今日内容:
二、内容:
1、生产者消费者模型补充


from multiprocessing import Process,Queue import time,random,os def producer(name,food,q): for i in range(3): res="%s%s"%(food,i) time.sleep(0.5) q.put(res) print("%s 生产了%s"%(name,res)) def consumer(name,q): while True: res=q.get() if res is None: break print("%s 吃 %s"%(name,res)) time.sleep(random.randint(2,3)) if __name__=="__main__": q=Queue() p1=Process(target=producer,args=("egon1","包子1",q,)) p2=Process(target=producer,args=("egon2","包子2",q,)) p3=Process(target=producer,args=("egon3","包子3",q,)) c1=Process(target=producer,args=("alex",q,)) c2=Process(target=producer,args=("wxx",q,)) p1.start() p2.start() p3.start() c1.start() c2.start() p1.join() p2.join() p3.join() q.put(None) q.put(None) print("主")
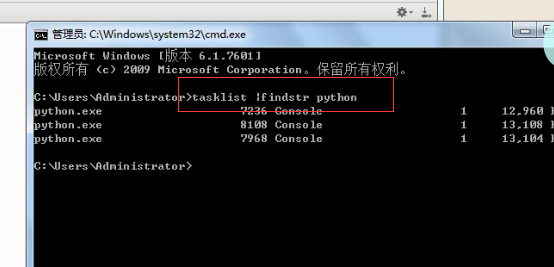
查看python进程
利用守护进程来实现 生产者和消费者模型
from multiprocessing import Process,Queue,JoinableQueue import time,random,os def producer(food,q): for i in range(3): res="%s%s"%(food,i) time.sleep(0.5) q.put(res) print("%s 生产了 %s"%(os.getpid(),res)) q.join() def consumer(q): while True: res=q.get() print("%s 吃 %s"%(os.getpid(),res)) time.sleep(random.randint(2,3)) q.task_done() if __name__=="__main__": q=JoinableQueue() p1=Process(target=producer,args=("包子",q,)) p2=Process(target=producer,args=("烤鸡",q,)) p3=Process(target=producer,args=("gouliang",q,)) c1=Process(target=consumer,args=(q,)) c2=Process(target=consumer,args=(q,)) c1.daemon=True c2.daemon=True p1.start() p2.start() p3.start() c1.start() c2.start() p1.join() p2.join() p3.join() #生产者结束--->q.join()--->消费者确实把所有的数据都收到 print('主', os.getpid())
2、GIL解释器锁(就是一把互斥锁)
(1)互斥锁就是为了保护数据
(2)Cpython解释器中,统一进程下来气的多线程,统一时刻只能有一个线程执行,无法使用多核优势
(3)8个线程可以被8个cpu执行,可以有两个进程,每个进程里面有四个线程,同一时间只能有一个线程被执行
(4)pyhton的多线程没办法用到多核优势木业没有办法用到并行,但是可以用到并发
(5)多核(cpu)的优势:运行快,计算快,cpu的功能是计算,遇到I/O没有什么用处
(6)python的多线程有什么特点(重要)
1、cpython的解释器由于GIL解释器锁的存在,导致基于cpython解释器写出来的多线程
统一时间只能有一个线程出来运行,不能用上多核优势
2、多核带来了什么好处?计算速度快,遇到I/O多核没有什么用处
(7)开进程开销大,开进程对于多核优势没有什么用处
解释:
(1)在python中所有的数据都是共享的
(2)python解释器只是一个软件,给你提供代码的运行解释并执行
(3)假如线程可以利用多核优势:
1、垃圾回收线程就会与其他的线程产生矛盾(因为是并行运行,垃圾回收线程机制就不会有用处)
2、垃圾回收机制是Python解释器的优势相对于其他的语言
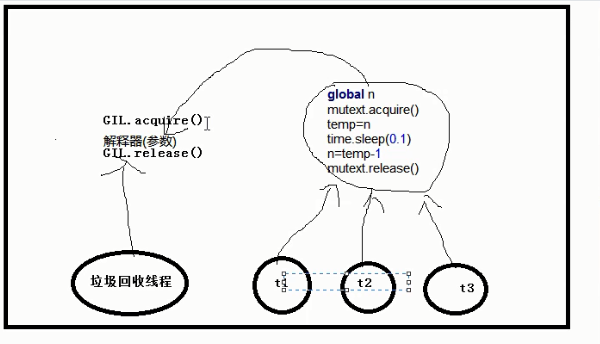
3、GIL全局解释器锁
(1)用锁的目的是为了让局部串行,其余的还是并发执行
(2)GIL锁是保护垃圾回收机制有关的解释器的数据


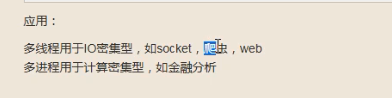
4、多进程和多线程的应用场景
(1)python多进程用不到多核(纯I/O进程)

(2)python多进程中多核是有用的(对于多计算型)

(3)计算型
线程要比进程花费时间长(线程不能串行,可以并发执行 来回切换)
#计算密集型 from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(10000000): res*=1 if __name__=="__main__": l=[] print(os.cpu_count()) #本机为四核 start=time.time() for i in range(4): # p=Process(target=work) #耗时为run time is 2.872164249420166 p=Thread(target=work) #耗时为run time is 6.84939169883728 l.append(p) p.start() for p in l: p.join() stop=time.time() print("run time is %s"%(stop-start))
(4)I/O型,线程要比进程花费时间短(进程的开销大)
5、死锁现象与递归锁
(1)死锁
(2)递归锁(解决死锁的方式)
import time mutexA=mutexB=RLock() # mutexA=mutexB=Lock() class Mythread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print("%s 拿到A锁"%self.name) mutexB.acquire() print("%s 拿到B锁"%self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print("%s 拿到B锁"%self.name) time.sleep(0.1) mutexA.acquire() print("%s 拿到A锁"%self.name) mutexA.release() mutexB.release() if __name__=="__main__": for i in range(10): t=Mythread() t.start()
6、协程
(1)单线程下实现并发叫协程
(2)只有遇到I/O切了才有意义(提升效率)
(3)要实现单线程情况下的并发 要本着
1、串行执行(没有切换,创建列表会有开销 可以忽略不计,数据UI越大 超过一定范围之后,
列表的开销会增大)
import time def consumer(res): """任务1:接收数据,处理数据""" pass def producer(): """任务2:生产数据""" res=[] for i in range(100000): res.append(i) return res start=time.time() #串行执行 res=producer() consumer(res) stop=time.time() print(stop-start)
import time def consumer(): """任务1:接收数据,处理数据""" while True: x=yield print("consumer") def producer(): """任务2:生产数据""" g=consumer() next(g) for i in range(10000): print("producer") time.sleep(6) g.send(i) start=time.time() #基于yield保存状态,实现两个任务直接来回切换,即并发的效果 #ps :如果每个任务中都加上打印,那么明显看到两个任务的打印是你一次我一次 #即并发执行的 producer() stop=time.time() print(stop-start)
7、gevent模块 (明天讲)