging
import sys
from qianqianyinyue.settings import LOG_FMT, LOG_LEVEL, LOG_DATE_FMT, LOG_FILENAME
class Logger(object):
def __init__(self):
self._logger = logging.getLogger()
self.formatter = logging.Formatter(fmt=LOG_FMT, datefmt=LOG_DATE_FMT)
self._logger.addHandler(hdlr=self.get_file_handler(filename=LOG_FILENAME))
self._logger.addHandler(hdlr=self.get_console_handler())
self._logger.setLevel(level=LOG_LEVEL)
def get_file_handler(self, filename):
file_handler = logging.FileHandler(filename=filename, encoding='utf8')
file_handler.setFormatter(fmt=self.formatter)
return file_handler
def get_console_handler(self):
console_handler = logging.StreamHandler(stream=sys.stdout)
console_handler.setFormatter(fmt=self.formatter)
return console_handler
5.3 mongo_pool.py
-
说明
-
将集合设置为变量
collection,方便实例化时选择相应的数据 -
实现了
-
插入功能,并记录日志
-
更新功能,并记录日志
-
条件查询更新
-
-
查找单条数据功能
-
通过特定条件,实现查找单条数据
-
-
查找所有数据
-
返回一个生成器
-
-
-
-
代码
from pymongo import MongoClient
from qianqianyinyue.settings import MONGO_URL
from qianqianyinyue.utils.log import logger
class MongoPool(object):
def __init__(self, collection):
self.mongo_client = MongoClient(MONGO_URL)
self.collections = self.mongo_client['qianqianyinyue'][collection]
def __del__(self):
self.mongo_client.close()
def insert_one(self, document):
self.collections.insert_one(document)
logger.info("插入了新的数据:{}".format(document))
def update_one(self, conditions, document):
self.collections.update_one(filter=conditions, update={"$set": document})
logger.info("更新了->{}<-的数据".format(conditions))
def find_one(self, conditions):
collections = self.collections.find(filter=conditions)
for item in collections:
item.pop('_id')
return item
def find_all(self):
collections = self.collections.find()
for item in collections:
item.pop('_id')
yield item
6、core模块
6.0 url分析
-
首页url分析
-
url:
http://music.taihe.com/artist-
返回一个html_str
-
请求体
-
GET请求
-
User-Agent
-
-
目标数据
-
author_name
-
author_url
-
author_tinguid
-
-
-
-
歌手主页url分析
-
url:
http://music.taihe.com/artist/2517-
请求体
-
GET请求
-
Referer:
http://music.taihe.com/aritst
-
-
目标数据
-
song_name
-
song_url
-
song_id
-
song_mv_url
-
song_mv_Id
-
-
-
url:
http://music.taihe.com/data/user/getsongs?start=15&size=15&ting_uid=2517-
说明
-
这是ajax返回的第二页数据,start为当前页数减1后乘15,size固定值,ting_uid为歌手的author_tinguid
-
返回的数据在data字段中,为xml格式字符串,需要re或lxml来提取数据
-
如何获取最大页数?通过歌手主页的首页,拿到页面下标的最大值,然后通过该值构造下一页的请求
-
-
请求体
-
GET请求
-
Referer:
http://music.taihe.com/artist/2517 -
User-Agent
-
-
-
url:
http://music.taihe.com/data/tingapi/v1/restserver/ting?method=baidu.ting.artist.getInfo&from=web&tinguid=2517-
说明
-
每一个歌手的author_tinguid对应一个json数据
-
如果同一时刻,发送的请求过多,会封禁IP
-
设置time.sleep(),能够多拿到一些数据
-
我将时间控制在1到3秒之间,拿到了更多的数据,如果不是为了立刻拿到数据,不妨将时间设置的长一点,即拿到了数据,也降低了被对方服务器发现的可能
time.sleep(random.uniform(1,3))
-
-
-
-
-
歌曲主页url分析
-
url:
http://music.taihe.com/song/242078437-
请求体
-
User-Agent
-
-
目标数据
-
所属的专辑
-
发行时间
-
发行公司
-
-
-
url:
http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.song.playAAC&format=jsonp&songid=242078437&from=web-
请求体
-
Referer:
http://music.taihe.com/song/242078437 -
User-Agent
-
-
目标数据
-
下载链接
-
歌词链接
-
-
-
url:
http://music.taihe.com/mv/601422013-
目标数据
-
mv的id
song_mv_id
-
-
-
url:
http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.mv.playMV&mv_id=XXXX-
说明
-
通过来源url,用正则表达式,解析出mv_id,需要注意的是数据库中的mv_id,可能提取的与目标mv_id是不相符的,如果用那个mv_id,可能提取不到数据
-
-
目标数据
-
下载mv的url
-
-
-
6.1 artist_total.py
-
代码
import requests
from lxml import etree
from qianqianyinyue.utils.mongo_pool import MongoPool
from qianqianyinyue.utils.random_useragent import random_user_agent
from qianqianyinyue.utils.log import logger
class ArtistTotal(object):
"""
预先执行的程序,获取该网站曲库,所有的音乐作者的信息
信息包括:
作者id: 对应数据库字段--->>>“author_tinguid”
作者的首页url:对应数据库字段--->>>“author_url”
作者的名字:对应数据库字段--->>>“author_name”
"""
def __init__(self):
self.mongo_pool = MongoPool(collection='artist')
self.url = "http://music.taihe.com/artist"
self.user_agent = random_user_agent
def get_response(self, url, user_agent):
headers = {
"User-Agent": user_agent
}
try:
response = requests.get(url=url, headers=headers)
if response.ok:
return response.content.decode()
except Exception as e:
logger.warning(e)
def parse_html_str(self, html_str):
html_str = etree.HTML(html_str)
b_li_list = html_str.xpath("//ul[@class="container"]/li[position()>1]")
for b_li in b_li_list:
s_li = b_li.xpath('./ul/li')
for li in s_li:
item = dict()
item["author_name"] = li.xpath('./a/@title')[0] if li.xpath('./a/@title') else None
author_url = "http://music.taihe.com"+li.xpath('./a/@href')[0] if li.xpath('./a/@href') else "-1"
item["author_url"] = author_url
item["author_tinguid"] = author_url.rsplit('/', 1)[-1]
yield item
def insert_to_mongodb(self, documents):
for document in documents:
self.mongo_pool.insert_one(document=document)
def run(self):
response = self.get_response(url=self.url, user_agent=self.user_agent)
author_infos = self.parse_html_str(html_str=response)
self.insert_to_mongodb(documents=author_infos)
if __name__ == "__main__":
obj =